 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Kinematics to Dynamics: Learning to Refine Hybrid Plans for Physically Feasible Execution
Apr 14, 2026In many robotic tasks, agents must traverse a sequence of spatial regions to complete a mission. Such problems are inherently mixed discrete-continuous: a high-level action sequence and a physically feasible continuous trajectory. The resulting trajectory and action sequence must also satisfy problem constraints such as deadlines, time windows, and velocity or acceleration limits. While hybrid temporal planners attempt to address this challenge, they typically model motion using linear (first-order) dynamics, which cannot guarantee that the resulting plan respects the robot's true physical constraints. Consequently, even when the high-level action sequence is fixed, producing a dynamically feasible trajectory becomes a bi-level optimization problem. We address this problem via reinforcement learning in continuous space. We define a Markov Decision Process that explicitly incorporates analytical second-order constraints and use it to refine first-order plans generated by a hybrid planner. Our results show that this approach can reliably recover physical feasibility and effectively bridge the gap between a planner's initial first-order trajectory and the dynamics required for real execution.
RAMP: Hybrid DRL for Online Learning of Numeric Action Models
Apr 09, 2026Automated planning algorithms require an action model specifying the preconditions and effects of each action, but obtaining such a model is often hard. Learning action models from observations is feasible, but existing algorithms for numeric domains are offline, requiring expert traces as input. We propose the Reinforcement learning, Action Model learning, and Planning (RAMP) strategy for learning numeric planning action models online via interactions with the environment. RAMP simultaneously trains a Deep Reinforcement Learning (DRL) policy, learns a numeric action model from past interactions, and uses that model to plan future actions when possible. These components form a positive feedback loop: the RL policy gathers data to refine the action model, while the planner generates plans to continue training the RL policy. To facilitate this integration of RL and numeric planning, we developed Numeric PDDLGym, an automated framework for converting numeric planning problems to Gym environments. Experimental results on standard IPC numeric domains show that RAMP significantly outperforms PPO, a well-known DRL algorithm, in terms of solvability and plan quality.
Beyond Single-Step Updates: Reinforcement Learning of Heuristics with Limited-Horizon Search
Nov 13, 2025Many sequential decision-making problems can be formulated as shortest-path problems, where the objective is to reach a goal state from a given starting state. Heuristic search is a standard approach for solving such problems, relying on a heuristic function to estimate the cost to the goal from any given state. Recent approaches leverage reinforcement learning to learn heuristics by applying deep approximate value iteration. These methods typically rely on single-step Bellman updates, where the heuristic of a state is updated based on its best neighbor and the corresponding edge cost. This work proposes a generalized approach that enhances both state sampling and heuristic updates by performing limited-horizon searches and updating each state's heuristic based on the shortest path to the search frontier, incorporating both edge costs and the heuristic values of frontier states.
Bidirectional Bounded-Suboptimal Heuristic Search with Consistent Heuristics
Nov 13, 2025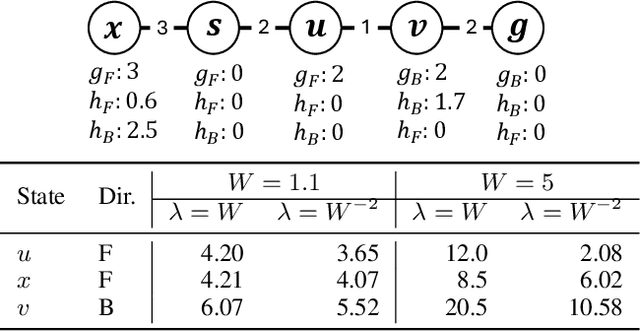
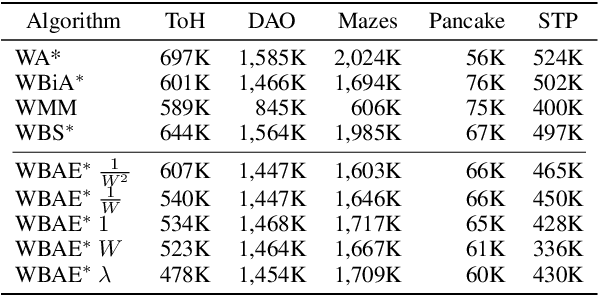

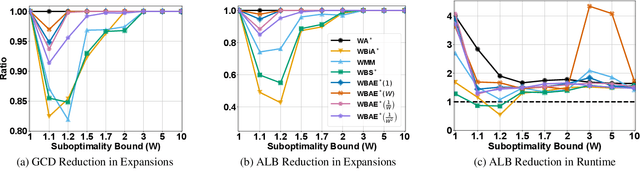
Recent advancements in bidirectional heuristic search have yielded significant theoretical insights and novel algorithms. While most previous work has concentrated on optimal search methods, this paper focuses on bounded-suboptimal bidirectional search, where a bound on the suboptimality of the solution cost is specified. We build upon the state-of-the-art optimal bidirectional search algorithm, BAE*, designed for consistent heuristics, and introduce several variants of BAE* specifically tailored for the bounded-suboptimal context. Through experimental evaluation, we compare the performance of these new variants against other bounded-suboptimal bidirectional algorithms as well as the standard weighted A* algorithm. Our results demonstrate that each algorithm excels under distinct conditions, highlighting the strengths and weaknesses of each approach.
Toward PDDL Planning Copilot
Sep 16, 2025Large Language Models (LLMs) are increasingly being used as autonomous agents capable of performing complicated tasks. However, they lack the ability to perform reliable long-horizon planning on their own. This paper bridges this gap by introducing the Planning Copilot, a chatbot that integrates multiple planning tools and allows users to invoke them through instructions in natural language. The Planning Copilot leverages the Model Context Protocol (MCP), a recently developed standard for connecting LLMs with external tools and systems. This approach allows using any LLM that supports MCP without domain-specific fine-tuning. Our Planning Copilot supports common planning tasks such as checking the syntax of planning problems, selecting an appropriate planner, calling it, validating the plan it generates, and simulating their execution. We empirically evaluate the ability of our Planning Copilot to perform these tasks using three open-source LLMs. The results show that the Planning Copilot highly outperforms using the same LLMs without the planning tools. We also conducted a limited qualitative comparison of our tool against Chat GPT-5, a very recent commercial LLM. Our results shows that our Planning Copilot significantly outperforms GPT-5 despite relying on a much smaller LLM. This suggests dedicated planning tools may be an effective way to enable LLMs to perform planning tasks.
Integrating Reinforcement Learning, Action Model Learning, and Numeric Planning for Tackling Complex Tasks
Feb 18, 2025
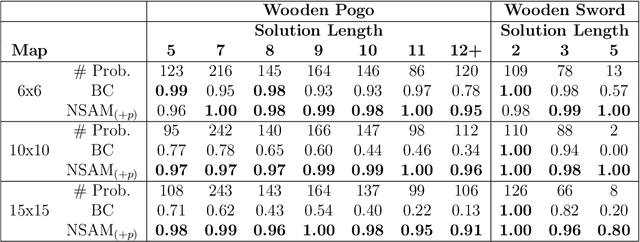
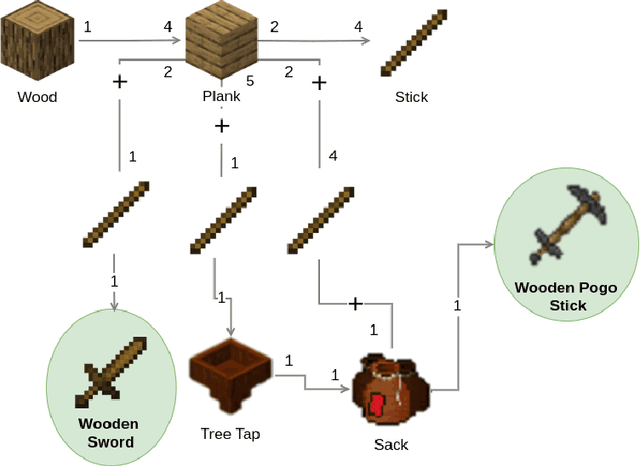
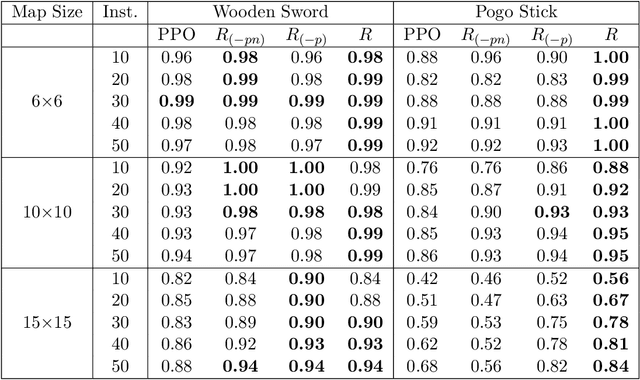
Automated Planning algorithms require a model of the domain that specifies the preconditions and effects of each action. Obtaining such a domain model is notoriously hard. Algorithms for learning domain models exist, yet it remains unclear whether learning a domain model and planning is an effective approach for numeric planning environments, i.e., where states include discrete and numeric state variables. In this work, we explore the benefits of learning a numeric domain model and compare it with alternative model-free solutions. As a case study, we use two tasks in Minecraft, a popular sandbox game that has been used as an AI challenge. First, we consider an offline learning setting, where a set of expert trajectories are available to learn from. This is the standard setting for learning domain models. We used the Numeric Safe Action Model Learning (NSAM) algorithm to learn a numeric domain model and solve new problems with the learned domain model and a numeric planner. We call this model-based solution NSAM_(+p), and compare it to several model-free Imitation Learning (IL) and Offline Reinforcement Learning (RL) algorithms. Empirical results show that some IL algorithms can learn faster to solve simple tasks, while NSAM_(+p) allows solving tasks that require long-term planning and enables generalizing to solve problems in larger environments. Then, we consider an online learning setting, where learning is done by moving an agent in the environment. For this setting, we introduce RAMP. In RAMP, observations collected during the agent's execution are used to simultaneously train an RL policy and learn a planning domain action model. This forms a positive feedback loop between the RL policy and the learned domain model. We demonstrate experimentally the benefits of using RAMP, showing that it finds more efficient plans and solves more problems than several RL baselines.
On Parallel External-Memory Bidirectional Search
Dec 30, 2024

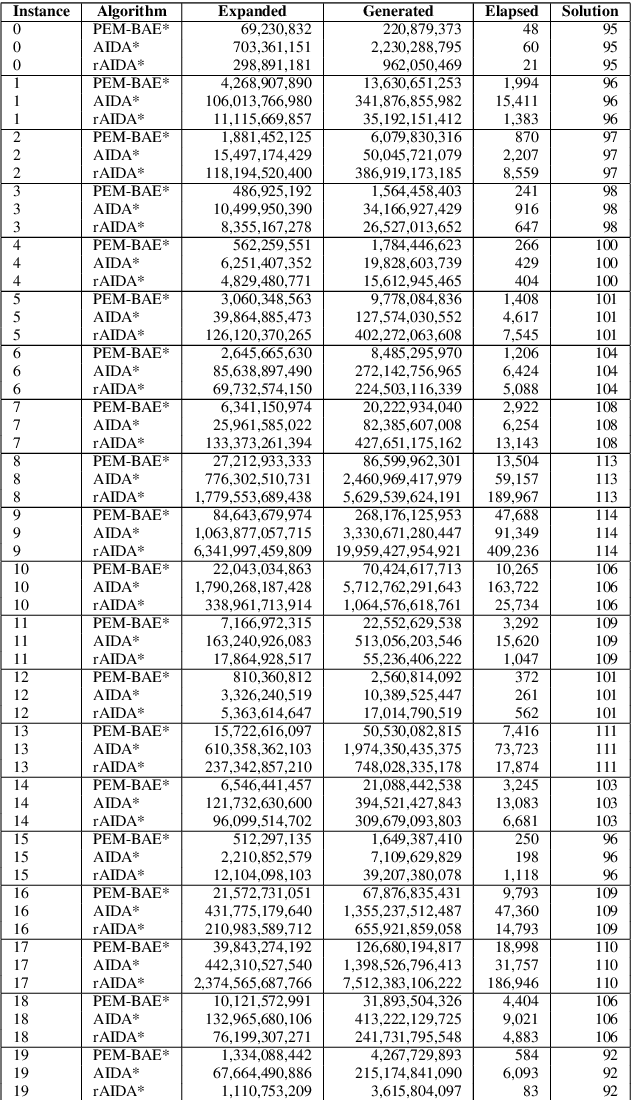
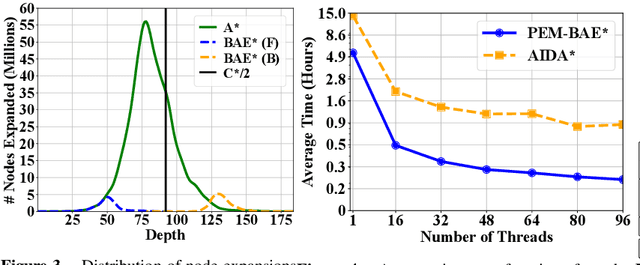
Parallelization and External Memory (PEM) techniques have significantly enhanced the capabilities of search algorithms when solving large-scale problems. Previous research on PEM has primarily centered on unidirectional algorithms, with only one publication on bidirectional PEM that focuses on the meet-in-the-middle (MM) algorithm. Building upon this foundation, this paper presents a framework that integrates both uni- and bi-directional best-first search algorithms into this framework. We then develop a PEM variant of the state-of-the-art bidirectional heuristic search (\BiHS) algorithm BAE* (PEM-BAE*). As previous work on \BiHS did not focus on scaling problem sizes, this work enables us to evaluate bidirectional algorithms on hard problems. Empirical evaluation shows that PEM-BAE* outperforms the PEM variants of A* and the MM algorithm, as well as a parallel variant of IDA*. These findings mark a significant milestone, revealing that bidirectional search algorithms clearly outperform unidirectional search algorithms across several domains, even when equipped with state-of-the-art heuristics.
Effort Allocation for Deadline-Aware Task and Motion Planning: A Metareasoning Approach
Oct 08, 2024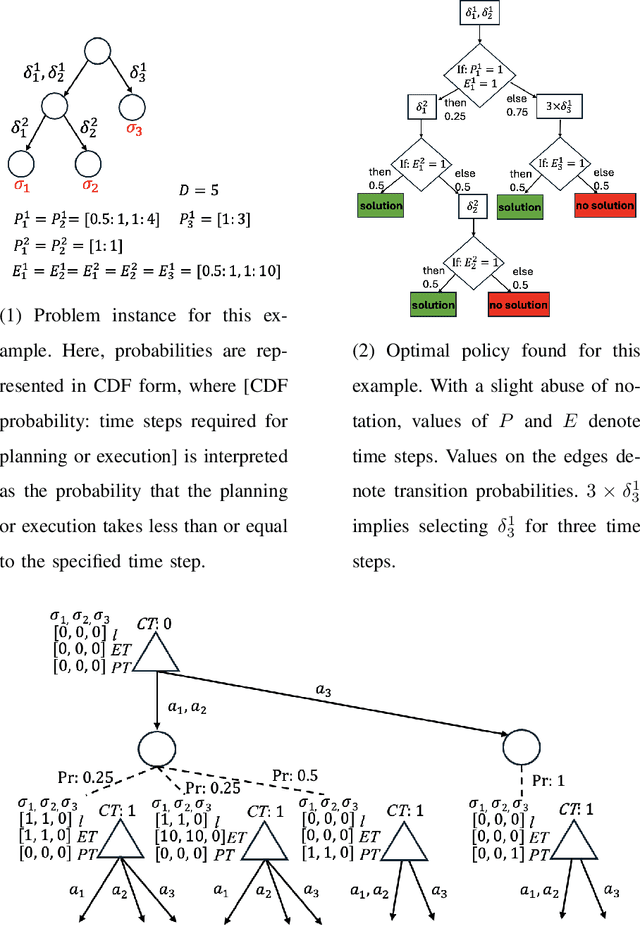


In robot planning, tasks can often be achieved through multiple options, each consisting of several actions. This work specifically addresses deadline constraints in task and motion planning, aiming to find a plan that can be executed within the deadline despite uncertain planning and execution times. We propose an effort allocation problem, formulated as a Markov decision process (MDP), to find such a plan by leveraging metareasoning perspectives to allocate computational resources among the given options. We formally prove the NP-hardness of the problem by reducing it from the knapsack problem. Both a model-based approach, where transition models are learned from past experience, and a model-free approach, which overcomes the unavailability of prior data acquisition through reinforcement learning, are explored. For the model-based approach, we investigate Monte Carlo tree search (MCTS) to approximately solve the proposed MDP and further design heuristic schemes to tackle NP-hardness, leading to the approximate yet efficient algorithm called DP_Rerun. In experiments, DP_Rerun demonstrates promising performance comparable to MCTS while requiring negligible computation time.
Enhancing Numeric-SAM for Learning with Few Observations
Dec 17, 2023



A significant challenge in applying planning technology to real-world problems lies in obtaining a planning model that accurately represents the problem's dynamics. Numeric Safe Action Models Learning (N-SAM) is a recently proposed algorithm that addresses this challenge. It is an algorithm designed to learn the preconditions and effects of actions from observations in domains that may involve both discrete and continuous state variables. N-SAM has several attractive properties. It runs in polynomial time and is guaranteed to output an action model that is safe, in the sense that plans generated by it are applicable and will achieve their intended goals. To preserve this safety guarantee, N-SAM must observe a substantial number of examples for each action before it is included in the learned action model. We address this limitation of N-SAM and propose N-SAM*, an enhanced version of N-SAM that always returns an action model where every observed action is applicable at least in some state, even if it was only observed once. N-SAM* does so without compromising the safety of the returned action model. We prove that N-SAM* is optimal in terms of sample complexity compared to any other algorithm that guarantees safety. An empirical study on a set of benchmark domains shows that the action models returned by N-SAM* enable solving significantly more problems compared to the action models returned by N-SAM.
A Formal Metareasoning Model of Concurrent Planning and Execution
Mar 05, 2023Agents that plan and act in the real world must deal with the fact that time passes as they are planning. When timing is tight, there may be insufficient time to complete the search for a plan before it is time to act. By commencing execution before search concludes, one gains time to search by making planning and execution concurrent. However, this incurs the risk of making incorrect action choices, especially if actions are irreversible. This tradeoff between opportunity and risk is the problem addressed in this paper. Our main contribution is to formally define this setting as an abstract metareasoning problem. We find that the abstract problem is intractable. However, we identify special cases that are solvable in polynomial time, develop greedy solution algorithms, and, through tests on instances derived from search problems, find several methods that achieve promising practical performance. This work lays the foundation for a principled time-aware executive that concurrently plans and executes.