 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePC Layer: Polynomial Weight Preconditioning for Improving LLM Pre-Training
Jun 04, 2026We propose a preconditioning (PC) layer, a weight parameterization via polynomial preconditioner that ensures stable weight conditioning throughout LLM training. The PC module reshapes the singular-value spectrum of weight matrices via low-degree polynomial preconditioning. After training, the preconditioned weights can be merged back into the original architecture, incurring no inference overhead. We demonstrate the advantage of the proposed PC layer over standard transformers in Llama-1B pre-training, for both the AdamW and Muon optimizers. Theoretically, we justify this spectrum-control principle by proving that uniformly bounding each layer's singular values ensures geometric convergence of gradient descent to global minima, for certain deep linear networks. Our code is available at https://github.com/Empath-aln/PC-layer.
T-REN: Learning Text-Aligned Region Tokens Improves Dense Vision-Language Alignment and Scalability
Apr 20, 2026Despite recent progress, vision-language encoders struggle with two core limitations: (1) weak alignment between language and dense vision features, which hurts tasks like open-vocabulary semantic segmentation; and (2) high token counts for fine-grained visual representations, which limits scalability to long videos. This work addresses both limitations. We propose T-REN (Text-aligned Region Encoder Network), an efficient encoder that maps visual data to a compact set of text-aligned region-level representations (or region tokens). T-REN achieves this through a lightweight network added on top of a frozen vision backbone, trained to pool patch-level representations within each semantic region into region tokens and align them with region-level text annotations. With only 3.7% additional parameters compared to the vision-language backbone, this design yields substantially stronger dense cross-modal understanding while reducing the token count by orders of magnitude. Specifically, T-REN delivers +5.9 mIoU on ADE20K open-vocabulary segmentation, +18.4% recall on COCO object-level text-image retrieval, +15.6% recall on Ego4D video object localization, and +17.6% mIoU on VSPW video scene parsing, all while reducing token counts by more than 24x for images and 187x for videos compared to the patch-based vision-language backbone. The code and model are available at https://github.com/savya08/T-REN.
Hierarchical Rectified Flow Matching with Mini-Batch Couplings
Jul 17, 2025Flow matching has emerged as a compelling generative modeling approach that is widely used across domains. To generate data via a flow matching model, an ordinary differential equation (ODE) is numerically solved via forward integration of the modeled velocity field. To better capture the multi-modality that is inherent in typical velocity fields, hierarchical flow matching was recently introduced. It uses a hierarchy of ODEs that are numerically integrated when generating data. This hierarchy of ODEs captures the multi-modal velocity distribution just like vanilla flow matching is capable of modeling a multi-modal data distribution. While this hierarchy enables to model multi-modal velocity distributions, the complexity of the modeled distribution remains identical across levels of the hierarchy. In this paper, we study how to gradually adjust the complexity of the distributions across different levels of the hierarchy via mini-batch couplings. We show the benefits of mini-batch couplings in hierarchical rectified flow matching via compelling results on synthetic and imaging data. Code is available at https://riccizz.github.io/HRF_coupling.
3D-Fixup: Advancing Photo Editing with 3D Priors
May 15, 2025



Despite significant advances in modeling image priors via diffusion models, 3D-aware image editing remains challenging, in part because the object is only specified via a single image. To tackle this challenge, we propose 3D-Fixup, a new framework for editing 2D images guided by learned 3D priors. The framework supports difficult editing situations such as object translation and 3D rotation. To achieve this, we leverage a training-based approach that harnesses the generative power of diffusion models. As video data naturally encodes real-world physical dynamics, we turn to video data for generating training data pairs, i.e., a source and a target frame. Rather than relying solely on a single trained model to infer transformations between source and target frames, we incorporate 3D guidance from an Image-to-3D model, which bridges this challenging task by explicitly projecting 2D information into 3D space. We design a data generation pipeline to ensure high-quality 3D guidance throughout training. Results show that by integrating these 3D priors, 3D-Fixup effectively supports complex, identity coherent 3D-aware edits, achieving high-quality results and advancing the application of diffusion models in realistic image manipulation. The code is provided at https://3dfixup.github.io/
DiT-Air: Revisiting the Efficiency of Diffusion Model Architecture Design in Text to Image Generation
Mar 13, 2025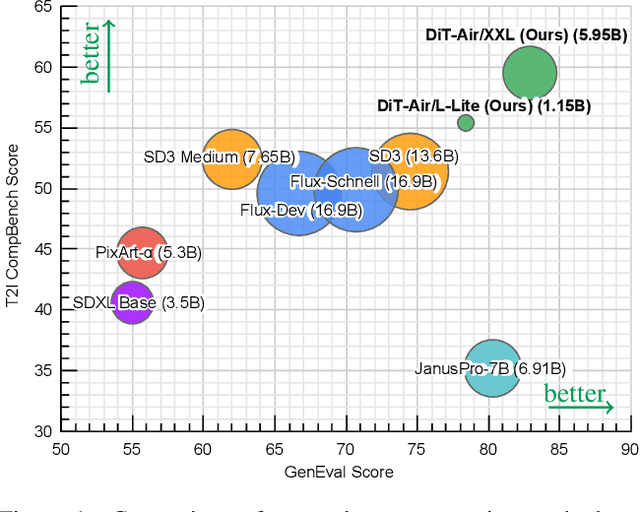



In this work, we empirically study Diffusion Transformers (DiTs) for text-to-image generation, focusing on architectural choices, text-conditioning strategies, and training protocols. We evaluate a range of DiT-based architectures--including PixArt-style and MMDiT variants--and compare them with a standard DiT variant which directly processes concatenated text and noise inputs. Surprisingly, our findings reveal that the performance of standard DiT is comparable with those specialized models, while demonstrating superior parameter-efficiency, especially when scaled up. Leveraging the layer-wise parameter sharing strategy, we achieve a further reduction of 66% in model size compared to an MMDiT architecture, with minimal performance impact. Building on an in-depth analysis of critical components such as text encoders and Variational Auto-Encoders (VAEs), we introduce DiT-Air and DiT-Air-Lite. With supervised and reward fine-tuning, DiT-Air achieves state-of-the-art performance on GenEval and T2I CompBench, while DiT-Air-Lite remains highly competitive, surpassing most existing models despite its compact size.
Towards Hierarchical Rectified Flow
Feb 24, 2025We formulate a hierarchical rectified flow to model data distributions. It hierarchically couples multiple ordinary differential equations (ODEs) and defines a time-differentiable stochastic process that generates a data distribution from a known source distribution. Each ODE resembles the ODE that is solved in a classic rectified flow, but differs in its domain, i.e., location, velocity, acceleration, etc. Unlike the classic rectified flow formulation, which formulates a single ODE in the location domain and only captures the expected velocity field (sufficient to capture a multi-modal data distribution), the hierarchical rectified flow formulation models the multi-modal random velocity field, acceleration field, etc., in their entirety. This more faithful modeling of the random velocity field enables integration paths to intersect when the underlying ODE is solved during data generation. Intersecting paths in turn lead to integration trajectories that are more straight than those obtained in the classic rectified flow formulation, where integration paths cannot intersect. This leads to modeling of data distributions with fewer neural function evaluations. We empirically verify this on synthetic 1D and 2D data as well as MNIST, CIFAR-10, and ImageNet-32 data. Code is available at: https://riccizz.github.io/HRF/.
Layer Collaboration in the Forward-Forward Algorithm
May 21, 2023



Backpropagation, which uses the chain rule, is the de-facto standard algorithm for optimizing neural networks nowadays. Recently, Hinton (2022) proposed the forward-forward algorithm, a promising alternative that optimizes neural nets layer-by-layer, without propagating gradients throughout the network. Although such an approach has several advantages over back-propagation and shows promising results, the fact that each layer is being trained independently limits the optimization process. Specifically, it prevents the network's layers from collaborating to learn complex and rich features. In this work, we study layer collaboration in the forward-forward algorithm. We show that the current version of the forward-forward algorithm is suboptimal when considering information flow in the network, resulting in a lack of collaboration between layers of the network. We propose an improved version that supports layer collaboration to better utilize the network structure, while not requiring any additional assumptions or computations. We empirically demonstrate the efficacy of the proposed version when considering both information flow and objective metrics. Additionally, we provide a theoretical motivation for the proposed method, inspired by functional entropy theory.
AutoFocusFormer: Image Segmentation off the Grid
Apr 24, 2023Real world images often have highly imbalanced content density. Some areas are very uniform, e.g., large patches of blue sky, while other areas are scattered with many small objects. Yet, the commonly used successive grid downsampling strategy in convolutional deep networks treats all areas equally. Hence, small objects are represented in very few spatial locations, leading to worse results in tasks such as segmentation. Intuitively, retaining more pixels representing small objects during downsampling helps to preserve important information. To achieve this, we propose AutoFocusFormer (AFF), a local-attention transformer image recognition backbone, which performs adaptive downsampling by learning to retain the most important pixels for the task. Since adaptive downsampling generates a set of pixels irregularly distributed on the image plane, we abandon the classic grid structure. Instead, we develop a novel point-based local attention block, facilitated by a balanced clustering module and a learnable neighborhood merging module, which yields representations for our point-based versions of state-of-the-art segmentation heads. Experiments show that our AutoFocusFormer (AFF) improves significantly over baseline models of similar sizes.
Diffusion Probabilistic Fields
Mar 01, 2023



Diffusion probabilistic models have quickly become a major approach for generative modeling of images, 3D geometry, video and other domains. However, to adapt diffusion generative modeling to these domains the denoising network needs to be carefully designed for each domain independently, oftentimes under the assumption that data lives in a Euclidean grid. In this paper we introduce Diffusion Probabilistic Fields (DPF), a diffusion model that can learn distributions over continuous functions defined over metric spaces, commonly known as fields. We extend the formulation of diffusion probabilistic models to deal with this field parametrization in an explicit way, enabling us to define an end-to-end learning algorithm that side-steps the requirement of representing fields with latent vectors as in previous approaches (Dupont et al., 2022a; Du et al., 2021). We empirically show that, while using the same denoising network, DPF effectively deals with different modalities like 2D images and 3D geometry, in addition to modeling distributions over fields defined on non-Euclidean metric spaces.
DigGAN: Discriminator gradIent Gap Regularization for GAN Training with Limited Data
Nov 27, 2022Generative adversarial nets (GANs) have been remarkably successful at learning to sample from distributions specified by a given dataset, particularly if the given dataset is reasonably large compared to its dimensionality. However, given limited data, classical GANs have struggled, and strategies like output-regularization, data-augmentation, use of pre-trained models and pruning have been shown to lead to improvements. Notably, the applicability of these strategies is 1) often constrained to particular settings, e.g., availability of a pretrained GAN; or 2) increases training time, e.g., when using pruning. In contrast, we propose a Discriminator gradIent Gap regularized GAN (DigGAN) formulation which can be added to any existing GAN. DigGAN augments existing GANs by encouraging to narrow the gap between the norm of the gradient of a discriminator's prediction w.r.t.\ real images and w.r.t.\ the generated samples. We observe this formulation to avoid bad attractors within the GAN loss landscape, and we find DigGAN to significantly improve the results of GAN training when limited data is available. Code is available at \url{https://github.com/AilsaF/DigGAN}.