 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyberGFM: Graph Foundation Models for Lateral Movement Detection in Enterprise Networks
Jan 09, 2026Representing networks as a graph and training a link prediction model using benign connections is an effective method of anomaly-based intrusion detection. Existing works using this technique have shown great success using temporal graph neural networks and skip-gram-based approaches on random walks. However, random walk-based approaches are unable to incorporate rich edge data, while the GNN-based approaches require large amounts of memory to train. In this work, we propose extending the original insight from random walk-based skip-grams--that random walks through a graph are analogous to sentences in a corpus--to the more modern transformer-based foundation models. Using language models that take advantage of GPU optimizations, we can quickly train a graph foundation model to predict missing tokens in random walks through a network of computers. The graph foundation model is then finetuned for link prediction and used as a network anomaly detector. This new approach allows us to combine the efficiency of random walk-based methods and the rich semantic representation of deep learning methods. This system, which we call CyberGFM, achieved state-of-the-art results on three widely used network anomaly detection datasets, delivering a up to 2$\times$ improvement in average precision. We found that CyberGFM outperforms all prior works in unsupervised link prediction for network anomaly detection, using the same number of parameters, and with equal or better efficiency than the previous best approaches.
Automated Cyber Defense with Generalizable Graph-based Reinforcement Learning Agents
Sep 19, 2025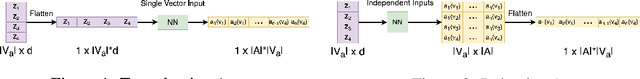

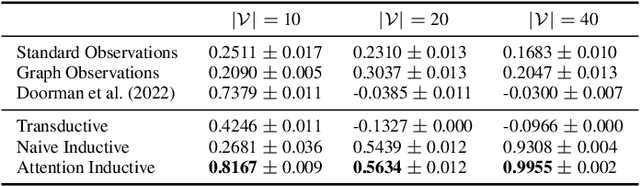
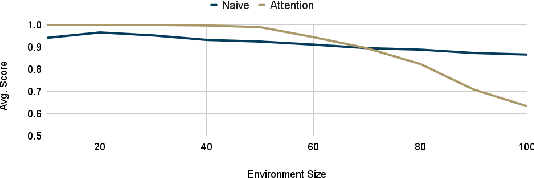
Deep reinforcement learning (RL) is emerging as a viable strategy for automated cyber defense (ACD). The traditional RL approach represents networks as a list of computers in various states of safety or threat. Unfortunately, these models are forced to overfit to specific network topologies, rendering them ineffective when faced with even small environmental perturbations. In this work, we frame ACD as a two-player context-based partially observable Markov decision problem with observations represented as attributed graphs. This approach allows our agents to reason through the lens of relational inductive bias. Agents learn how to reason about hosts interacting with other system entities in a more general manner, and their actions are understood as edits to the graph representing the environment. By introducing this bias, we will show that our agents can better reason about the states of networks and zero-shot adapt to new ones. We show that this approach outperforms the state-of-the-art by a wide margin, and makes our agents capable of defending never-before-seen networks against a wide range of adversaries in a variety of complex, and multi-agent environments.
Estimating Semantic Alphabet Size for LLM Uncertainty Quantification
Sep 17, 2025Many black-box techniques for quantifying the uncertainty of large language models (LLMs) rely on repeated LLM sampling, which can be computationally expensive. Therefore, practical applicability demands reliable estimation from few samples. Semantic entropy (SE) is a popular sample-based uncertainty estimator with a discrete formulation attractive for the black-box setting. Recent extensions of semantic entropy exhibit improved LLM hallucination detection, but do so with less interpretable methods that admit additional hyperparameters. For this reason, we revisit the canonical discrete semantic entropy estimator, finding that it underestimates the "true" semantic entropy, as expected from theory. We propose a modified semantic alphabet size estimator, and illustrate that using it to adjust discrete semantic entropy for sample coverage results in more accurate semantic entropy estimation in our setting of interest. Furthermore, our proposed alphabet size estimator flags incorrect LLM responses as well or better than recent top-performing approaches, with the added benefit of remaining highly interpretable.
Predicting Movie Hits Before They Happen with LLMs
May 05, 2025Addressing the cold-start issue in content recommendation remains a critical ongoing challenge. In this work, we focus on tackling the cold-start problem for movies on a large entertainment platform. Our primary goal is to forecast the popularity of cold-start movies using Large Language Models (LLMs) leveraging movie metadata. This method could be integrated into retrieval systems within the personalization pipeline or could be adopted as a tool for editorial teams to ensure fair promotion of potentially overlooked movies that may be missed by traditional or algorithmic solutions. Our study validates the effectiveness of this approach compared to established baselines and those we developed.
Demystifying optimized prompts in language models
May 04, 2025Modern language models (LMs) are not robust to out-of-distribution inputs. Machine generated (``optimized'') prompts can be used to modulate LM outputs and induce specific behaviors while appearing completely uninterpretable. In this work, we investigate the composition of optimized prompts, as well as the mechanisms by which LMs parse and build predictions from optimized prompts. We find that optimized prompts primarily consist of punctuation and noun tokens which are more rare in the training data. Internally, optimized prompts are clearly distinguishable from natural language counterparts based on sparse subsets of the model's activations. Across various families of instruction-tuned models, optimized prompts follow a similar path in how their representations form through the network.
Causal Reasoning in Large Language Models: A Knowledge Graph Approach
Oct 15, 2024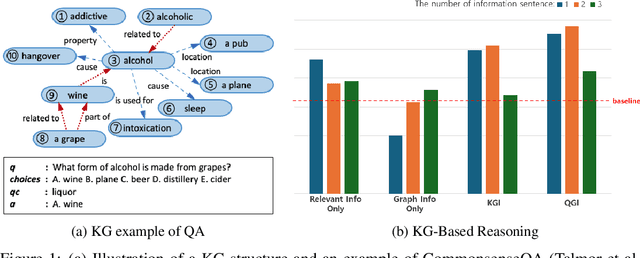
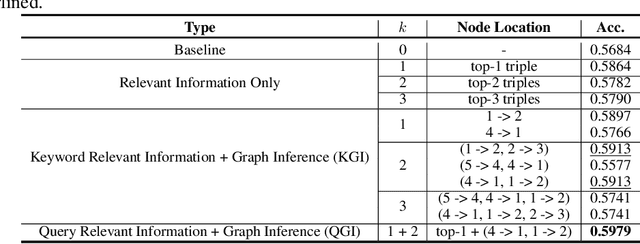

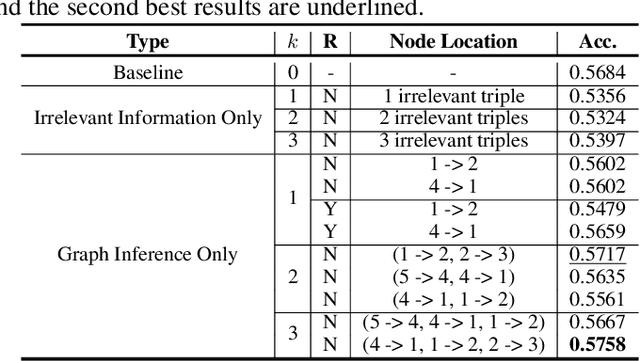
Large language models (LLMs) typically improve performance by either retrieving semantically similar information, or enhancing reasoning abilities through structured prompts like chain-of-thought. While both strategies are considered crucial, it remains unclear which has a greater impact on model performance or whether a combination of both is necessary. This paper answers this question by proposing a knowledge graph (KG)-based random-walk reasoning approach that leverages causal relationships. We conduct experiments on the commonsense question answering task that is based on a KG. The KG inherently provides both relevant information, such as related entity keywords, and a reasoning structure through the connections between nodes. Experimental results show that the proposed KG-based random-walk reasoning method improves the reasoning ability and performance of LLMs. Interestingly, incorporating three seemingly irrelevant sentences into the query using KG-based random-walk reasoning enhances LLM performance, contrary to conventional wisdom. These findings suggest that integrating causal structures into prompts can significantly improve reasoning capabilities, providing new insights into the role of causality in optimizing LLM performance.
Improving Content Recommendation: Knowledge Graph-Based Semantic Contrastive Learning for Diversity and Cold-Start Users
Mar 27, 2024Addressing the challenges related to data sparsity, cold-start problems, and diversity in recommendation systems is both crucial and demanding. Many current solutions leverage knowledge graphs to tackle these issues by combining both item-based and user-item collaborative signals. A common trend in these approaches focuses on improving ranking performance at the cost of escalating model complexity, reducing diversity, and complicating the task. It is essential to provide recommendations that are both personalized and diverse, rather than solely relying on achieving high rank-based performance, such as Click-through Rate, Recall, etc. In this paper, we propose a hybrid multi-task learning approach, training on user-item and item-item interactions. We apply item-based contrastive learning on descriptive text, sampling positive and negative pairs based on item metadata. Our approach allows the model to better understand the relationships between entities within the knowledge graph by utilizing semantic information from text. It leads to more accurate, relevant, and diverse user recommendations and a benefit that extends even to cold-start users who have few interactions with items. We perform extensive experiments on two widely used datasets to validate the effectiveness of our approach. Our findings demonstrate that jointly training user-item interactions and item-based signals using synopsis text is highly effective. Furthermore, our results provide evidence that item-based contrastive learning enhances the quality of entity embeddings, as indicated by metrics such as uniformity and alignment.
PROPANE: Prompt design as an inverse problem
Nov 13, 2023
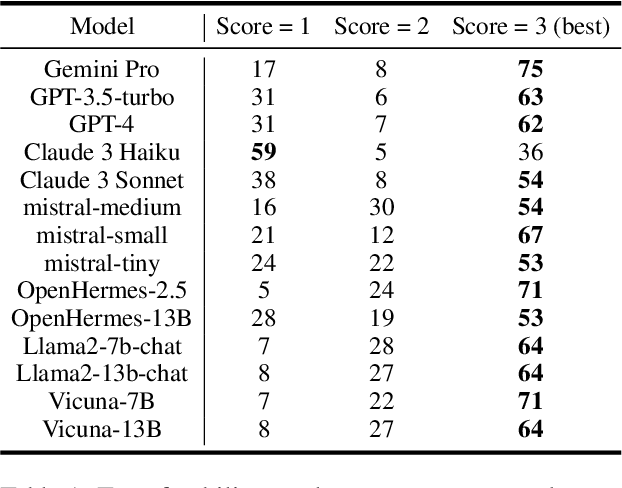
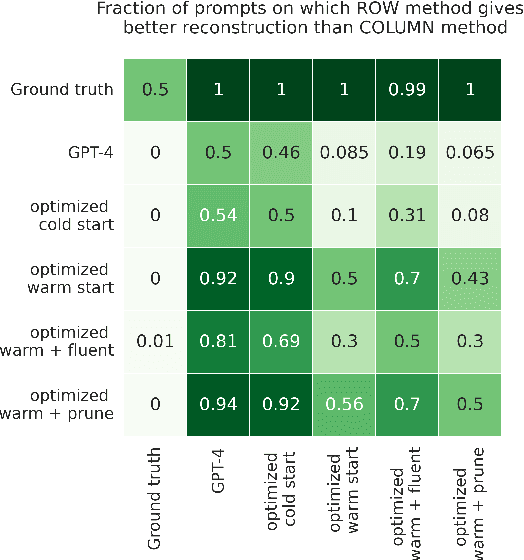
Carefully-designed prompts are key to inducing desired behavior in Large Language Models (LLMs). As a result, great effort has been dedicated to engineering prompts that guide LLMs toward particular behaviors. In this work, we propose an automatic prompt optimization framework, PROPANE, which aims to find a prompt that induces semantically similar outputs to a fixed set of examples without user intervention. We further demonstrate that PROPANE can be used to (a) improve existing prompts, and (b) discover semantically obfuscated prompts that transfer between models.
Illuminati: Towards Explaining Graph Neural Networks for Cybersecurity Analysis
Mar 26, 2023



Graph neural networks (GNNs) have been utilized to create multi-layer graph models for a number of cybersecurity applications from fraud detection to software vulnerability analysis. Unfortunately, like traditional neural networks, GNNs also suffer from a lack of transparency, that is, it is challenging to interpret the model predictions. Prior works focused on specific factor explanations for a GNN model. In this work, we have designed and implemented Illuminati, a comprehensive and accurate explanation framework for cybersecurity applications using GNN models. Given a graph and a pre-trained GNN model, Illuminati is able to identify the important nodes, edges, and attributes that are contributing to the prediction while requiring no prior knowledge of GNN models. We evaluate Illuminati in two cybersecurity applications, i.e., code vulnerability detection and smart contract vulnerability detection. The experiments show that Illuminati achieves more accurate explanation results than state-of-the-art methods, specifically, 87.6% of subgraphs identified by Illuminati are able to retain their original prediction, an improvement of 10.3% over others at 77.3%. Furthermore, the explanation of Illuminati can be easily understood by the domain experts, suggesting the significant usefulness for the development of cybersecurity applications.
Don't Judge a Language Model by Its Last Layer: Contrastive Learning with Layer-Wise Attention Pooling
Sep 13, 2022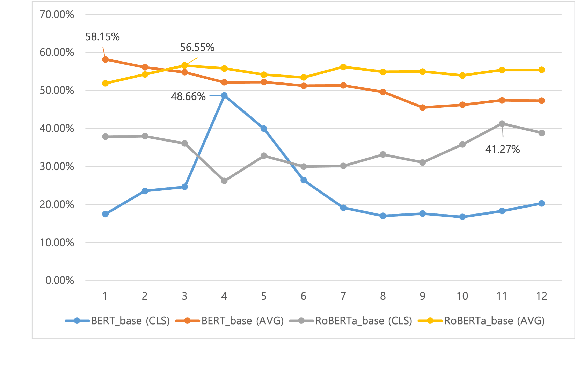
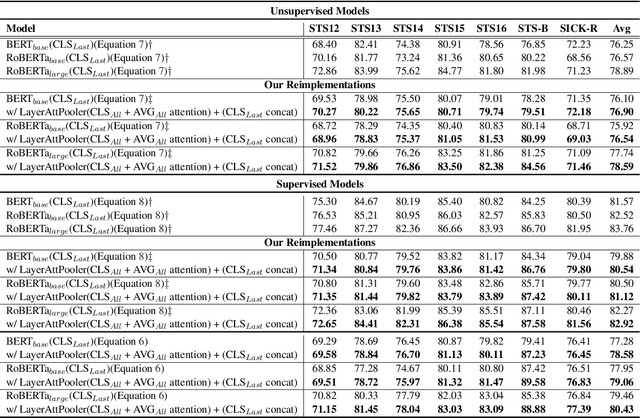
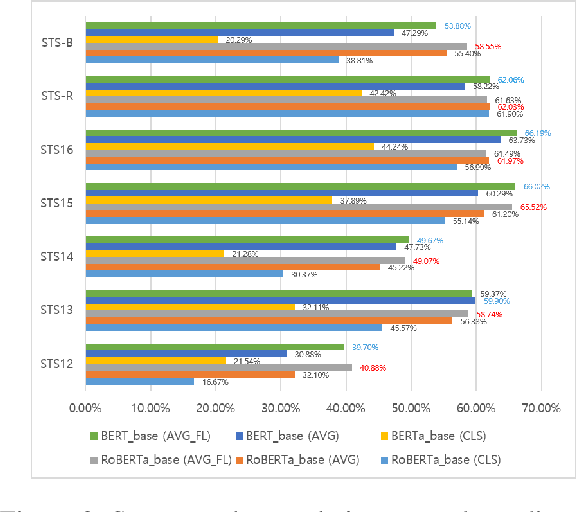

Recent pre-trained language models (PLMs) achieved great success on many natural language processing tasks through learning linguistic features and contextualized sentence representation. Since attributes captured in stacked layers of PLMs are not clearly identified, straightforward approaches such as embedding the last layer are commonly preferred to derive sentence representations from PLMs. This paper introduces the attention-based pooling strategy, which enables the model to preserve layer-wise signals captured in each layer and learn digested linguistic features for downstream tasks. The contrastive learning objective can adapt the layer-wise attention pooling to both unsupervised and supervised manners. It results in regularizing the anisotropic space of pre-trained embeddings and being more uniform. We evaluate our model on standard semantic textual similarity (STS) and semantic search tasks. As a result, our method improved the performance of the base contrastive learned BERT_base and variants.