 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's in the Image? A Deep-Dive into the Vision of Vision Language Models
Nov 26, 2024



Vision-Language Models (VLMs) have recently demonstrated remarkable capabilities in comprehending complex visual content. However, the mechanisms underlying how VLMs process visual information remain largely unexplored. In this paper, we conduct a thorough empirical analysis, focusing on attention modules across layers. We reveal several key insights about how these models process visual data: (i) the internal representation of the query tokens (e.g., representations of "describe the image"), is utilized by VLMs to store global image information; we demonstrate that these models generate surprisingly descriptive responses solely from these tokens, without direct access to image tokens. (ii) Cross-modal information flow is predominantly influenced by the middle layers (approximately 25% of all layers), while early and late layers contribute only marginally.(iii) Fine-grained visual attributes and object details are directly extracted from image tokens in a spatially localized manner, i.e., the generated tokens associated with a specific object or attribute attend strongly to their corresponding regions in the image. We propose novel quantitative evaluation to validate our observations, leveraging real-world complex visual scenes. Finally, we demonstrate the potential of our findings in facilitating efficient visual processing in state-of-the-art VLMs.
Algorithm Selection for Optimal Multi-Agent Path Finding via Graph Embedding
Jun 16, 2024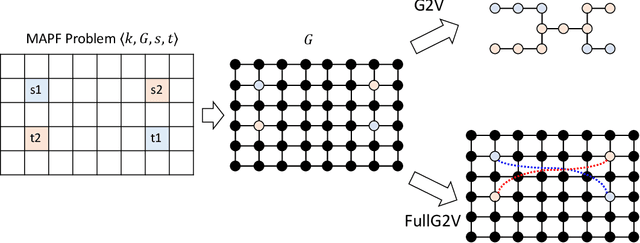
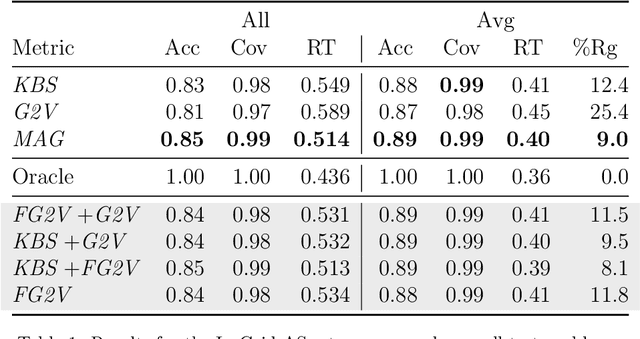
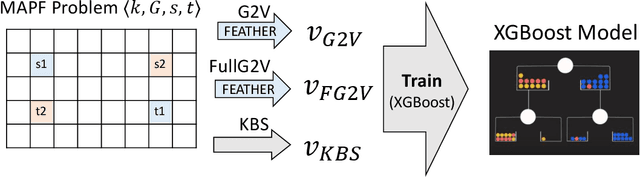
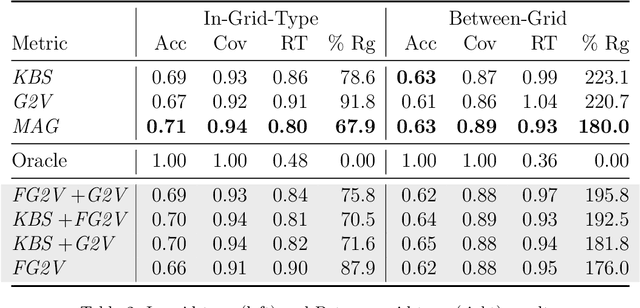
Multi-agent path finding (MAPF) is the problem of finding paths for multiple agents such that they do not collide. This problem manifests in numerous real-world applications such as controlling transportation robots in automated warehouses, moving characters in video games, and coordinating self-driving cars in intersections. Finding optimal solutions to MAPF is NP-Hard, yet modern optimal solvers can scale to hundreds of agents and even thousands in some cases. Different solvers employ different approaches, and there is no single state-of-the-art approach for all problems. Furthermore, there are no clear, provable, guidelines for choosing when each optimal MAPF solver to use. Prior work employed Algorithm Selection (AS) techniques to learn such guidelines from past data. A major challenge when employing AS for choosing an optimal MAPF algorithm is how to encode the given MAPF problem. Prior work either used hand-crafted features or an image representation of the problem. We explore graph-based encodings of the MAPF problem and show how they can be used on-the-fly with a modern graph embedding algorithm called FEATHER. Then, we show how this encoding can be effectively joined with existing encodings, resulting in a novel AS method we call MAPF Algorithm selection via Graph embedding (MAG). An extensive experimental evaluation of MAG on several MAPF algorithm selection tasks reveals that it is either on-par or significantly better than existing methods.
Training-Free Consistent Text-to-Image Generation
Feb 05, 2024Text-to-image models offer a new level of creative flexibility by allowing users to guide the image generation process through natural language. However, using these models to consistently portray the same subject across diverse prompts remains challenging. Existing approaches fine-tune the model to teach it new words that describe specific user-provided subjects or add image conditioning to the model. These methods require lengthy per-subject optimization or large-scale pre-training. Moreover, they struggle to align generated images with text prompts and face difficulties in portraying multiple subjects. Here, we present ConsiStory, a training-free approach that enables consistent subject generation by sharing the internal activations of the pretrained model. We introduce a subject-driven shared attention block and correspondence-based feature injection to promote subject consistency between images. Additionally, we develop strategies to encourage layout diversity while maintaining subject consistency. We compare ConsiStory to a range of baselines, and demonstrate state-of-the-art performance on subject consistency and text alignment, without requiring a single optimization step. Finally, ConsiStory can naturally extend to multi-subject scenarios, and even enable training-free personalization for common objects.