 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKC-3DGS: Kurtosis-Constrained Gaussian Splatting for High-Fidelity View Synthesis
Jun 02, 20263D Gaussian Splatting (3DGS) enables real-time novel view synthesis by representing scenes as collections of anisotropic Gaussians optimized via differentiable rasterization. However, standard pixel-space losses (L1, SSIM) constrain only aggregate reconstruction error, permitting the optimization to redistribute error across frequency scales. This leads to oversmoothing and structural artifacts, particularly in sparse-view settings where supervision is limited. We propose KC-3DGS, which augments 3DGS training with wavelet-domain supervision based on natural image statistics. Our method combines three components: (1) a multi-scale wavelet coefficient alignment loss that explicitly penalizes missing high-frequency detail, (2) a supervised kurtosis concentration loss that encourages rendered images to match the heavy-tailed frequency statistics of ground-truth images, and (3) a cross-band covariance penalty that promotes frequency specialization. We provide theoretical analysis showing that pixel-space losses admit a family of indistinguishable perturbations under wavelet redistribution, and that our joint objective excludes degenerate solutions. Experiments across MipNeRF360, Tanks&Temples, MVImgNet, DeepBlending, and WRIVA-ULTRRA demonstrate consistent improvements in perceptual quality. On the challenging WRIVA-ULTRRA outdoor dataset, KC-3DGS achieves a 9.48% improvement in DreamSim while also improving PSNR, SSIM, and LPIPS. In sparse-view settings with only 12 training images, our method improves PSNR by up to 0.5 dB on MipNeRF360 while maintaining perceptual quality. The approach integrates seamlessly into existing 3DGS pipelines as a plug-and-play regularization strategy.
Understanding and Improving Noisy Embedding Techniques in Instruction Finetuning
May 22, 2026Recent advancements in instructional fine-tuning have injected noise into embeddings, with NEFTune (Jain et al., 2024) setting benchmarks using uniform noise. Despite NEFTune's empirical findings that uniform noise outperforms Gaussian noise, the reasons for this remain unclear. This paper aims to clarify this by offering a thorough analysis, both theoretical and empirical, indicating comparable performance among these noise types. Additionally, we introduce a new fine-tuning method for language models, utilizing symmetric noise in embeddings. This method aims to enhance the model's function by more stringently regulating its local curvature, demonstrating superior performance over the current method, NEFTune. When fine-tuning the LLaMA-2-7B model using Alpaca, standard techniques yield a 29.79% score on AlpacaEval. However, our approach, SymNoise, increases this score significantly to 69.04%, using symmetric noisy embeddings. This is a 6.7% improvement over the state-of-the-art method, NEFTune (64.69%). Furthermore, when tested on various models and stronger baseline instruction datasets, such as Evol-Instruct, ShareGPT, OpenPlatypus, SymNoise consistently outperforms NEFTune. The current literature, including NEFTune, has underscored the importance of more in-depth research into the application of noise-based strategies in the fine-tuning of language models. Our approach, SymNoise, is another significant step towards this direction, showing notable improvement over the existing state-of-the-art method.
* arXiv admin note: substantial text overlap with arXiv:2312.01523
SyncFix: Fixing 3D Reconstructions via Multi-View Synchronization
Apr 13, 2026We present SyncFix, a framework that enforces cross-view consistency during the diffusion-based refinement of reconstructed scenes. SyncFix formulates refinement as a joint latent bridge matching problem, synchronizing distorted and clean representations across multiple views to fix the semantic and geometric inconsistencies. This means SyncFix learns a joint conditional over multiple views to enforce consistency throughout the denoising trajectory. Our training is done only on image pairs, but it generalizes naturally to an arbitrary number of views during inference. Moreover, reconstruction quality improves with additional views, with diminishing returns at higher view counts. Qualitative and quantitative results demonstrate that SyncFix consistently generates high-quality reconstructions and surpasses current state-of-the-art baselines, even in the absence of clean reference images. SyncFix achieves even higher fidelity when sparse references are available.
CAM3R: Camera-Agnostic Model for 3D Reconstruction
Mar 23, 2026Recovering dense 3D geometry from unposed images remains a foundational challenge in computer vision. Current state-of-the-art models are predominantly trained on perspective datasets, which implicitly constrains them to a standard pinhole camera geometry. As a result, these models suffer from significant geometric degradation when applied to wide-angle imagery captured via non-rectilinear optics, such as fisheye or panoramic sensors. To address this, we present CAM3R, a Camera-Agnostic, feed-forward Model for 3D Reconstruction capable of processing images from wide-angle camera models without prior calibration. Our framework consists of a two-view network which is bifurcated into a Ray Module (RM) to estimate per-pixel ray directions and a Cross-view Module (CVM) to infer radial distance with confidence maps, pointmaps, and relative poses. To unify these pairwise predictions into a consistent 3D scene, we introduce a Ray-Aware Global Alignment framework for pose refinement and scale optimization while strictly preserving the predicted local geometry. Extensive experiments on various camera model datasets, including panorama, fisheye and pinhole imagery, demonstrate that CAM3R establishes a new state-of-the-art in pose estimation and reconstruction.
Wrivinder: Towards Spatial Intelligence for Geo-locating Ground Images onto Satellite Imagery
Feb 16, 2026Aligning ground-level imagery with geo-registered satellite maps is crucial for mapping, navigation, and situational awareness, yet remains challenging under large viewpoint gaps or when GPS is unreliable. We introduce Wrivinder, a zero-shot, geometry-driven framework that aggregates multiple ground photographs to reconstruct a consistent 3D scene and align it with overhead satellite imagery. Wrivinder combines SfM reconstruction, 3D Gaussian Splatting, semantic grounding, and monocular depth--based metric cues to produce a stable zenith-view rendering that can be directly matched to satellite context for metrically accurate camera geo-localization. To support systematic evaluation of this task, which lacks suitable benchmarks, we also release MC-Sat, a curated dataset linking multi-view ground imagery with geo-registered satellite tiles across diverse outdoor environments. Together, Wrivinder and MC-Sat provide a first comprehensive baseline and testbed for studying geometry-centered cross-view alignment without paired supervision. In zero-shot experiments, Wrivinder achieves sub-30\,m geolocation accuracy across both dense and large-area scenes, highlighting the promise of geometry-based aggregation for robust ground-to-satellite localization.
Improving Content Recommendation: Knowledge Graph-Based Semantic Contrastive Learning for Diversity and Cold-Start Users
Mar 27, 2024Addressing the challenges related to data sparsity, cold-start problems, and diversity in recommendation systems is both crucial and demanding. Many current solutions leverage knowledge graphs to tackle these issues by combining both item-based and user-item collaborative signals. A common trend in these approaches focuses on improving ranking performance at the cost of escalating model complexity, reducing diversity, and complicating the task. It is essential to provide recommendations that are both personalized and diverse, rather than solely relying on achieving high rank-based performance, such as Click-through Rate, Recall, etc. In this paper, we propose a hybrid multi-task learning approach, training on user-item and item-item interactions. We apply item-based contrastive learning on descriptive text, sampling positive and negative pairs based on item metadata. Our approach allows the model to better understand the relationships between entities within the knowledge graph by utilizing semantic information from text. It leads to more accurate, relevant, and diverse user recommendations and a benefit that extends even to cold-start users who have few interactions with items. We perform extensive experiments on two widely used datasets to validate the effectiveness of our approach. Our findings demonstrate that jointly training user-item interactions and item-based signals using synopsis text is highly effective. Furthermore, our results provide evidence that item-based contrastive learning enhances the quality of entity embeddings, as indicated by metrics such as uniformity and alignment.
On the Similarity between the Laplace and Neural Tangent Kernels
Jul 03, 2020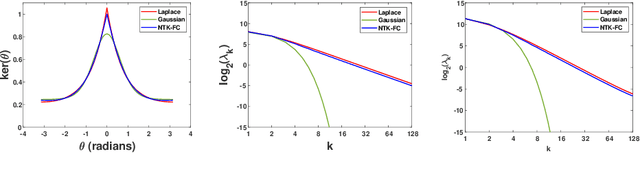
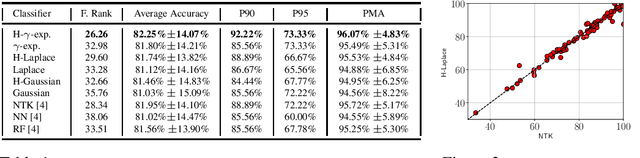
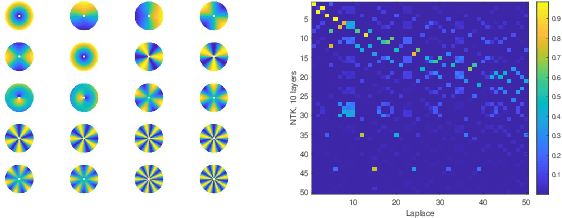

Recent theoretical work has shown that massively overparameterized neural networks are equivalent to kernel regressors that use Neural Tangent Kernels(NTK). Experiments show that these kernel methods perform similarly to real neural networks. Here we show that NTK for fully connected networks is closely related to the standard Laplace kernel. We show theoretically that for normalized data on the hypersphere both kernels have the same eigenfunctions and their eigenvalues decay polynomially at the same rate, implying that their Reproducing Kernel Hilbert Spaces (RKHS) include the same sets of functions. This means that both kernels give rise to classes of functions with the same smoothness properties. The two kernels differ for data off the hypersphere, but experiments indicate that when data is properly normalized these differences are not significant. Finally, we provide experiments on real data comparing NTK and the Laplace kernel, along with a larger class of{\gamma}-exponential kernels. We show that these perform almost identically. Our results suggest that much insight about neural networks can be obtained from analysis of the well-known Laplace kernel, which has a simple closed-form.
Stabilizing Adversarial Nets With Prediction Methods
Feb 08, 2018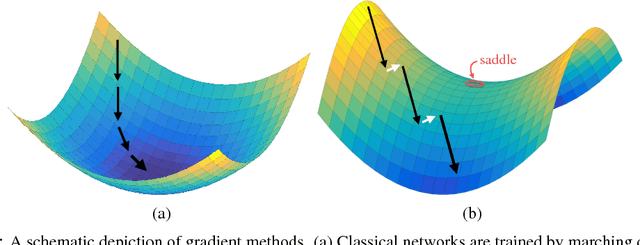

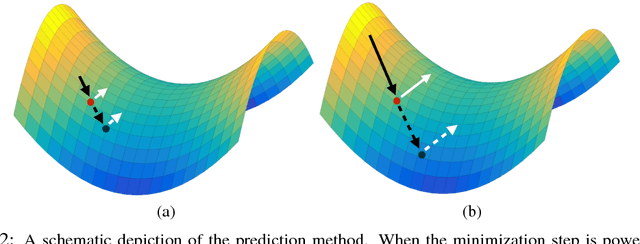

Adversarial neural networks solve many important problems in data science, but are notoriously difficult to train. These difficulties come from the fact that optimal weights for adversarial nets correspond to saddle points, and not minimizers, of the loss function. The alternating stochastic gradient methods typically used for such problems do not reliably converge to saddle points, and when convergence does happen it is often highly sensitive to learning rates. We propose a simple modification of stochastic gradient descent that stabilizes adversarial networks. We show, both in theory and practice, that the proposed method reliably converges to saddle points, and is stable with a wider range of training parameters than a non-prediction method. This makes adversarial networks less likely to "collapse," and enables faster training with larger learning rates.
Big Batch SGD: Automated Inference using Adaptive Batch Sizes
Apr 06, 2017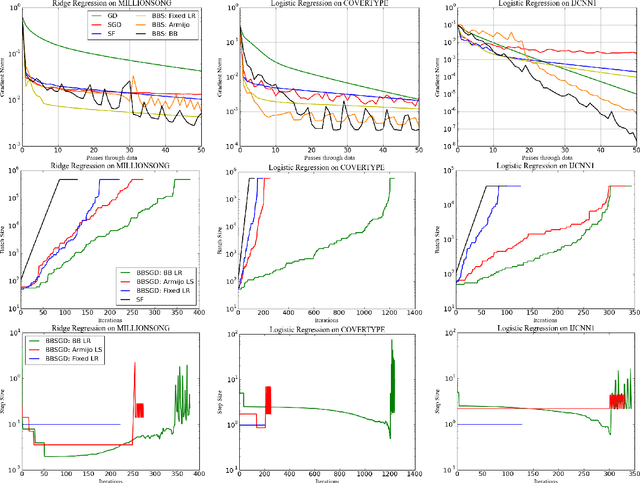

Classical stochastic gradient methods for optimization rely on noisy gradient approximations that become progressively less accurate as iterates approach a solution. The large noise and small signal in the resulting gradients makes it difficult to use them for adaptive stepsize selection and automatic stopping. We propose alternative "big batch" SGD schemes that adaptively grow the batch size over time to maintain a nearly constant signal-to-noise ratio in the gradient approximation. The resulting methods have similar convergence rates to classical SGD, and do not require convexity of the objective. The high fidelity gradients enable automated learning rate selection and do not require stepsize decay. Big batch methods are thus easily automated and can run with little or no oversight.