 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn The Statistical Representation Properties Of The Perturb-Softmax And The Perturb-Argmax Probability Distributions
Jun 04, 2024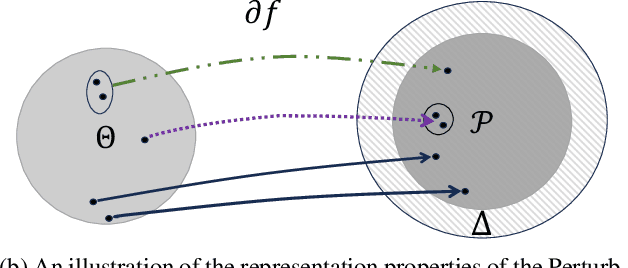

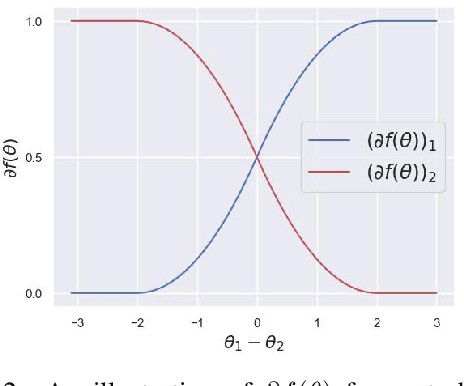
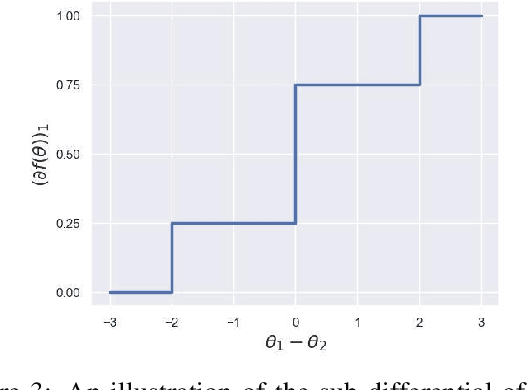
The Gumbel-Softmax probability distribution allows learning discrete tokens in generative learning, while the Gumbel-Argmax probability distribution is useful in learning discrete structures in discriminative learning. Despite the efforts invested in optimizing these probability models, their statistical properties are under-explored. In this work, we investigate their representation properties and determine for which families of parameters these probability distributions are complete, i.e., can represent any probability distribution, and minimal, i.e., can represent a probability distribution uniquely. We rely on convexity and differentiability to determine these statistical conditions and extend this framework to general probability models, such as Gaussian-Softmax and Gaussian-Argmax. We experimentally validate the qualities of these extensions, which enjoy a faster convergence rate. We conclude the analysis by identifying two sets of parameters that satisfy these assumptions and thus admit a complete and minimal representation. Our contribution is theoretical with supporting practical evaluation.
Layer Collaboration in the Forward-Forward Algorithm
May 21, 2023



Backpropagation, which uses the chain rule, is the de-facto standard algorithm for optimizing neural networks nowadays. Recently, Hinton (2022) proposed the forward-forward algorithm, a promising alternative that optimizes neural nets layer-by-layer, without propagating gradients throughout the network. Although such an approach has several advantages over back-propagation and shows promising results, the fact that each layer is being trained independently limits the optimization process. Specifically, it prevents the network's layers from collaborating to learn complex and rich features. In this work, we study layer collaboration in the forward-forward algorithm. We show that the current version of the forward-forward algorithm is suboptimal when considering information flow in the network, resulting in a lack of collaboration between layers of the network. We propose an improved version that supports layer collaboration to better utilize the network structure, while not requiring any additional assumptions or computations. We empirically demonstrate the efficacy of the proposed version when considering both information flow and objective metrics. Additionally, we provide a theoretical motivation for the proposed method, inspired by functional entropy theory.
On the Importance of Gradient Norm in PAC-Bayesian Bounds
Oct 12, 2022

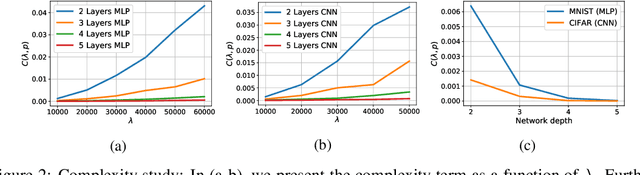
Generalization bounds which assess the difference between the true risk and the empirical risk, have been studied extensively. However, to obtain bounds, current techniques use strict assumptions such as a uniformly bounded or a Lipschitz loss function. To avoid these assumptions, in this paper, we follow an alternative approach: we relax uniform bounds assumptions by using on-average bounded loss and on-average bounded gradient norm assumptions. Following this relaxation, we propose a new generalization bound that exploits the contractivity of the log-Sobolev inequalities. These inequalities add an additional loss-gradient norm term to the generalization bound, which is intuitively a surrogate of the model complexity. We apply the proposed bound on Bayesian deep nets and empirically analyze the effect of this new loss-gradient norm term on different neural architectures.
A Functional Information Perspective on Model Interpretation
Jun 14, 2022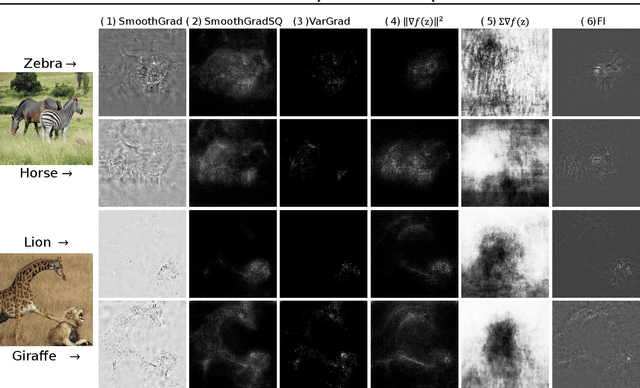
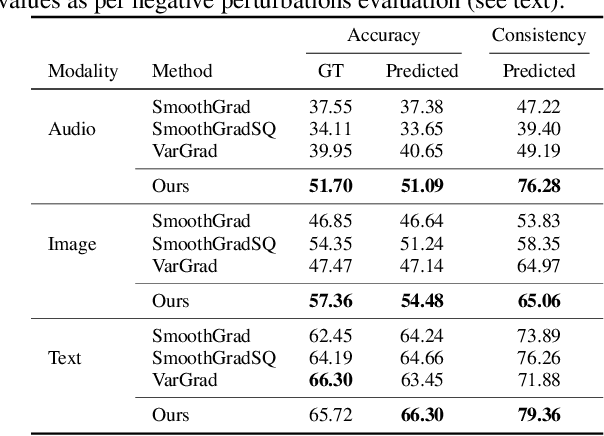

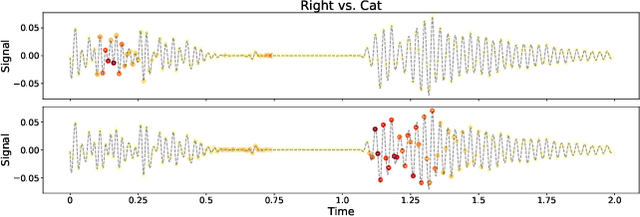
Contemporary predictive models are hard to interpret as their deep nets exploit numerous complex relations between input elements. This work suggests a theoretical framework for model interpretability by measuring the contribution of relevant features to the functional entropy of the network with respect to the input. We rely on the log-Sobolev inequality that bounds the functional entropy by the functional Fisher information with respect to the covariance of the data. This provides a principled way to measure the amount of information contribution of a subset of features to the decision function. Through extensive experiments, we show that our method surpasses existing interpretability sampling-based methods on various data signals such as image, text, and audio.
Dual Decomposition of Convex Optimization Layers for Consistent Attention in Medical Images
Jun 07, 2022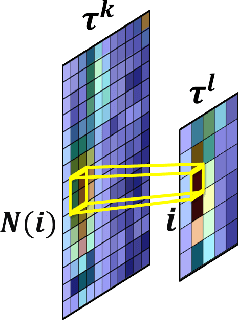
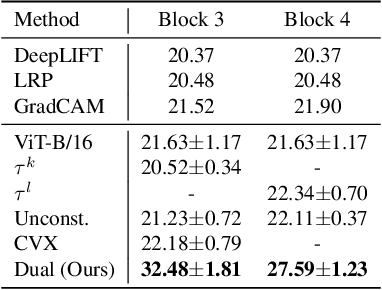
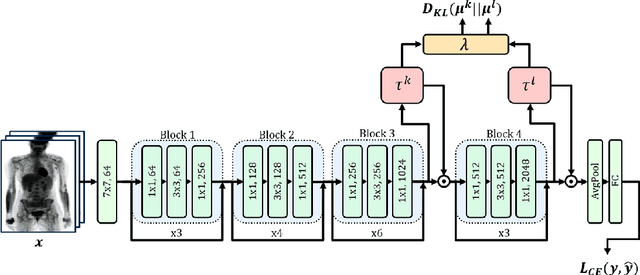
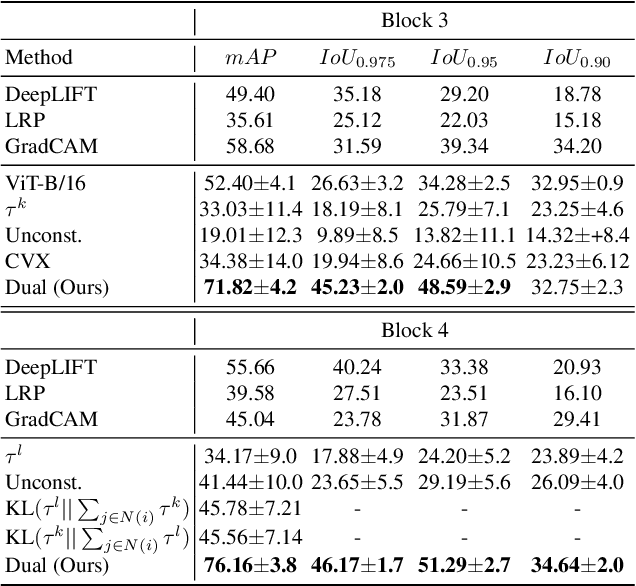
A key concern in integrating machine learning models in medicine is the ability to interpret their reasoning. Popular explainability methods have demonstrated satisfactory results in natural image recognition, yet in medical image analysis, many of these approaches provide partial and noisy explanations. Recently, attention mechanisms have shown compelling results both in their predictive performance and in their interpretable qualities. A fundamental trait of attention is that it leverages salient parts of the input which contribute to the model's prediction. To this end, our work focuses on the explanatory value of attention weight distributions. We propose a multi-layer attention mechanism that enforces consistent interpretations between attended convolutional layers using convex optimization. We apply duality to decompose the consistency constraints between the layers by reparameterizing their attention probability distributions. We further suggest learning the dual witness by optimizing with respect to our objective; thus, our implementation uses standard back-propagation, hence it is highly efficient. While preserving predictive performance, our proposed method leverages weakly annotated medical imaging data and provides complete and faithful explanations to the model's prediction.
Learning Discrete Structured Variational Auto-Encoder using Natural Evolution Strategies
May 03, 2022


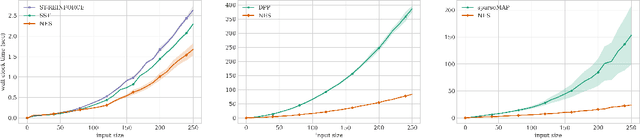
Discrete variational auto-encoders (VAEs) are able to represent semantic latent spaces in generative learning. In many real-life settings, the discrete latent space consists of high-dimensional structures, and propagating gradients through the relevant structures often requires enumerating over an exponentially large latent space. Recently, various approaches were devised to propagate approximated gradients without enumerating over the space of possible structures. In this work, we use Natural Evolution Strategies (NES), a class of gradient-free black-box optimization algorithms, to learn discrete structured VAEs. The NES algorithms are computationally appealing as they estimate gradients with forward pass evaluations only, thus they do not require to propagate gradients through their discrete structures. We demonstrate empirically that optimizing discrete structured VAEs using NES is as effective as gradient-based approximations. Lastly, we prove NES converges for non-Lipschitz functions as appear in discrete structured VAEs.
Latent Space Explanation by Intervention
Dec 09, 2021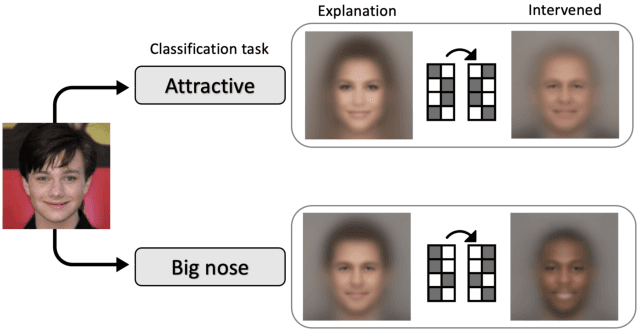

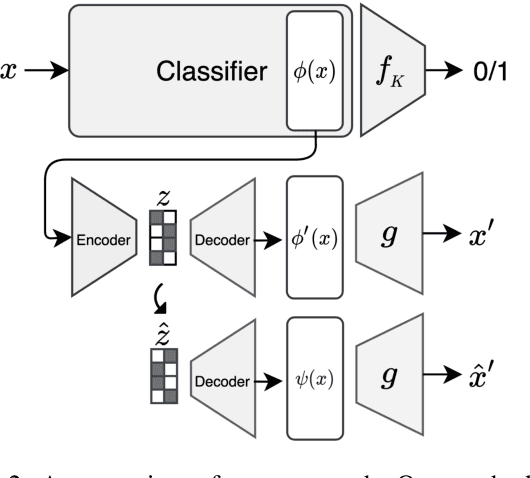

The success of deep neural nets heavily relies on their ability to encode complex relations between their input and their output. While this property serves to fit the training data well, it also obscures the mechanism that drives prediction. This study aims to reveal hidden concepts by employing an intervention mechanism that shifts the predicted class based on discrete variational autoencoders. An explanatory model then visualizes the encoded information from any hidden layer and its corresponding intervened representation. By the assessment of differences between the original representation and the intervened representation, one can determine the concepts that can alter the class, hence providing interpretability. We demonstrate the effectiveness of our approach on CelebA, where we show various visualizations for bias in the data and suggest different interventions to reveal and change bias.
Learning Generalized Gumbel-max Causal Mechanisms
Nov 11, 2021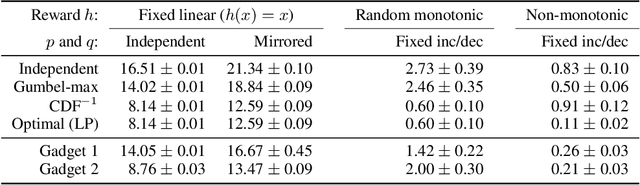
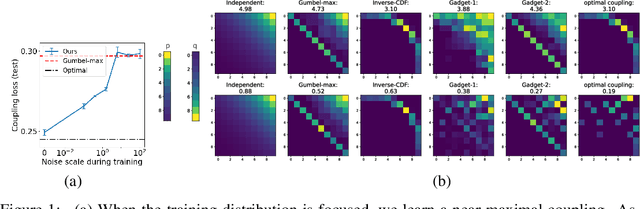

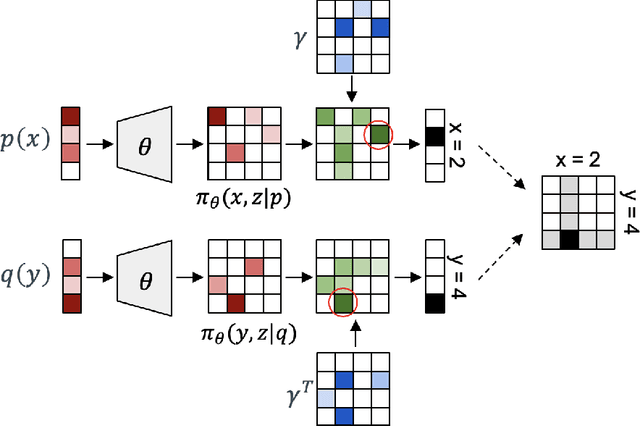
To perform counterfactual reasoning in Structural Causal Models (SCMs), one needs to know the causal mechanisms, which provide factorizations of conditional distributions into noise sources and deterministic functions mapping realizations of noise to samples. Unfortunately, the causal mechanism is not uniquely identified by data that can be gathered by observing and interacting with the world, so there remains the question of how to choose causal mechanisms. In recent work, Oberst & Sontag (2019) propose Gumbel-max SCMs, which use Gumbel-max reparameterizations as the causal mechanism due to an intuitively appealing counterfactual stability property. In this work, we instead argue for choosing a causal mechanism that is best under a quantitative criteria such as minimizing variance when estimating counterfactual treatment effects. We propose a parameterized family of causal mechanisms that generalize Gumbel-max. We show that they can be trained to minimize counterfactual effect variance and other losses on a distribution of queries of interest, yielding lower variance estimates of counterfactual treatment effect than fixed alternatives, also generalizing to queries not seen at training time.
Video and Text Matching with Conditioned Embeddings
Oct 21, 2021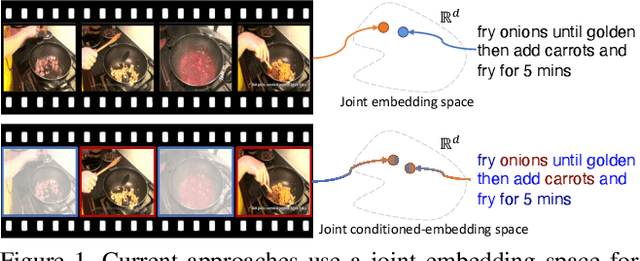
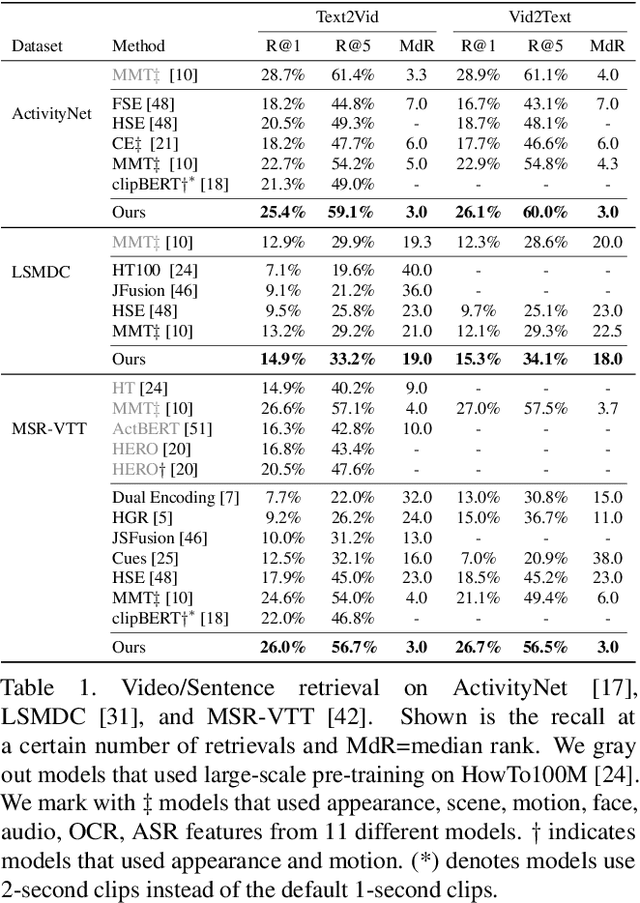
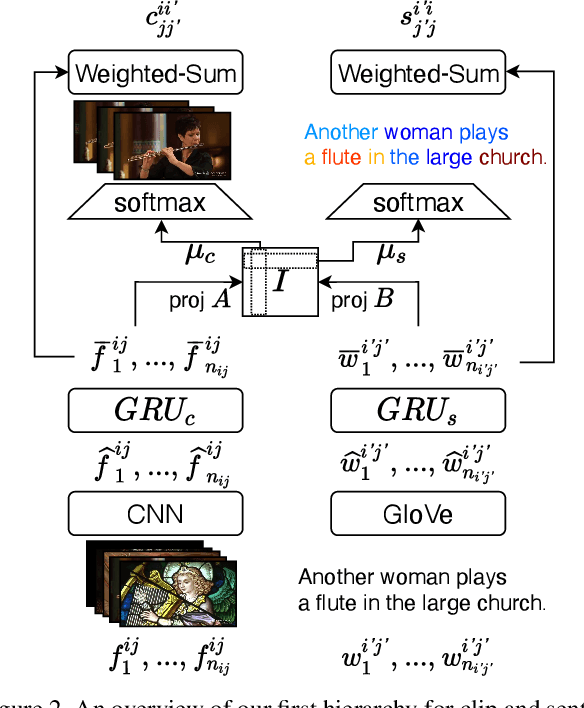

We present a method for matching a text sentence from a given corpus to a given video clip and vice versa. Traditionally video and text matching is done by learning a shared embedding space and the encoding of one modality is independent of the other. In this work, we encode the dataset data in a way that takes into account the query's relevant information. The power of the method is demonstrated to arise from pooling the interaction data between words and frames. Since the encoding of the video clip depends on the sentence compared to it, the representation needs to be recomputed for each potential match. To this end, we propose an efficient shallow neural network. Its training employs a hierarchical triplet loss that is extendable to paragraph/video matching. The method is simple, provides explainability, and achieves state-of-the-art results for both sentence-clip and video-text by a sizable margin across five different datasets: ActivityNet, DiDeMo, YouCook2, MSR-VTT, and LSMDC. We also show that our conditioned representation can be transferred to video-guided machine translation, where we improved the current results on VATEX. Source code is available at https://github.com/AmeenAli/VideoMatch.
Mixing between the Cross Entropy and the Expectation Loss Terms
Sep 12, 2021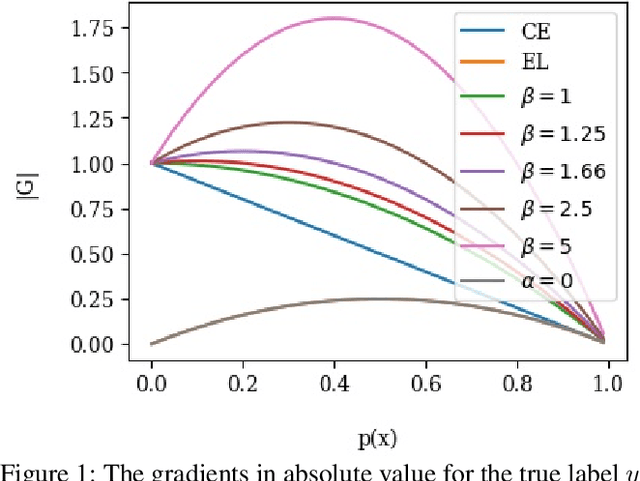
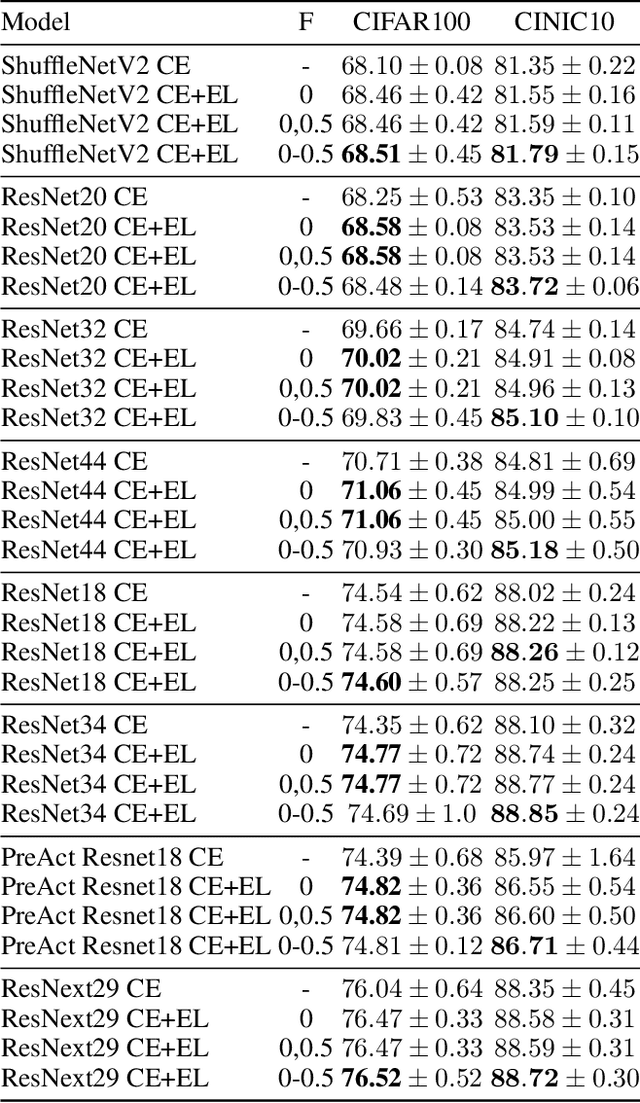
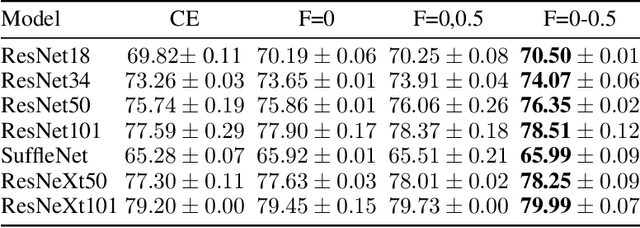
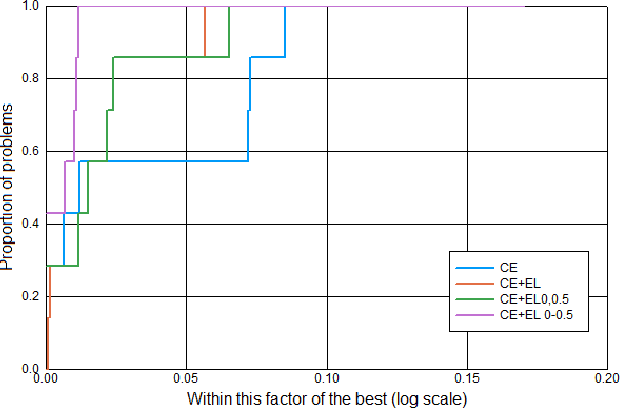
The cross entropy loss is widely used due to its effectiveness and solid theoretical grounding. However, as training progresses, the loss tends to focus on hard to classify samples, which may prevent the network from obtaining gains in performance. While most work in the field suggest ways to classify hard negatives, we suggest to strategically leave hard negatives behind, in order to focus on misclassified samples with higher probabilities. We show that adding to the optimization goal the expectation loss, which is a better approximation of the zero-one loss, helps the network to achieve better accuracy. We, therefore, propose to shift between the two losses during training, focusing more on the expectation loss gradually during the later stages of training. Our experiments show that the new training protocol improves performance across a diverse set of classification domains, including computer vision, natural language processing, tabular data, and sequences. Our code and scripts are available at supplementary.