 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanisms of Projective Composition of Diffusion Models
Feb 06, 2025

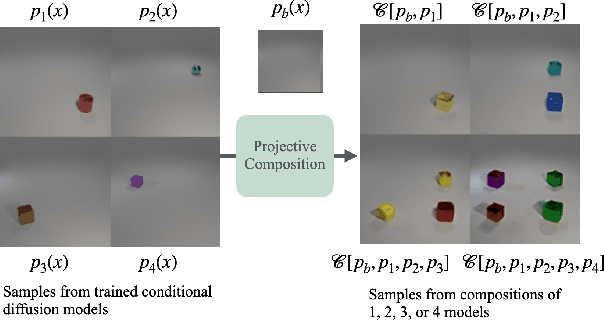
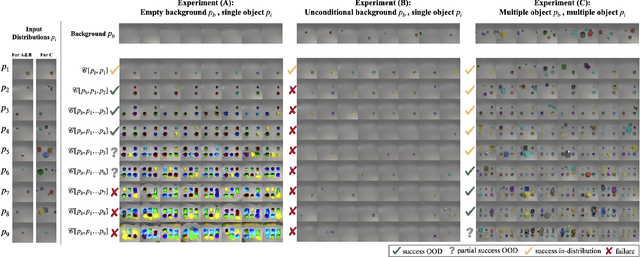
We study the theoretical foundations of composition in diffusion models, with a particular focus on out-of-distribution extrapolation and length-generalization. Prior work has shown that composing distributions via linear score combination can achieve promising results, including length-generalization in some cases (Du et al., 2023; Liu et al., 2022). However, our theoretical understanding of how and why such compositions work remains incomplete. In fact, it is not even entirely clear what it means for composition to "work". This paper starts to address these fundamental gaps. We begin by precisely defining one possible desired result of composition, which we call projective composition. Then, we investigate: (1) when linear score combinations provably achieve projective composition, (2) whether reverse-diffusion sampling can generate the desired composition, and (3) the conditions under which composition fails. Finally, we connect our theoretical analysis to prior empirical observations where composition has either worked or failed, for reasons that were unclear at the time.
Multimodal Autoregressive Pre-training of Large Vision Encoders
Nov 21, 2024



We introduce a novel method for pre-training of large-scale vision encoders. Building on recent advancements in autoregressive pre-training of vision models, we extend this framework to a multimodal setting, i.e., images and text. In this paper, we present AIMV2, a family of generalist vision encoders characterized by a straightforward pre-training process, scalability, and remarkable performance across a range of downstream tasks. This is achieved by pairing the vision encoder with a multimodal decoder that autoregressively generates raw image patches and text tokens. Our encoders excel not only in multimodal evaluations but also in vision benchmarks such as localization, grounding, and classification. Notably, our AIMV2-3B encoder achieves 89.5% accuracy on ImageNet-1k with a frozen trunk. Furthermore, AIMV2 consistently outperforms state-of-the-art contrastive models (e.g., CLIP, SigLIP) in multimodal image understanding across diverse settings.
Kaleido Diffusion: Improving Conditional Diffusion Models with Autoregressive Latent Modeling
May 31, 2024Diffusion models have emerged as a powerful tool for generating high-quality images from textual descriptions. Despite their successes, these models often exhibit limited diversity in the sampled images, particularly when sampling with a high classifier-free guidance weight. To address this issue, we present Kaleido, a novel approach that enhances the diversity of samples by incorporating autoregressive latent priors. Kaleido integrates an autoregressive language model that encodes the original caption and generates latent variables, serving as abstract and intermediary representations for guiding and facilitating the image generation process. In this paper, we explore a variety of discrete latent representations, including textual descriptions, detection bounding boxes, object blobs, and visual tokens. These representations diversify and enrich the input conditions to the diffusion models, enabling more diverse outputs. Our experimental results demonstrate that Kaleido effectively broadens the diversity of the generated image samples from a given textual description while maintaining high image quality. Furthermore, we show that Kaleido adheres closely to the guidance provided by the generated latent variables, demonstrating its capability to effectively control and direct the image generation process.
CTRLorALTer: Conditional LoRAdapter for Efficient 0-Shot Control & Altering of T2I Models
May 13, 2024Text-to-image generative models have become a prominent and powerful tool that excels at generating high-resolution realistic images. However, guiding the generative process of these models to consider detailed forms of conditioning reflecting style and/or structure information remains an open problem. In this paper, we present LoRAdapter, an approach that unifies both style and structure conditioning under the same formulation using a novel conditional LoRA block that enables zero-shot control. LoRAdapter is an efficient, powerful, and architecture-agnostic approach to condition text-to-image diffusion models, which enables fine-grained control conditioning during generation and outperforms recent state-of-the-art approaches
Many-to-many Image Generation with Auto-regressive Diffusion Models
Apr 03, 2024


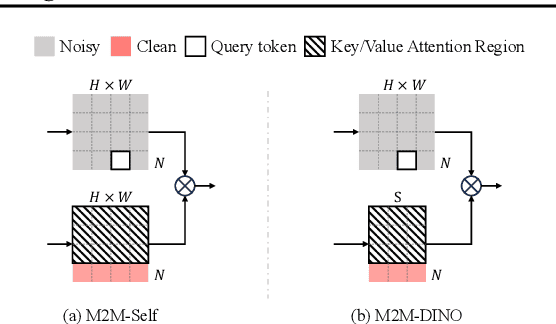
Recent advancements in image generation have made significant progress, yet existing models present limitations in perceiving and generating an arbitrary number of interrelated images within a broad context. This limitation becomes increasingly critical as the demand for multi-image scenarios, such as multi-view images and visual narratives, grows with the expansion of multimedia platforms. This paper introduces a domain-general framework for many-to-many image generation, capable of producing interrelated image series from a given set of images, offering a scalable solution that obviates the need for task-specific solutions across different multi-image scenarios. To facilitate this, we present MIS, a novel large-scale multi-image dataset, containing 12M synthetic multi-image samples, each with 25 interconnected images. Utilizing Stable Diffusion with varied latent noises, our method produces a set of interconnected images from a single caption. Leveraging MIS, we learn M2M, an autoregressive model for many-to-many generation, where each image is modeled within a diffusion framework. Throughout training on the synthetic MIS, the model excels in capturing style and content from preceding images - synthetic or real - and generates novel images following the captured patterns. Furthermore, through task-specific fine-tuning, our model demonstrates its adaptability to various multi-image generation tasks, including Novel View Synthesis and Visual Procedure Generation.
LiDAR: Sensing Linear Probing Performance in Joint Embedding SSL Architectures
Dec 07, 2023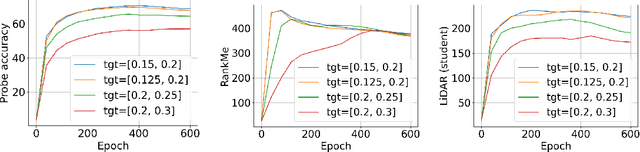
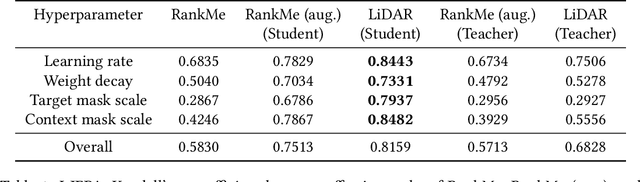

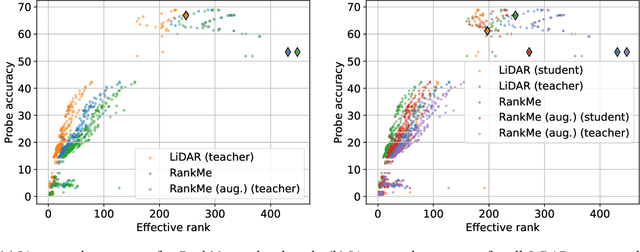
Joint embedding (JE) architectures have emerged as a promising avenue for acquiring transferable data representations. A key obstacle to using JE methods, however, is the inherent challenge of evaluating learned representations without access to a downstream task, and an annotated dataset. Without efficient and reliable evaluation, it is difficult to iterate on architectural and training choices for JE methods. In this paper, we introduce LiDAR (Linear Discriminant Analysis Rank), a metric designed to measure the quality of representations within JE architectures. Our metric addresses several shortcomings of recent approaches based on feature covariance rank by discriminating between informative and uninformative features. In essence, LiDAR quantifies the rank of the Linear Discriminant Analysis (LDA) matrix associated with the surrogate SSL task -- a measure that intuitively captures the information content as it pertains to solving the SSL task. We empirically demonstrate that LiDAR significantly surpasses naive rank based approaches in its predictive power of optimal hyperparameters. Our proposed criterion presents a more robust and intuitive means of assessing the quality of representations within JE architectures, which we hope facilitates broader adoption of these powerful techniques in various domains.
Generating Molecular Conformer Fields
Dec 05, 2023



In this paper we tackle the problem of generating conformers of a molecule in 3D space given its molecular graph. We parameterize these conformers as continuous functions that map elements from the molecular graph to points in 3D space. We then formulate the problem of learning to generate conformers as learning a distribution over these functions using a diffusion generative model, called Molecular Conformer Fields (MCF). Our approach is simple and scalable, and achieves state-of-the-art performance on challenging molecular conformer generation benchmarks while making no assumptions about the explicit structure of molecules (e.g. modeling torsional angles). MCF represents an advance in extending diffusion models to handle complex scientific problems in a conceptually simple, scalable and effective manner.
Is Generalized Dynamic Novel View Synthesis from Monocular Videos Possible Today?
Oct 12, 2023



Rendering scenes observed in a monocular video from novel viewpoints is a challenging problem. For static scenes the community has studied both scene-specific optimization techniques, which optimize on every test scene, and generalized techniques, which only run a deep net forward pass on a test scene. In contrast, for dynamic scenes, scene-specific optimization techniques exist, but, to our best knowledge, there is currently no generalized method for dynamic novel view synthesis from a given monocular video. To answer whether generalized dynamic novel view synthesis from monocular videos is possible today, we establish an analysis framework based on existing techniques and work toward the generalized approach. We find a pseudo-generalized process without scene-specific appearance optimization is possible, but geometrically and temporally consistent depth estimates are needed. Despite no scene-specific appearance optimization, the pseudo-generalized approach improves upon some scene-specific methods.
Manifold Diffusion Fields
May 24, 2023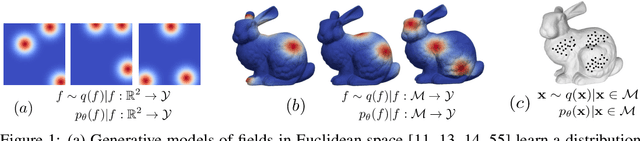

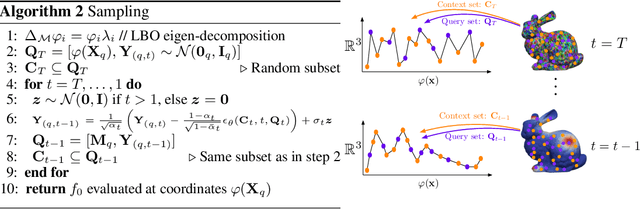
We present Manifold Diffusion Fields (MDF), an approach to learn generative models of continuous functions defined over Riemannian manifolds. Leveraging insights from spectral geometry analysis, we define an intrinsic coordinate system on the manifold via the eigen-functions of the Laplace-Beltrami Operator. MDF represents functions using an explicit parametrization formed by a set of multiple input-output pairs. Our approach allows to sample continuous functions on manifolds and is invariant with respect to rigid and isometric transformations of the manifold. Empirical results on several datasets and manifolds show that MDF can capture distributions of such functions with better diversity and fidelity than previous approaches.
Diffusion Probabilistic Fields
Mar 01, 2023



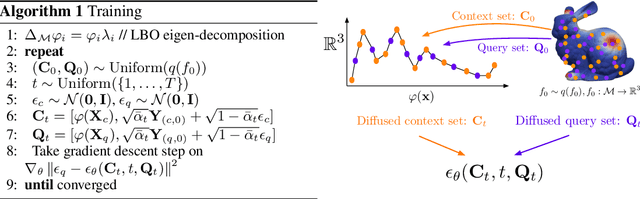
Diffusion probabilistic models have quickly become a major approach for generative modeling of images, 3D geometry, video and other domains. However, to adapt diffusion generative modeling to these domains the denoising network needs to be carefully designed for each domain independently, oftentimes under the assumption that data lives in a Euclidean grid. In this paper we introduce Diffusion Probabilistic Fields (DPF), a diffusion model that can learn distributions over continuous functions defined over metric spaces, commonly known as fields. We extend the formulation of diffusion probabilistic models to deal with this field parametrization in an explicit way, enabling us to define an end-to-end learning algorithm that side-steps the requirement of representing fields with latent vectors as in previous approaches (Dupont et al., 2022a; Du et al., 2021). We empirically show that, while using the same denoising network, DPF effectively deals with different modalities like 2D images and 3D geometry, in addition to modeling distributions over fields defined on non-Euclidean metric spaces.