 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynVFX: Augmenting Real Videos with Dynamic Content
Feb 05, 2025



We present a method for augmenting real-world videos with newly generated dynamic content. Given an input video and a simple user-provided text instruction describing the desired content, our method synthesizes dynamic objects or complex scene effects that naturally interact with the existing scene over time. The position, appearance, and motion of the new content are seamlessly integrated into the original footage while accounting for camera motion, occlusions, and interactions with other dynamic objects in the scene, resulting in a cohesive and realistic output video. We achieve this via a zero-shot, training-free framework that harnesses a pre-trained text-to-video diffusion transformer to synthesize the new content and a pre-trained Vision Language Model to envision the augmented scene in detail. Specifically, we introduce a novel inference-based method that manipulates features within the attention mechanism, enabling accurate localization and seamless integration of the new content while preserving the integrity of the original scene. Our method is fully automated, requiring only a simple user instruction. We demonstrate its effectiveness on a wide range of edits applied to real-world videos, encompassing diverse objects and scenarios involving both camera and object motion.
Space-Time Diffusion Features for Zero-Shot Text-Driven Motion Transfer
Dec 03, 2023
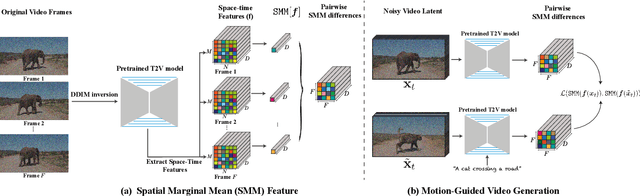


We present a new method for text-driven motion transfer - synthesizing a video that complies with an input text prompt describing the target objects and scene while maintaining an input video's motion and scene layout. Prior methods are confined to transferring motion across two subjects within the same or closely related object categories and are applicable for limited domains (e.g., humans). In this work, we consider a significantly more challenging setting in which the target and source objects differ drastically in shape and fine-grained motion characteristics (e.g., translating a jumping dog into a dolphin). To this end, we leverage a pre-trained and fixed text-to-video diffusion model, which provides us with generative and motion priors. The pillar of our method is a new space-time feature loss derived directly from the model. This loss guides the generation process to preserve the overall motion of the input video while complying with the target object in terms of shape and fine-grained motion traits.