 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast 4D Mesh Generation by Spatio-Temporal Attention Chains
May 19, 20264D mesh generation has recently emerged as a powerful paradigm for recovering dynamic 3D structure from videos, but existing methods remain slow, computationally expensive, and difficult to scale to longer sequences. We introduce a training-free approach that accelerates 4D mesh generation while improving temporal correspondence quality. Our key observation is that temporal correspondences emerge inside a 4D backbone long before its generated meshes become visually accurate. We exploit this with a general framework we call Spatio-Temporal Attention Chain which propagates information across space and time. Starting from vertices on an anchor mesh, the chain maps vertices to latent tokens. It then follows temporal correspondences in latent space, and recovers frame-specific vertices through latent-to-vertex attention. This design avoids expensive explicit matching while preserving anchor mesh details and thereby improving dynamic mesh geometry and temporal consistency. Compared to state-of-the-art, our method generates a 4D mesh in 9 seconds, achieving a $13\times$ speedup while producing higher-quality results. Moreover, our approach scales to videos up to $16\times$ longer without degrading mesh quality. Beyond generation, the improved correspondences enable competitive zero-shot performance on two downstream tasks: 2D object tracking and 4D tracking. We further show that our framework enables reliable camera estimation, a capability not supported by prior 4D mesh generation methods.
Lost in Space? Vision-Language Models Struggle with Relative Camera Pose Estimation
Jan 29, 2026Vision-Language Models (VLMs) perform well in 2D perception and semantic reasoning compared to their limited understanding of 3D spatial structure. We investigate this gap using relative camera pose estimation (RCPE), a fundamental vision task that requires inferring relative camera translation and rotation from a pair of images. We introduce VRRPI-Bench, a benchmark derived from unlabeled egocentric videos with verbalized annotations of relative camera motion, reflecting realistic scenarios with simultaneous translation and rotation around a shared object. We further propose VRRPI-Diag, a diagnostic benchmark that isolates individual motion degrees of freedom. Despite the simplicity of RCPE, most VLMs fail to generalize beyond shallow 2D heuristics, particularly for depth changes and roll transformations along the optical axis. Even state-of-the-art models such as GPT-5 ($0.64$) fall short of classic geometric baselines ($0.97$) and human performance ($0.92$). Moreover, VLMs exhibit difficulty in multi-image reasoning, with inconsistent performance (best $59.7\%$) when integrating spatial cues across frames. Our findings reveal limitations in grounding VLMs in 3D and multi-view spatial reasoning.
GSVisLoc: Generalizable Visual Localization for Gaussian Splatting Scene Representations
Aug 25, 2025We introduce GSVisLoc, a visual localization method designed for 3D Gaussian Splatting (3DGS) scene representations. Given a 3DGS model of a scene and a query image, our goal is to estimate the camera's position and orientation. We accomplish this by robustly matching scene features to image features. Scene features are produced by downsampling and encoding the 3D Gaussians while image features are obtained by encoding image patches. Our algorithm proceeds in three steps, starting with coarse matching, then fine matching, and finally by applying pose refinement for an accurate final estimate. Importantly, our method leverages the explicit 3DGS scene representation for visual localization without requiring modifications, retraining, or additional reference images. We evaluate GSVisLoc on both indoor and outdoor scenes, demonstrating competitive localization performance on standard benchmarks while outperforming existing 3DGS-based baselines. Moreover, our approach generalizes effectively to novel scenes without additional training.
TriTex: Learning Texture from a Single Mesh via Triplane Semantic Features
Mar 20, 2025As 3D content creation continues to grow, transferring semantic textures between 3D meshes remains a significant challenge in computer graphics. While recent methods leverage text-to-image diffusion models for texturing, they often struggle to preserve the appearance of the source texture during texture transfer. We present \ourmethod, a novel approach that learns a volumetric texture field from a single textured mesh by mapping semantic features to surface colors. Using an efficient triplane-based architecture, our method enables semantic-aware texture transfer to a novel target mesh. Despite training on just one example, it generalizes effectively to diverse shapes within the same category. Extensive evaluation on our newly created benchmark dataset shows that \ourmethod{} achieves superior texture transfer quality and fast inference times compared to existing methods. Our approach advances single-example texture transfer, providing a practical solution for maintaining visual coherence across related 3D models in applications like game development and simulation.
Multi-Shot Character Consistency for Text-to-Video Generation
Dec 10, 2024

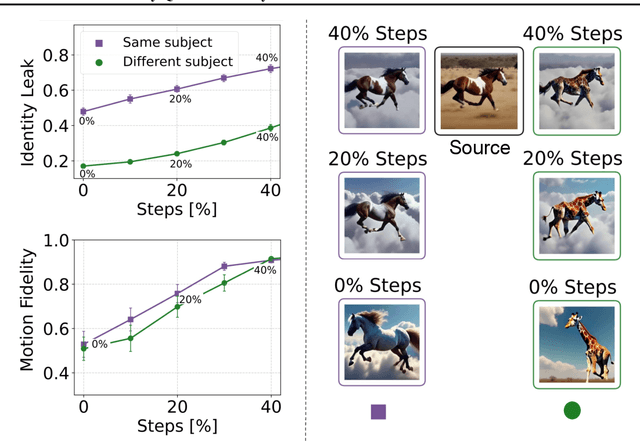

Text-to-video models have made significant strides in generating short video clips from textual descriptions. Yet, a significant challenge remains: generating several video shots of the same characters, preserving their identity without hurting video quality, dynamics, and responsiveness to text prompts. We present Video Storyboarding, a training-free method to enable pretrained text-to-video models to generate multiple shots with consistent characters, by sharing features between them. Our key insight is that self-attention query features (Q) encode both motion and identity. This creates a hard-to-avoid trade-off between preserving character identity and making videos dynamic, when features are shared. To address this issue, we introduce a novel query injection strategy that balances identity preservation and natural motion retention. This approach improves upon naive consistency techniques applied to videos, which often struggle to maintain this delicate equilibrium. Our experiments demonstrate significant improvements in character consistency across scenes while maintaining high-quality motion and text alignment. These results offer insights into critical stages of video generation and the interplay of structure and motion in video diffusion models.
Lay-A-Scene: Personalized 3D Object Arrangement Using Text-to-Image Priors
Jun 04, 2024Generating 3D visual scenes is at the forefront of visual generative AI, but current 3D generation techniques struggle with generating scenes with multiple high-resolution objects. Here we introduce Lay-A-Scene, which solves the task of Open-set 3D Object Arrangement, effectively arranging unseen objects. Given a set of 3D objects, the task is to find a plausible arrangement of these objects in a scene. We address this task by leveraging pre-trained text-to-image models. We personalize the model and explain how to generate images of a scene that contains multiple predefined objects without neglecting any of them. Then, we describe how to infer the 3D poses and arrangement of objects from a 2D generated image by finding a consistent projection of objects onto the 2D scene. We evaluate the quality of Lay-A-Scene using 3D objects from Objaverse and human raters and find that it often generates coherent and feasible 3D object arrangements.
RESFM: Robust Equivariant Multiview Structure from Motion
Apr 22, 2024



Multiview Structure from Motion is a fundamental and challenging computer vision problem. A recent deep-based approach was proposed utilizing matrix equivariant architectures for the simultaneous recovery of camera pose and 3D scene structure from large image collections. This work however made the unrealistic assumption that the point tracks given as input are clean of outliers. Here we propose an architecture suited to dealing with outliers by adding an inlier/outlier classifying module that respects the model equivariance and by adding a robust bundle adjustment step. Experiments demonstrate that our method can be successfully applied in realistic settings that include large image collections and point tracks extracted with common heuristics and include many outliers.
Learning Priors for Non Rigid SfM from Casual Videos
Apr 10, 2024We tackle the long-standing challenge of reconstructing 3D structures and camera positions from videos. The problem is particularly hard when objects are transformed in a non-rigid way. Current approaches to this problem make unrealistic assumptions or require a long optimization time. We present TracksTo4D, a novel deep learning-based approach that enables inferring 3D structure and camera positions from dynamic content originating from in-the-wild videos using a single feed-forward pass on a sparse point track matrix. To achieve this, we leverage recent advances in 2D point tracking and design an equivariant neural architecture tailored for directly processing 2D point tracks by leveraging their symmetries. TracksTo4D is trained on a dataset of in-the-wild videos utilizing only the 2D point tracks extracted from the videos, without any 3D supervision. Our experiments demonstrate that TracksTo4D generalizes well to unseen videos of unseen semantic categories at inference time, producing equivalent results to state-of-the-art methods while significantly reducing the runtime compared to other baselines.
Training-Free Consistent Text-to-Image Generation
Feb 05, 2024Text-to-image models offer a new level of creative flexibility by allowing users to guide the image generation process through natural language. However, using these models to consistently portray the same subject across diverse prompts remains challenging. Existing approaches fine-tune the model to teach it new words that describe specific user-provided subjects or add image conditioning to the model. These methods require lengthy per-subject optimization or large-scale pre-training. Moreover, they struggle to align generated images with text prompts and face difficulties in portraying multiple subjects. Here, we present ConsiStory, a training-free approach that enables consistent subject generation by sharing the internal activations of the pretrained model. We introduce a subject-driven shared attention block and correspondence-based feature injection to promote subject consistency between images. Additionally, we develop strategies to encourage layout diversity while maintaining subject consistency. We compare ConsiStory to a range of baselines, and demonstrate state-of-the-art performance on subject consistency and text alignment, without requiring a single optimization step. Finally, ConsiStory can naturally extend to multi-subject scenarios, and even enable training-free personalization for common objects.
Space-Time Diffusion Features for Zero-Shot Text-Driven Motion Transfer
Dec 03, 2023
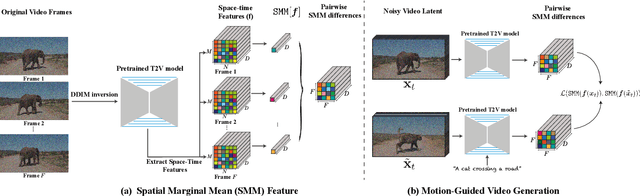


We present a new method for text-driven motion transfer - synthesizing a video that complies with an input text prompt describing the target objects and scene while maintaining an input video's motion and scene layout. Prior methods are confined to transferring motion across two subjects within the same or closely related object categories and are applicable for limited domains (e.g., humans). In this work, we consider a significantly more challenging setting in which the target and source objects differ drastically in shape and fine-grained motion characteristics (e.g., translating a jumping dog into a dolphin). To this end, we leverage a pre-trained and fixed text-to-video diffusion model, which provides us with generative and motion priors. The pillar of our method is a new space-time feature loss derived directly from the model. This loss guides the generation process to preserve the overall motion of the input video while complying with the target object in terms of shape and fine-grained motion traits.