 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward PDDL Planning Copilot
Sep 16, 2025Large Language Models (LLMs) are increasingly being used as autonomous agents capable of performing complicated tasks. However, they lack the ability to perform reliable long-horizon planning on their own. This paper bridges this gap by introducing the Planning Copilot, a chatbot that integrates multiple planning tools and allows users to invoke them through instructions in natural language. The Planning Copilot leverages the Model Context Protocol (MCP), a recently developed standard for connecting LLMs with external tools and systems. This approach allows using any LLM that supports MCP without domain-specific fine-tuning. Our Planning Copilot supports common planning tasks such as checking the syntax of planning problems, selecting an appropriate planner, calling it, validating the plan it generates, and simulating their execution. We empirically evaluate the ability of our Planning Copilot to perform these tasks using three open-source LLMs. The results show that the Planning Copilot highly outperforms using the same LLMs without the planning tools. We also conducted a limited qualitative comparison of our tool against Chat GPT-5, a very recent commercial LLM. Our results shows that our Planning Copilot significantly outperforms GPT-5 despite relying on a much smaller LLM. This suggests dedicated planning tools may be an effective way to enable LLMs to perform planning tasks.
Integrating Reinforcement Learning, Action Model Learning, and Numeric Planning for Tackling Complex Tasks
Feb 18, 2025
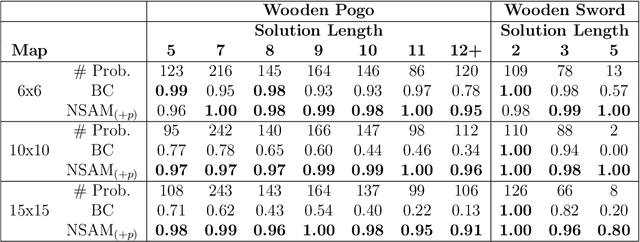
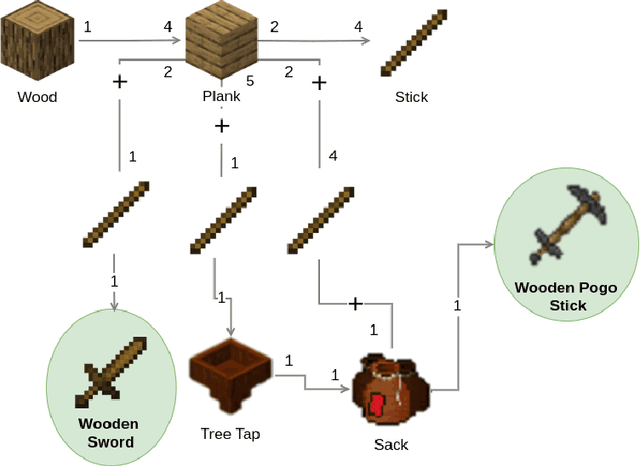
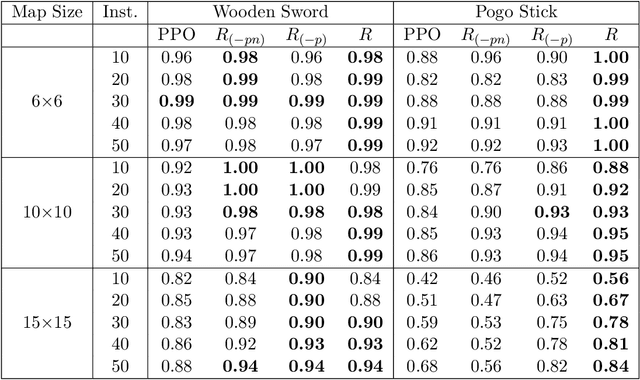
Automated Planning algorithms require a model of the domain that specifies the preconditions and effects of each action. Obtaining such a domain model is notoriously hard. Algorithms for learning domain models exist, yet it remains unclear whether learning a domain model and planning is an effective approach for numeric planning environments, i.e., where states include discrete and numeric state variables. In this work, we explore the benefits of learning a numeric domain model and compare it with alternative model-free solutions. As a case study, we use two tasks in Minecraft, a popular sandbox game that has been used as an AI challenge. First, we consider an offline learning setting, where a set of expert trajectories are available to learn from. This is the standard setting for learning domain models. We used the Numeric Safe Action Model Learning (NSAM) algorithm to learn a numeric domain model and solve new problems with the learned domain model and a numeric planner. We call this model-based solution NSAM_(+p), and compare it to several model-free Imitation Learning (IL) and Offline Reinforcement Learning (RL) algorithms. Empirical results show that some IL algorithms can learn faster to solve simple tasks, while NSAM_(+p) allows solving tasks that require long-term planning and enables generalizing to solve problems in larger environments. Then, we consider an online learning setting, where learning is done by moving an agent in the environment. For this setting, we introduce RAMP. In RAMP, observations collected during the agent's execution are used to simultaneously train an RL policy and learn a planning domain action model. This forms a positive feedback loop between the RL policy and the learned domain model. We demonstrate experimentally the benefits of using RAMP, showing that it finds more efficient plans and solves more problems than several RL baselines.
Safe Learning of PDDL Domains with Conditional Effects -- Extended Version
Mar 22, 2024Powerful domain-independent planners have been developed to solve various types of planning problems. These planners often require a model of the acting agent's actions, given in some planning domain description language. Manually designing such an action model is a notoriously challenging task. An alternative is to automatically learn action models from observation. Such an action model is called safe if every plan created with it is consistent with the real, unknown action model. Algorithms for learning such safe action models exist, yet they cannot handle domains with conditional or universal effects, which are common constructs in many planning problems. We prove that learning non-trivial safe action models with conditional effects may require an exponential number of samples. Then, we identify reasonable assumptions under which such learning is tractable and propose SAM Learning of Conditional Effects (Conditional-SAM), the first algorithm capable of doing so. We analyze Conditional-SAM theoretically and evaluate it experimentally. Our results show that the action models learned by Conditional-SAM can be used to solve perfectly most of the test set problems in most of the experimented domains.
Enhancing Numeric-SAM for Learning with Few Observations
Dec 17, 2023



A significant challenge in applying planning technology to real-world problems lies in obtaining a planning model that accurately represents the problem's dynamics. Numeric Safe Action Models Learning (N-SAM) is a recently proposed algorithm that addresses this challenge. It is an algorithm designed to learn the preconditions and effects of actions from observations in domains that may involve both discrete and continuous state variables. N-SAM has several attractive properties. It runs in polynomial time and is guaranteed to output an action model that is safe, in the sense that plans generated by it are applicable and will achieve their intended goals. To preserve this safety guarantee, N-SAM must observe a substantial number of examples for each action before it is included in the learned action model. We address this limitation of N-SAM and propose N-SAM*, an enhanced version of N-SAM that always returns an action model where every observed action is applicable at least in some state, even if it was only observed once. N-SAM* does so without compromising the safety of the returned action model. We prove that N-SAM* is optimal in terms of sample complexity compared to any other algorithm that guarantees safety. An empirical study on a set of benchmark domains shows that the action models returned by N-SAM* enable solving significantly more problems compared to the action models returned by N-SAM.