 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer Collaboration in the Forward-Forward Algorithm
May 21, 2023



Backpropagation, which uses the chain rule, is the de-facto standard algorithm for optimizing neural networks nowadays. Recently, Hinton (2022) proposed the forward-forward algorithm, a promising alternative that optimizes neural nets layer-by-layer, without propagating gradients throughout the network. Although such an approach has several advantages over back-propagation and shows promising results, the fact that each layer is being trained independently limits the optimization process. Specifically, it prevents the network's layers from collaborating to learn complex and rich features. In this work, we study layer collaboration in the forward-forward algorithm. We show that the current version of the forward-forward algorithm is suboptimal when considering information flow in the network, resulting in a lack of collaboration between layers of the network. We propose an improved version that supports layer collaboration to better utilize the network structure, while not requiring any additional assumptions or computations. We empirically demonstrate the efficacy of the proposed version when considering both information flow and objective metrics. Additionally, we provide a theoretical motivation for the proposed method, inspired by functional entropy theory.
Transplantation of Conversational Speaking Style with Interjections in Sequence-to-Sequence Speech Synthesis
Jul 25, 2022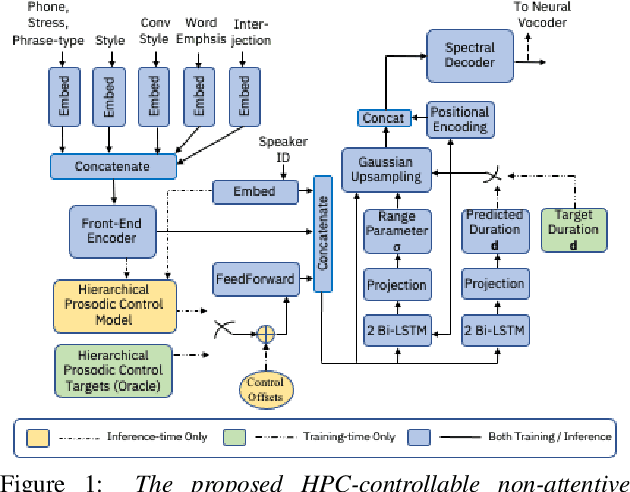

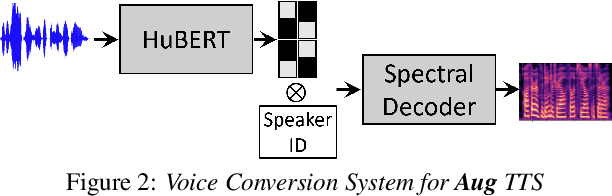

Sequence-to-Sequence Text-to-Speech architectures that directly generate low level acoustic features from phonetic sequences are known to produce natural and expressive speech when provided with adequate amounts of training data. Such systems can learn and transfer desired speaking styles from one seen speaker to another (in multi-style multi-speaker settings), which is highly desirable for creating scalable and customizable Human-Computer Interaction systems. In this work we explore one-to-many style transfer from a dedicated single-speaker conversational corpus with style nuances and interjections. We elaborate on the corpus design and explore the feasibility of such style transfer when assisted with Voice-Conversion-based data augmentation. In a set of subjective listening experiments, this approach resulted in high-fidelity style transfer with no quality degradation. However, a certain voice persona shift was observed, requiring further improvements in voice conversion.
Latent Space Explanation by Intervention
Dec 09, 2021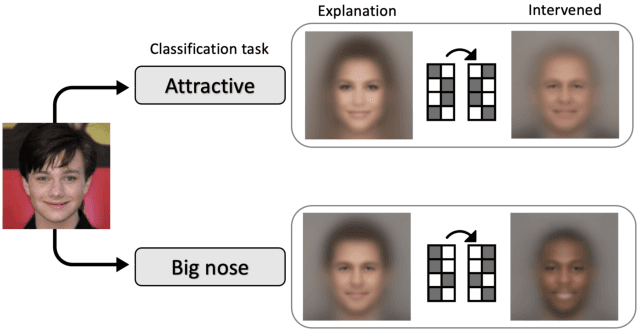

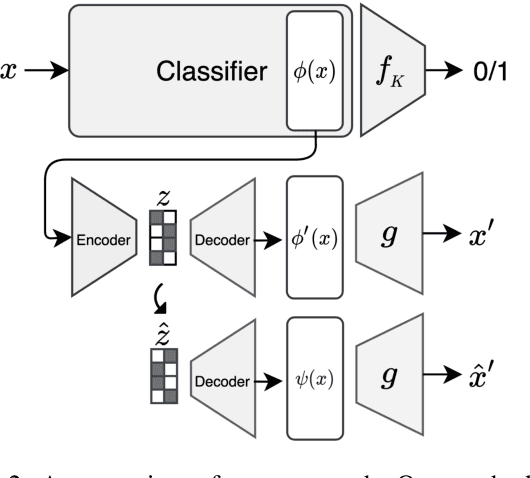

The success of deep neural nets heavily relies on their ability to encode complex relations between their input and their output. While this property serves to fit the training data well, it also obscures the mechanism that drives prediction. This study aims to reveal hidden concepts by employing an intervention mechanism that shifts the predicted class based on discrete variational autoencoders. An explanatory model then visualizes the encoded information from any hidden layer and its corresponding intervened representation. By the assessment of differences between the original representation and the intervened representation, one can determine the concepts that can alter the class, hence providing interpretability. We demonstrate the effectiveness of our approach on CelebA, where we show various visualizations for bias in the data and suggest different interventions to reveal and change bias.
Learning Generalized Gumbel-max Causal Mechanisms
Nov 11, 2021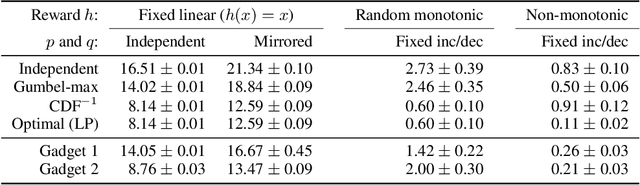
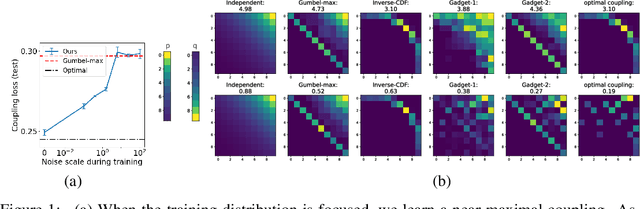

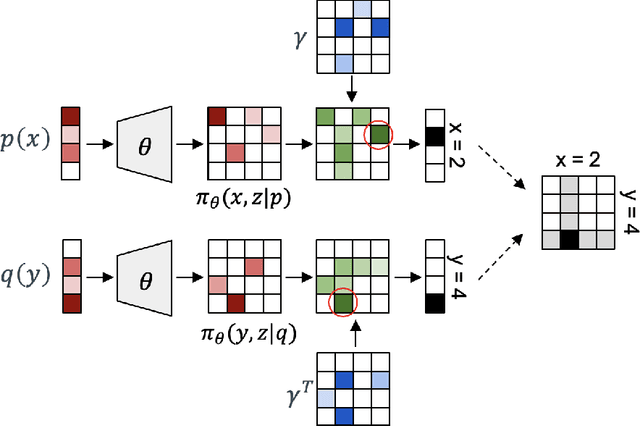
To perform counterfactual reasoning in Structural Causal Models (SCMs), one needs to know the causal mechanisms, which provide factorizations of conditional distributions into noise sources and deterministic functions mapping realizations of noise to samples. Unfortunately, the causal mechanism is not uniquely identified by data that can be gathered by observing and interacting with the world, so there remains the question of how to choose causal mechanisms. In recent work, Oberst & Sontag (2019) propose Gumbel-max SCMs, which use Gumbel-max reparameterizations as the causal mechanism due to an intuitively appealing counterfactual stability property. In this work, we instead argue for choosing a causal mechanism that is best under a quantitative criteria such as minimizing variance when estimating counterfactual treatment effects. We propose a parameterized family of causal mechanisms that generalize Gumbel-max. We show that they can be trained to minimize counterfactual effect variance and other losses on a distribution of queries of interest, yielding lower variance estimates of counterfactual treatment effect than fixed alternatives, also generalizing to queries not seen at training time.
Direct Policy Gradients: Direct Optimization of Policies in Discrete Action Spaces
Jun 14, 2019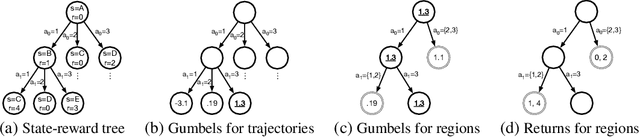
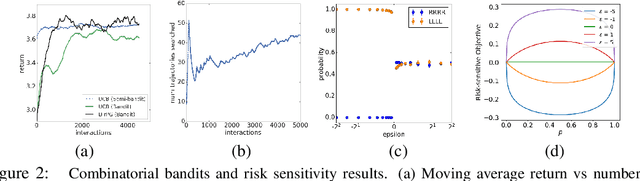
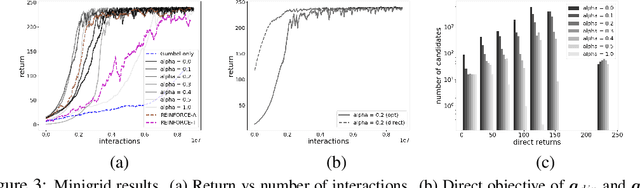
Direct optimization is an appealing approach to differentiating through discrete quantities. Rather than relying on REINFORCE or continuous relaxations of discrete structures, it uses optimization in discrete space to compute gradients through a discrete argmax operation. In this paper, we develop reinforcement learning algorithms that use direct optimization to compute gradients of the expected return in environments with discrete actions. We call the resulting algorithms "direct policy gradient" algorithms and investigate their properties, showing that there is a built-in variance reduction technique and that a parameter that was previously viewed as a numerical approximation can be interpreted as controlling risk sensitivity. We also tackle challenges in algorithm design, leveraging ideas from A$^\star$ Sampling to develop a practical algorithm. Empirically, we show that the algorithm performs well in illustrative domains, and that it can make use of domain knowledge about upper bounds on return-to-go to speed up training.
Direct Optimization through $\arg \max$ for Discrete Variational Auto-Encoder
Oct 11, 2018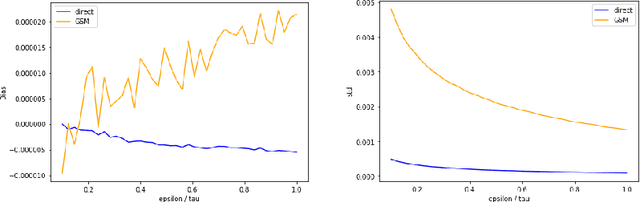

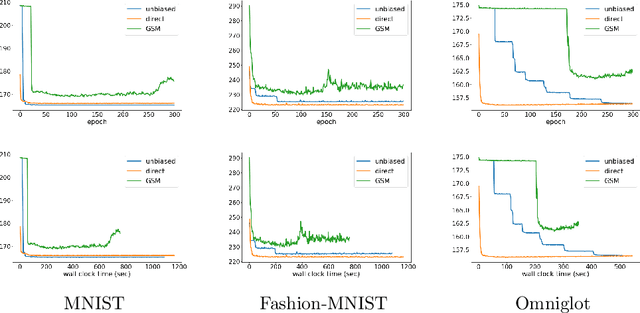
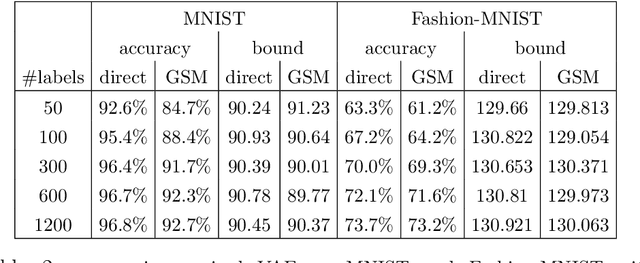
Reparameterization of variational auto-encoders with continuous latent spaces is an effective method for reducing the variance of their gradient estimates. However, using the same approach when latent variables are discrete is problematic, due to the resulting non-differentiable objective. In this work, we present a direct optimization method that propagates gradients through a non-differentiable $\arg \max$ prediction operation. We apply this method to discrete variational auto-encoders, by modeling a discrete random variable by the $\arg \max$ function of the Gumbel-Max perturbation model.