 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAMP: Hybrid DRL for Online Learning of Numeric Action Models
Apr 09, 2026Automated planning algorithms require an action model specifying the preconditions and effects of each action, but obtaining such a model is often hard. Learning action models from observations is feasible, but existing algorithms for numeric domains are offline, requiring expert traces as input. We propose the Reinforcement learning, Action Model learning, and Planning (RAMP) strategy for learning numeric planning action models online via interactions with the environment. RAMP simultaneously trains a Deep Reinforcement Learning (DRL) policy, learns a numeric action model from past interactions, and uses that model to plan future actions when possible. These components form a positive feedback loop: the RL policy gathers data to refine the action model, while the planner generates plans to continue training the RL policy. To facilitate this integration of RL and numeric planning, we developed Numeric PDDLGym, an automated framework for converting numeric planning problems to Gym environments. Experimental results on standard IPC numeric domains show that RAMP significantly outperforms PPO, a well-known DRL algorithm, in terms of solvability and plan quality.
Toward PDDL Planning Copilot
Sep 16, 2025Large Language Models (LLMs) are increasingly being used as autonomous agents capable of performing complicated tasks. However, they lack the ability to perform reliable long-horizon planning on their own. This paper bridges this gap by introducing the Planning Copilot, a chatbot that integrates multiple planning tools and allows users to invoke them through instructions in natural language. The Planning Copilot leverages the Model Context Protocol (MCP), a recently developed standard for connecting LLMs with external tools and systems. This approach allows using any LLM that supports MCP without domain-specific fine-tuning. Our Planning Copilot supports common planning tasks such as checking the syntax of planning problems, selecting an appropriate planner, calling it, validating the plan it generates, and simulating their execution. We empirically evaluate the ability of our Planning Copilot to perform these tasks using three open-source LLMs. The results show that the Planning Copilot highly outperforms using the same LLMs without the planning tools. We also conducted a limited qualitative comparison of our tool against Chat GPT-5, a very recent commercial LLM. Our results shows that our Planning Copilot significantly outperforms GPT-5 despite relying on a much smaller LLM. This suggests dedicated planning tools may be an effective way to enable LLMs to perform planning tasks.
EvoGPT: Enhancing Test Suite Robustness via LLM-Based Generation and Genetic Optimization
May 18, 2025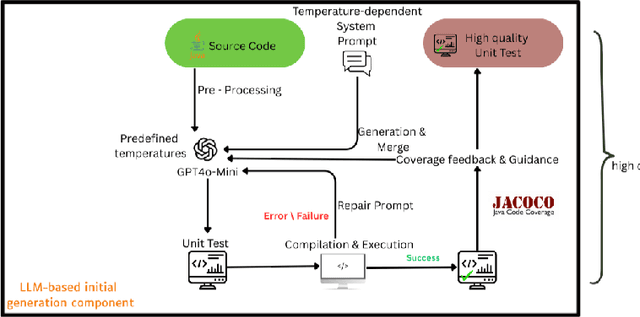
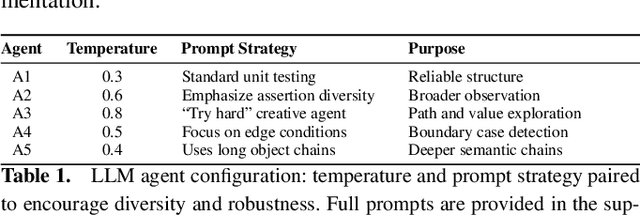

Large Language Models (LLMs) have recently emerged as promising tools for automated unit test generation. We introduce a hybrid framework called EvoGPT that integrates LLM-based test generation with evolutionary search techniques to create diverse, fault-revealing unit tests. Unit tests are initially generated with diverse temperature sampling to maximize behavioral and test suite diversity, followed by a generation-repair loop and coverage-guided assertion enhancement. The resulting test suites are evolved using genetic algorithms, guided by a fitness function prioritizing mutation score over traditional coverage metrics. This design emphasizes the primary objective of unit testing-fault detection. Evaluated on multiple open-source Java projects, EvoGPT achieves an average improvement of 10% in both code coverage and mutation score compared to LLMs and traditional search-based software testing baselines. These results demonstrate that combining LLM-driven diversity, targeted repair, and evolutionary optimization produces more effective and resilient test suites.
Integrating Reinforcement Learning, Action Model Learning, and Numeric Planning for Tackling Complex Tasks
Feb 18, 2025
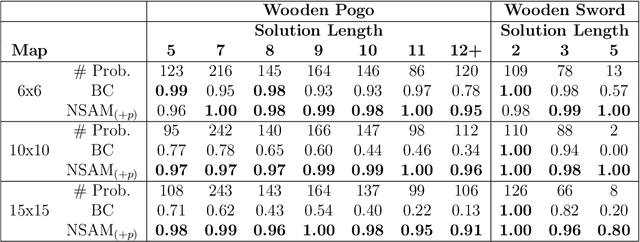
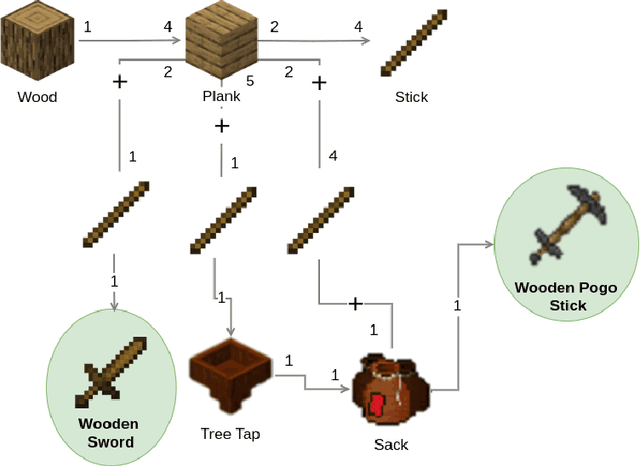
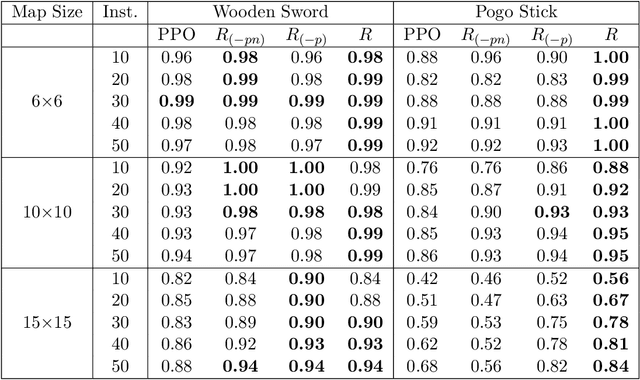
Automated Planning algorithms require a model of the domain that specifies the preconditions and effects of each action. Obtaining such a domain model is notoriously hard. Algorithms for learning domain models exist, yet it remains unclear whether learning a domain model and planning is an effective approach for numeric planning environments, i.e., where states include discrete and numeric state variables. In this work, we explore the benefits of learning a numeric domain model and compare it with alternative model-free solutions. As a case study, we use two tasks in Minecraft, a popular sandbox game that has been used as an AI challenge. First, we consider an offline learning setting, where a set of expert trajectories are available to learn from. This is the standard setting for learning domain models. We used the Numeric Safe Action Model Learning (NSAM) algorithm to learn a numeric domain model and solve new problems with the learned domain model and a numeric planner. We call this model-based solution NSAM_(+p), and compare it to several model-free Imitation Learning (IL) and Offline Reinforcement Learning (RL) algorithms. Empirical results show that some IL algorithms can learn faster to solve simple tasks, while NSAM_(+p) allows solving tasks that require long-term planning and enables generalizing to solve problems in larger environments. Then, we consider an online learning setting, where learning is done by moving an agent in the environment. For this setting, we introduce RAMP. In RAMP, observations collected during the agent's execution are used to simultaneously train an RL policy and learn a planning domain action model. This forms a positive feedback loop between the RL policy and the learned domain model. We demonstrate experimentally the benefits of using RAMP, showing that it finds more efficient plans and solves more problems than several RL baselines.
Transient Multi-Agent Path Finding for Lifelong Navigation in Dense Environments
Dec 05, 2024
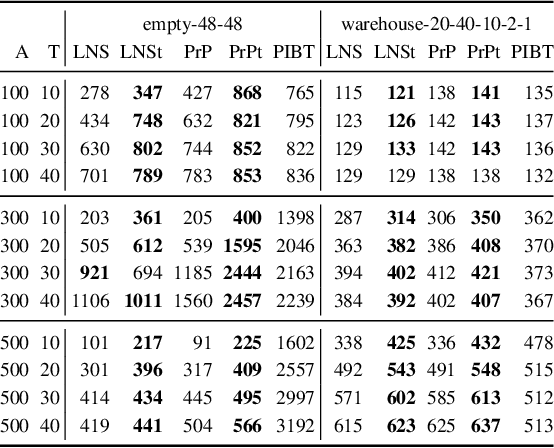

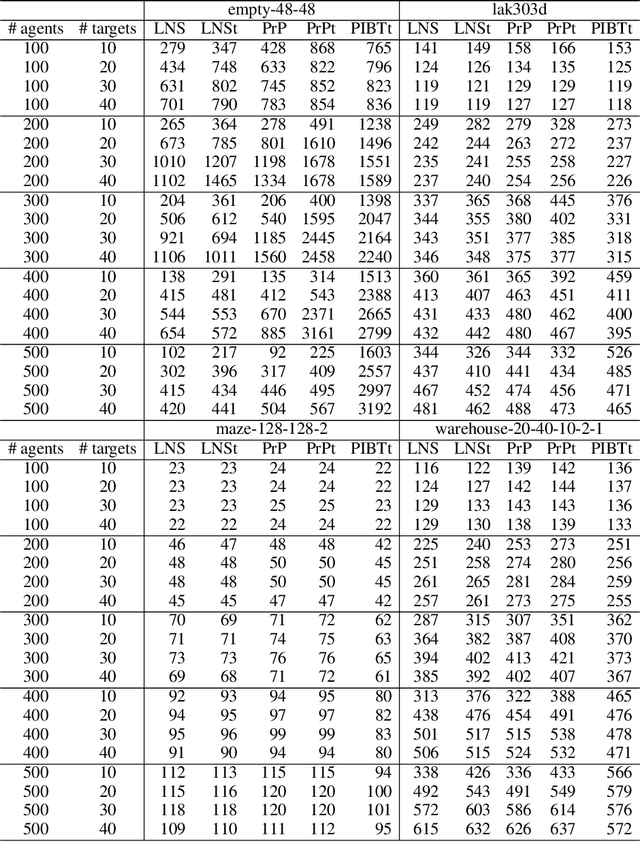
Multi-Agent Path Finding (MAPF) deals with finding conflict-free paths for a set of agents from an initial configuration to a given target configuration. The Lifelong MAPF (LMAPF) problem is a well-studied online version of MAPF in which an agent receives a new target when it reaches its current target. The common approach for solving LMAPF is to treat it as a sequence of MAPF problems, periodically replanning from the agents' current configurations to their current targets. A significant drawback in this approach is that in MAPF the agents must reach a configuration in which all agents are at their targets simultaneously, which is needlessly restrictive for LMAPF. Techniques have been proposed to indirectly mitigate this drawback. We describe cases where these mitigation techniques fail. As an alternative, we propose to solve LMAPF problems by solving a sequence of modified MAPF problems, in which the objective is for each agent to eventually visit its target, but not necessarily for all agents to do so simultaneously. We refer to this MAPF variant as Transient MAPF (TMAPF) and propose several algorithms for solving it based on existing MAPF algorithms. A limited experimental evaluation identifies some cases where using a TMAPF algorithm instead of a MAPF algorithm with an LMAPF framework can improve the system throughput significantly.
Algorithm Selection for Optimal Multi-Agent Path Finding via Graph Embedding
Jun 16, 2024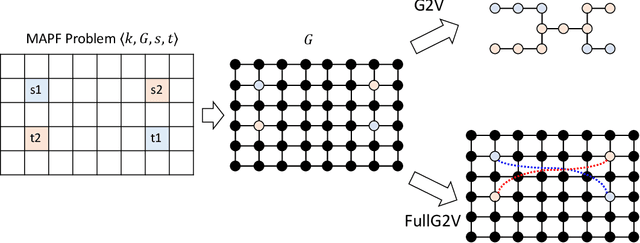
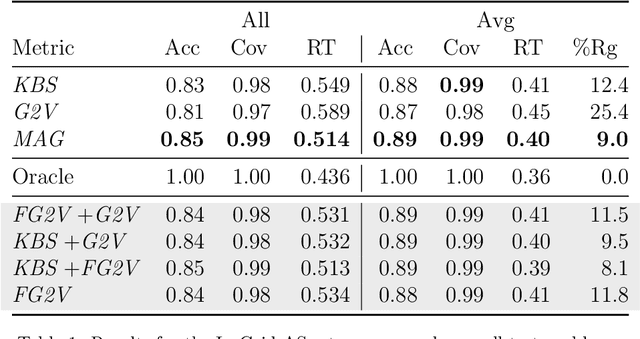
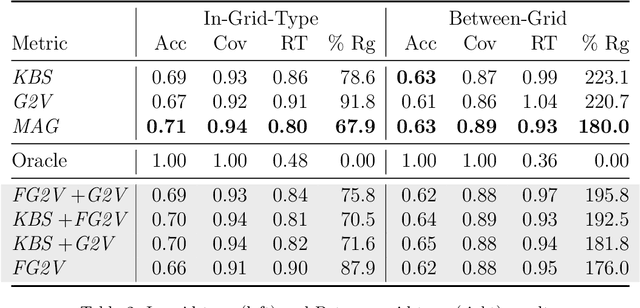
Multi-agent path finding (MAPF) is the problem of finding paths for multiple agents such that they do not collide. This problem manifests in numerous real-world applications such as controlling transportation robots in automated warehouses, moving characters in video games, and coordinating self-driving cars in intersections. Finding optimal solutions to MAPF is NP-Hard, yet modern optimal solvers can scale to hundreds of agents and even thousands in some cases. Different solvers employ different approaches, and there is no single state-of-the-art approach for all problems. Furthermore, there are no clear, provable, guidelines for choosing when each optimal MAPF solver to use. Prior work employed Algorithm Selection (AS) techniques to learn such guidelines from past data. A major challenge when employing AS for choosing an optimal MAPF algorithm is how to encode the given MAPF problem. Prior work either used hand-crafted features or an image representation of the problem. We explore graph-based encodings of the MAPF problem and show how they can be used on-the-fly with a modern graph embedding algorithm called FEATHER. Then, we show how this encoding can be effectively joined with existing encodings, resulting in a novel AS method we call MAPF Algorithm selection via Graph embedding (MAG). An extensive experimental evaluation of MAG on several MAPF algorithm selection tasks reveals that it is either on-par or significantly better than existing methods.
Optimal and Bounded Suboptimal Any-Angle Multi-agent Pathfinding
Apr 25, 2024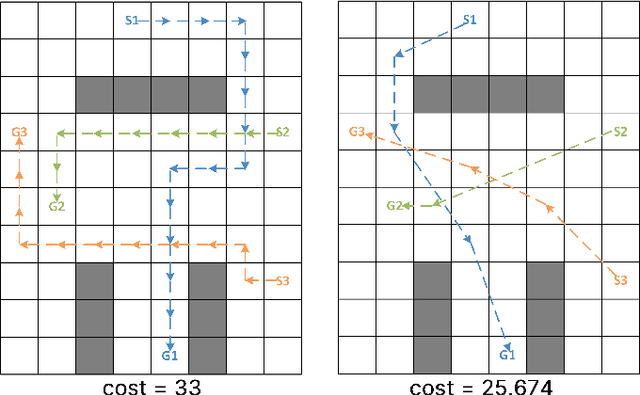

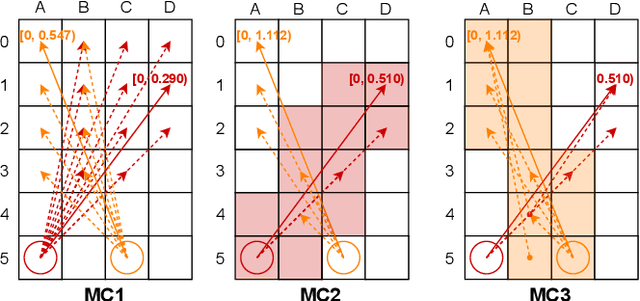
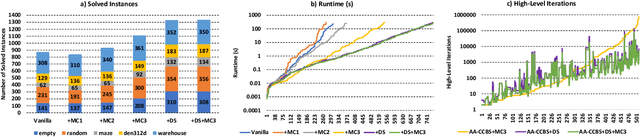
Multi-agent pathfinding (MAPF) is the problem of finding a set of conflict-free paths for a set of agents. Typically, the agents' moves are limited to a pre-defined graph of possible locations and allowed transitions between them, e.g. a 4-neighborhood grid. We explore how to solve MAPF problems when each agent can move between any pair of possible locations as long as traversing the line segment connecting them does not lead to the collision with the obstacles. This is known as any-angle pathfinding. We present the first optimal any-angle multi-agent pathfinding algorithm. Our planner is based on the Continuous Conflict-based Search (CCBS) algorithm and an optimal any-angle variant of the Safe Interval Path Planning (TO-AA-SIPP). The straightforward combination of those, however, scales poorly since any-angle path finding induces search trees with a very large branching factor. To mitigate this, we adapt two techniques from classical MAPF to the any-angle setting, namely Disjoint Splitting and Multi-Constraints. Experimental results on different combinations of these techniques show they enable solving over 30% more problems than the vanilla combination of CCBS and TO-AA-SIPP. In addition, we present a bounded-suboptimal variant of our algorithm, that enables trading runtime for solution cost in a controlled manner.
Safe Learning of PDDL Domains with Conditional Effects -- Extended Version
Mar 22, 2024Powerful domain-independent planners have been developed to solve various types of planning problems. These planners often require a model of the acting agent's actions, given in some planning domain description language. Manually designing such an action model is a notoriously challenging task. An alternative is to automatically learn action models from observation. Such an action model is called safe if every plan created with it is consistent with the real, unknown action model. Algorithms for learning such safe action models exist, yet they cannot handle domains with conditional or universal effects, which are common constructs in many planning problems. We prove that learning non-trivial safe action models with conditional effects may require an exponential number of samples. Then, we identify reasonable assumptions under which such learning is tractable and propose SAM Learning of Conditional Effects (Conditional-SAM), the first algorithm capable of doing so. We analyze Conditional-SAM theoretically and evaluate it experimentally. Our results show that the action models learned by Conditional-SAM can be used to solve perfectly most of the test set problems in most of the experimented domains.
Enhancing Numeric-SAM for Learning with Few Observations
Dec 17, 2023



A significant challenge in applying planning technology to real-world problems lies in obtaining a planning model that accurately represents the problem's dynamics. Numeric Safe Action Models Learning (N-SAM) is a recently proposed algorithm that addresses this challenge. It is an algorithm designed to learn the preconditions and effects of actions from observations in domains that may involve both discrete and continuous state variables. N-SAM has several attractive properties. It runs in polynomial time and is guaranteed to output an action model that is safe, in the sense that plans generated by it are applicable and will achieve their intended goals. To preserve this safety guarantee, N-SAM must observe a substantial number of examples for each action before it is included in the learned action model. We address this limitation of N-SAM and propose N-SAM*, an enhanced version of N-SAM that always returns an action model where every observed action is applicable at least in some state, even if it was only observed once. N-SAM* does so without compromising the safety of the returned action model. We prove that N-SAM* is optimal in terms of sample complexity compared to any other algorithm that guarantees safety. An empirical study on a set of benchmark domains shows that the action models returned by N-SAM* enable solving significantly more problems compared to the action models returned by N-SAM.
A Domain-Independent Agent Architecture for Adaptive Operation in Evolving Open Worlds
Jun 09, 2023



Model-based reasoning agents are ill-equipped to act in novel situations in which their model of the environment no longer sufficiently represents the world. We propose HYDRA - a framework for designing model-based agents operating in mixed discrete-continuous worlds, that can autonomously detect when the environment has evolved from its canonical setup, understand how it has evolved, and adapt the agents' models to perform effectively. HYDRA is based upon PDDL+, a rich modeling language for planning in mixed, discrete-continuous environments. It augments the planning module with visual reasoning, task selection, and action execution modules for closed-loop interaction with complex environments. HYDRA implements a novel meta-reasoning process that enables the agent to monitor its own behavior from a variety of aspects. The process employs a diverse set of computational methods to maintain expectations about the agent's own behavior in an environment. Divergences from those expectations are useful in detecting when the environment has evolved and identifying opportunities to adapt the underlying models. HYDRA builds upon ideas from diagnosis and repair and uses a heuristics-guided search over model changes such that they become competent in novel conditions. The HYDRA framework has been used to implement novelty-aware agents for three diverse domains - CartPole++ (a higher dimension variant of a classic control problem), Science Birds (an IJCAI competition problem), and PogoStick (a specific problem domain in Minecraft). We report empirical observations from these domains to demonstrate the efficacy of various components in the novelty meta-reasoning process.