 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTWISTED-RL: Hierarchical Skilled Agents for Knot-Tying without Human Demonstrations
Feb 16, 2026Robotic knot-tying represents a fundamental challenge in robotics due to the complex interactions between deformable objects and strict topological constraints. We present TWISTED-RL, a framework that improves upon the previous state-of-the-art in demonstration-free knot-tying (TWISTED), which smartly decomposed a single knot-tying problem into manageable subproblems, each addressed by a specialized agent. Our approach replaces TWISTED's single-step inverse model that was learned via supervised learning with a multi-step Reinforcement Learning policy conditioned on abstract topological actions rather than goal states. This change allows more delicate topological state transitions while avoiding costly and ineffective data collection protocols, thus enabling better generalization across diverse knot configurations. Experimental results demonstrate that TWISTED-RL manages to solve previously unattainable knots of higher complexity, including commonly used knots such as the Figure-8 and the Overhand. Furthermore, the increase in success rates and drop in planning time establishes TWISTED-RL as the new state-of-the-art in robotic knot-tying without human demonstrations.
Planning and Acting While the Clock Ticks
Mar 21, 2024

Standard temporal planning assumes that planning takes place offline and then execution starts at time 0. Recently, situated temporal planning was introduced, where planning starts at time 0 and execution occurs after planning terminates. Situated temporal planning reflects a more realistic scenario where time passes during planning. However, in situated temporal planning a complete plan must be generated before any action is executed. In some problems with time pressure, timing is too tight to complete planning before the first action must be executed. For example, an autonomous car that has a truck backing towards it should probably move out of the way now and plan how to get to its destination later. In this paper, we propose a new problem setting: concurrent planning and execution, in which actions can be dispatched (executed) before planning terminates. Unlike previous work on planning and execution, we must handle wall clock deadlines that affect action applicability and goal achievement (as in situated planning) while also supporting dispatching actions before a complete plan has been found. We extend previous work on metareasoning for situated temporal planning to develop an algorithm for this new setting. Our empirical evaluation shows that when there is strong time pressure, our approach outperforms situated temporal planning.
A Formal Metareasoning Model of Concurrent Planning and Execution
Mar 05, 2023Agents that plan and act in the real world must deal with the fact that time passes as they are planning. When timing is tight, there may be insufficient time to complete the search for a plan before it is time to act. By commencing execution before search concludes, one gains time to search by making planning and execution concurrent. However, this incurs the risk of making incorrect action choices, especially if actions are irreversible. This tradeoff between opportunity and risk is the problem addressed in this paper. Our main contribution is to formally define this setting as an abstract metareasoning problem. We find that the abstract problem is intractable. However, we identify special cases that are solvable in polynomial time, develop greedy solution algorithms, and, through tests on instances derived from search problems, find several methods that achieve promising practical performance. This work lays the foundation for a principled time-aware executive that concurrently plans and executes.
Robofriend: An Adpative Storytelling Robotic Teddy Bear -- Technical Report
Jan 04, 2023In this paper we describe Robofriend, a robotic teddy bear for telling stories to young children. Robofriend adapts its behavior to keep the childrens' attention using reinforcement learning.
A Conflict-driven Interface between Symbolic Planning and Nonlinear Constraint Solving
Nov 28, 2022
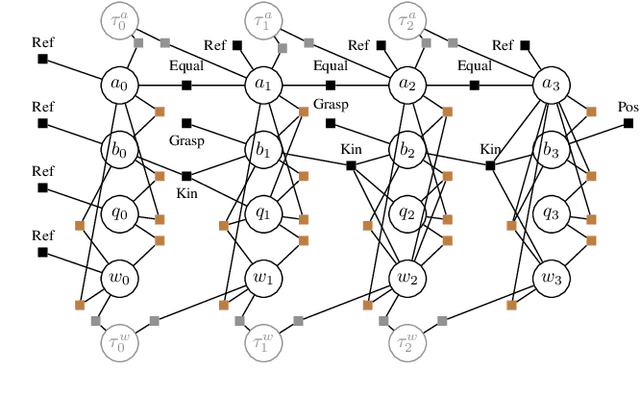
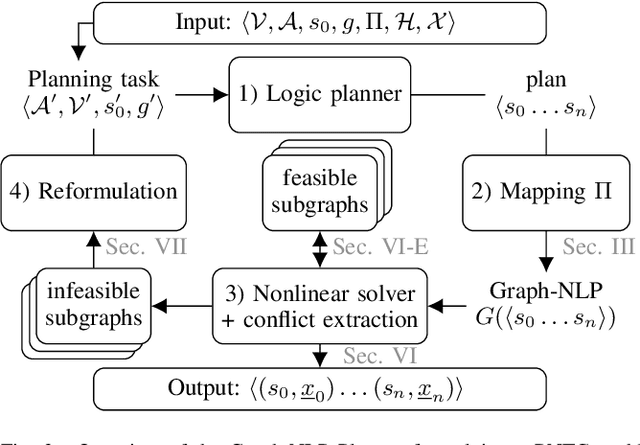
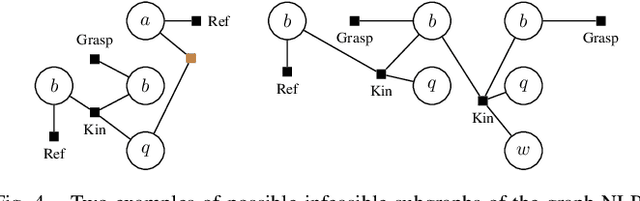
Robotic planning in real-world scenarios typically requires joint optimization of logic and continuous variables. A core challenge to combine the strengths of logic planners and continuous solvers is the design of an efficient interface that informs the logical search about continuous infeasibilities. In this paper we present a novel iterative algorithm that connects logic planning with nonlinear optimization through a bidirectional interface, achieved by the detection of minimal subsets of nonlinear constraints that are infeasible. The algorithm continuously builds a database of graphs that represent (in)feasible subsets of continuous variables and constraints, and encodes this knowledge in the logical description. As a foundation for this algorithm, we introduce Planning with Nonlinear Transition Constraints (PNTC), a novel planning formulation that clarifies the exact assumptions our algorithm requires and can be applied to model Task and Motion Planning (TAMP) efficiently. Our experimental results show that our framework significantly outperforms alternative optimization-based approaches for TAMP.
Understanding Natural Language in Context
May 25, 2022

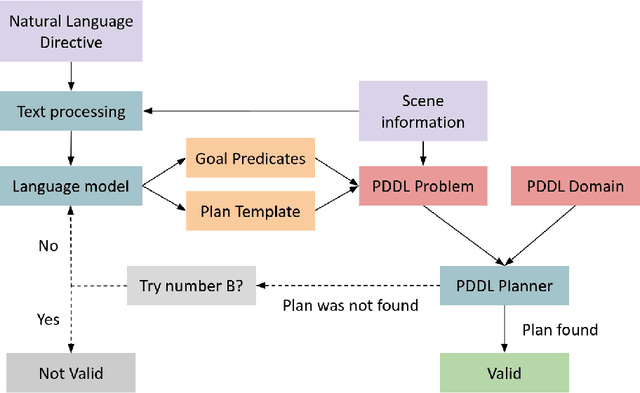
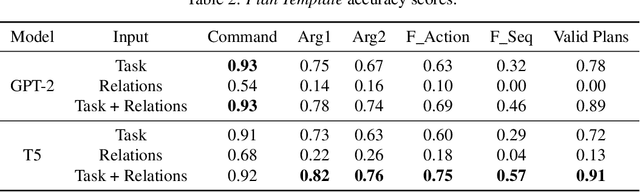
Recent years have seen an increasing number of applications that have a natural language interface, either in the form of chatbots or via personal assistants such as Alexa (Amazon), Google Assistant, Siri (Apple), and Cortana (Microsoft). To use these applications, a basic dialog between the robot and the human is required. While this kind of dialog exists today mainly within "static" robots that do not make any movement in the household space, the challenge of reasoning about the information conveyed by the environment increases significantly when dealing with robots that can move and manipulate objects in our home environment. In this paper, we focus on cognitive robots, which have some knowledge-based models of the world and operate by reasoning and planning with this model. Thus, when the robot and the human communicate, there is already some formalism they can use - the robot's knowledge representation formalism. Our goal in this research is to translate natural language utterances into this robot's formalism, allowing much more complicated household tasks to be completed. We do so by combining off-the-shelf SOTA language models, planning tools, and the robot's knowledge-base for better communication. In addition, we analyze different directive types and illustrate the contribution of the world's context to the translation process.
Generalized Planning With Deep Reinforcement Learning
May 05, 2020


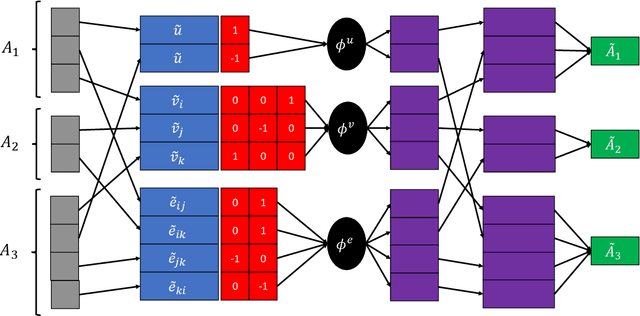
A hallmark of intelligence is the ability to deduce general principles from examples, which are correct beyond the range of those observed. Generalized Planning deals with finding such principles for a class of planning problems, so that principles discovered using small instances of a domain can be used to solve much larger instances of the same domain. In this work we study the use of Deep Reinforcement Learning and Graph Neural Networks to learn such generalized policies and demonstrate that they can generalize to instances that are orders of magnitude larger than those they were trained on.
Automated Tactical Decision Planning Model with Strategic Values Guidance for Local Action-Value-Ambiguity
Nov 30, 2018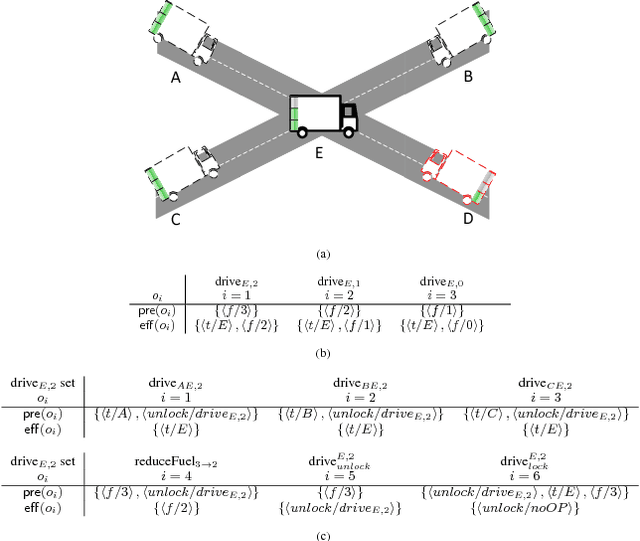
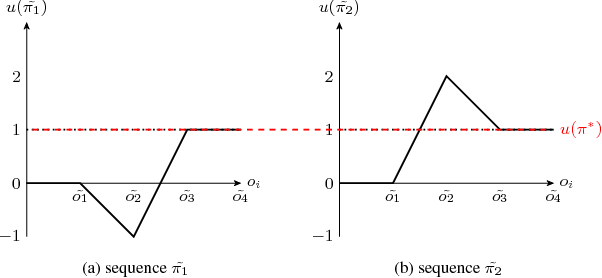
In many real-world planning problems, action's impact differs with a place, time and the context in which the action is applied. The same action with the same effects in a different context or states can cause a different change. In actions with incomplete precondition list, that applicable in several states and circumstances, ambiguity regarding the impact of the action is challenging even in small domains. To estimate the real impact of actions, an evaluation of the effect list will not be enough; a relative estimation is more informative and suitable for estimation of action's real impact. Recent work on Over-subscription Planning (OSP) defined the net utility of action as the net change in the state's value caused by the action. The notion of net utility of action allows for a broader perspective on value action impact and use for a more accurate evaluation of achievements of the action, considering inter-state and intra-state dependencies. To achieve value-rational decisions in complex reality often requires strategic, high level, planning with a global perspective and values, while many local tactical decisions require real-time information to estimate the impact of actions. This paper proposes an offline action-value structure analysis to exploit the compactly represented informativeness of net utility of actions to extend the scope of planning to value uncertainty scenarios and to provide a real-time value-rational decision planning tool. The result of the offline pre-processing phase is a compact decision planning model representation for flexible, local reasoning of net utility of actions with (offline) value ambiguity. The obtained flexibility is beneficial for the online planning phase and real-time execution of actions with value ambiguity. Our empirical evaluation shows the effectiveness of this approach in domains with value ambiguity in their action-value-structure.
Online Speedup Learning for Optimal Planning
Jan 23, 2014
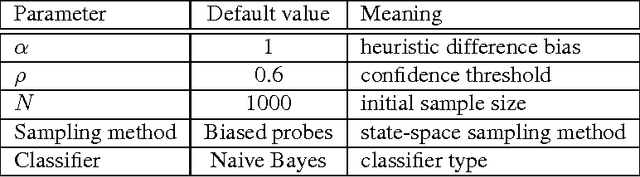
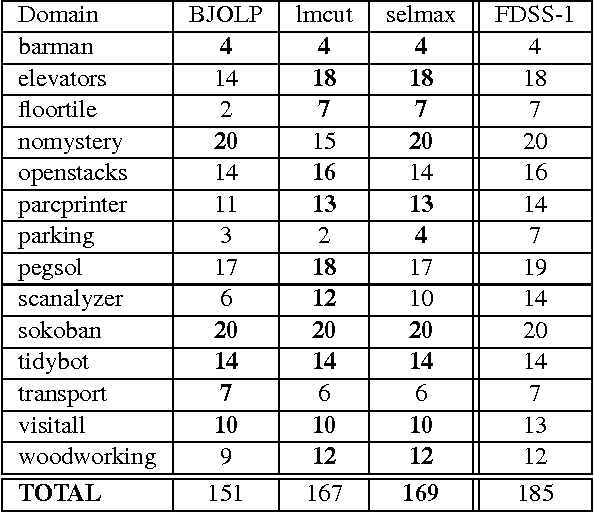
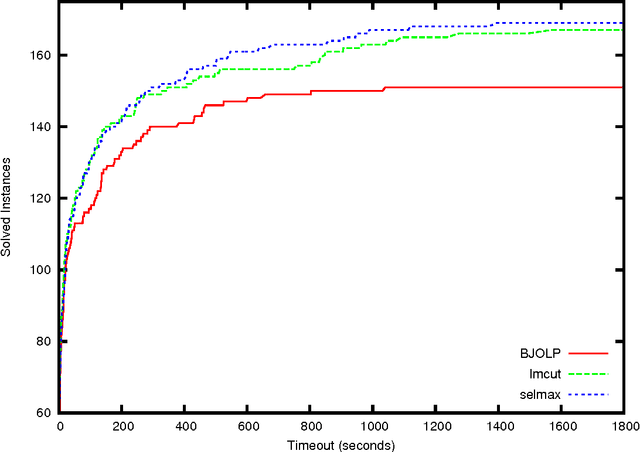
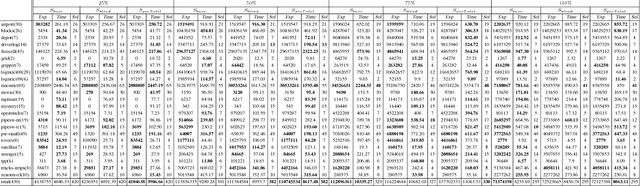
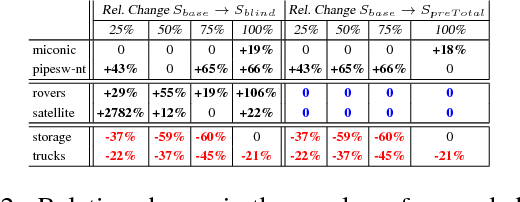
Domain-independent planning is one of the foundational areas in the field of Artificial Intelligence. A description of a planning task consists of an initial world state, a goal, and a set of actions for modifying the world state. The objective is to find a sequence of actions, that is, a plan, that transforms the initial world state into a goal state. In optimal planning, we are interested in finding not just a plan, but one of the cheapest plans. A prominent approach to optimal planning these days is heuristic state-space search, guided by admissible heuristic functions. Numerous admissible heuristics have been developed, each with its own strengths and weaknesses, and it is well known that there is no single "best heuristic for optimal planning in general. Thus, which heuristic to choose for a given planning task is a difficult question. This difficulty can be avoided by combining several heuristics, but that requires computing numerous heuristic estimates at each state, and the tradeoff between the time spent doing so and the time saved by the combined advantages of the different heuristics might be high. We present a novel method that reduces the cost of combining admissible heuristics for optimal planning, while maintaining its benefits. Using an idealized search space model, we formulate a decision rule for choosing the best heuristic to compute at each state. We then present an active online learning approach for learning a classifier with that decision rule as the target concept, and employ the learned classifier to decide which heuristic to compute at each state. We evaluate this technique empirically, and show that it substantially outperforms the standard method for combining several heuristics via their pointwise maximum.
Towards Rational Deployment of Multiple Heuristics in A*
May 22, 2013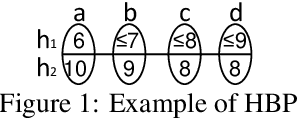
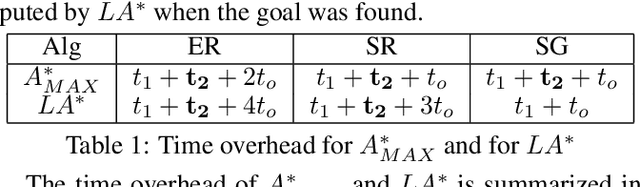
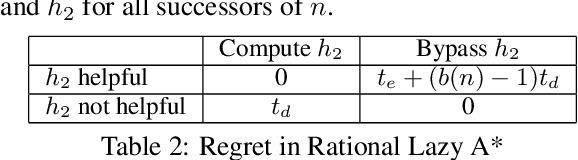

The obvious way to use several admissible heuristics in A* is to take their maximum. In this paper we aim to reduce the time spent on computing heuristics. We discuss Lazy A*, a variant of A* where heuristics are evaluated lazily: only when they are essential to a decision to be made in the A* search process. We present a new rational meta-reasoning based scheme, rational lazy A*, which decides whether to compute the more expensive heuristics at all, based on a myopic value of information estimate. Both methods are examined theoretically. Empirical evaluation on several domains supports the theoretical results, and shows that lazy A* and rational lazy A* are state-of-the-art heuristic combination methods.