 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompleted Hyperparameter Transfer across Modules, Width, Depth, Batch and Duration
Dec 26, 2025Hyperparameter tuning can dramatically impact training stability and final performance of large-scale models. Recent works on neural network parameterisations, such as $μ$P, have enabled transfer of optimal global hyperparameters across model sizes. These works propose an empirical practice of search for optimal global base hyperparameters at a small model size, and transfer to a large size. We extend these works in two key ways. To handle scaling along most important scaling axes, we propose the Complete$^{(d)}$ Parameterisation that unifies scaling in width and depth -- using an adaptation of CompleteP -- as well as in batch-size and training duration. Secondly, with our parameterisation, we investigate per-module hyperparameter optimisation and transfer. We characterise the empirical challenges of navigating the high-dimensional hyperparameter landscape, and propose practical guidelines for tackling this optimisation problem. We demonstrate that, with the right parameterisation, hyperparameter transfer holds even in the per-module hyperparameter regime. Our study covers an extensive range of optimisation hyperparameters of modern models: learning rates, AdamW parameters, weight decay, initialisation scales, and residual block multipliers. Our experiments demonstrate significant training speed improvements in Large Language Models with the transferred per-module hyperparameters.
The Data-Quality Illusion: Rethinking Classifier-Based Quality Filtering for LLM Pretraining
Oct 02, 2025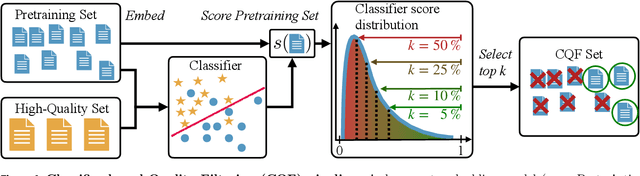
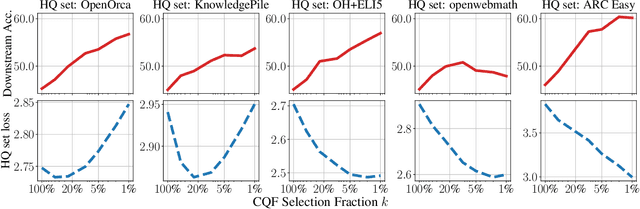
Large-scale models are pretrained on massive web-crawled datasets containing documents of mixed quality, making data filtering essential. A popular method is Classifier-based Quality Filtering (CQF), which trains a binary classifier to distinguish between pretraining data and a small, high-quality set. It assigns each pretraining document a quality score defined as the classifier's score and retains only the top-scoring ones. We provide an in-depth analysis of CQF. We show that while CQF improves downstream task performance, it does not necessarily enhance language modeling on the high-quality dataset. We explain this paradox by the fact that CQF implicitly filters the high-quality dataset as well. We further compare the behavior of models trained with CQF to those trained on synthetic data of increasing quality, obtained via random token permutations, and find starkly different trends. Our results challenge the view that CQF captures a meaningful notion of data quality.
The Geometries of Truth Are Orthogonal Across Tasks
Jun 10, 2025Large Language Models (LLMs) have demonstrated impressive generalization capabilities across various tasks, but their claim to practical relevance is still mired by concerns on their reliability. Recent works have proposed examining the activations produced by an LLM at inference time to assess whether its answer to a question is correct. Some works claim that a "geometry of truth" can be learned from examples, in the sense that the activations that generate correct answers can be distinguished from those leading to mistakes with a linear classifier. In this work, we underline a limitation of these approaches: we observe that these "geometries of truth" are intrinsically task-dependent and fail to transfer across tasks. More precisely, we show that linear classifiers trained across distinct tasks share little similarity and, when trained with sparsity-enforcing regularizers, have almost disjoint supports. We show that more sophisticated approaches (e.g., using mixtures of probes and tasks) fail to overcome this limitation, likely because activation vectors commonly used to classify answers form clearly separated clusters when examined across tasks.
On Fitting Flow Models with Large Sinkhorn Couplings
Jun 05, 2025Flow models transform data gradually from one modality (e.g. noise) onto another (e.g. images). Such models are parameterized by a time-dependent velocity field, trained to fit segments connecting pairs of source and target points. When the pairing between source and target points is given, training flow models boils down to a supervised regression problem. When no such pairing exists, as is the case when generating data from noise, training flows is much harder. A popular approach lies in picking source and target points independently. This can, however, lead to velocity fields that are slow to train, but also costly to integrate at inference time. In theory, one would greatly benefit from training flow models by sampling pairs from an optimal transport (OT) measure coupling source and target, since this would lead to a highly efficient flow solving the Benamou and Brenier dynamical OT problem. In practice, recent works have proposed to sample mini-batches of $n$ source and $n$ target points and reorder them using an OT solver to form better pairs. These works have advocated using batches of size $n\approx 256$, and considered OT solvers that return couplings that are either sharp (using e.g. the Hungarian algorithm) or blurred (using e.g. entropic regularization, a.k.a. Sinkhorn). We follow in the footsteps of these works by exploring the benefits of increasing $n$ by three to four orders of magnitude, and look more carefully on the effect of the entropic regularization $\varepsilon$ used in the Sinkhorn algorithm. Our analysis is facilitated by new scale invariant quantities to report the sharpness of a coupling, while our sharded computations across multiple GPU or GPU nodes allow scaling up $n$. We show that in both synthetic and image generation tasks, flow models greatly benefit when fitted with large Sinkhorn couplings, with a low entropic regularization $\varepsilon$.
Multivariate Conformal Prediction using Optimal Transport
Feb 05, 2025



Conformal prediction (CP) quantifies the uncertainty of machine learning models by constructing sets of plausible outputs. These sets are constructed by leveraging a so-called conformity score, a quantity computed using the input point of interest, a prediction model, and past observations. CP sets are then obtained by evaluating the conformity score of all possible outputs, and selecting them according to the rank of their scores. Due to this ranking step, most CP approaches rely on a score functions that are univariate. The challenge in extending these scores to multivariate spaces lies in the fact that no canonical order for vectors exists. To address this, we leverage a natural extension of multivariate score ranking based on optimal transport (OT). Our method, OTCP, offers a principled framework for constructing conformal prediction sets in multidimensional settings, preserving distribution-free coverage guarantees with finite data samples. We demonstrate tangible gains in a benchmark dataset of multivariate regression problems and address computational \& statistical trade-offs that arise when estimating conformity scores through OT maps.
Multimodal Autoregressive Pre-training of Large Vision Encoders
Nov 21, 2024



We introduce a novel method for pre-training of large-scale vision encoders. Building on recent advancements in autoregressive pre-training of vision models, we extend this framework to a multimodal setting, i.e., images and text. In this paper, we present AIMV2, a family of generalist vision encoders characterized by a straightforward pre-training process, scalability, and remarkable performance across a range of downstream tasks. This is achieved by pairing the vision encoder with a multimodal decoder that autoregressively generates raw image patches and text tokens. Our encoders excel not only in multimodal evaluations but also in vision benchmarks such as localization, grounding, and classification. Notably, our AIMV2-3B encoder achieves 89.5% accuracy on ImageNet-1k with a frozen trunk. Furthermore, AIMV2 consistently outperforms state-of-the-art contrastive models (e.g., CLIP, SigLIP) in multimodal image understanding across diverse settings.
Controlling Language and Diffusion Models by Transporting Activations
Oct 30, 2024



The increasing capabilities of large generative models and their ever more widespread deployment have raised concerns about their reliability, safety, and potential misuse. To address these issues, recent works have proposed to control model generation by steering model activations in order to effectively induce or prevent the emergence of concepts or behaviors in the generated output. In this paper we introduce Activation Transport (AcT), a general framework to steer activations guided by optimal transport theory that generalizes many previous activation-steering works. AcT is modality-agnostic and provides fine-grained control over the model behavior with negligible computational overhead, while minimally impacting model abilities. We experimentally show the effectiveness and versatility of our approach by addressing key challenges in large language models (LLMs) and text-to-image diffusion models (T2Is). For LLMs, we show that AcT can effectively mitigate toxicity, induce arbitrary concepts, and increase their truthfulness. In T2Is, we show how AcT enables fine-grained style control and concept negation.
Simple ReFlow: Improved Techniques for Fast Flow Models
Oct 10, 2024



Diffusion and flow-matching models achieve remarkable generative performance but at the cost of many sampling steps, this slows inference and limits applicability to time-critical tasks. The ReFlow procedure can accelerate sampling by straightening generation trajectories. However, ReFlow is an iterative procedure, typically requiring training on simulated data, and results in reduced sample quality. To mitigate sample deterioration, we examine the design space of ReFlow and highlight potential pitfalls in prior heuristic practices. We then propose seven improvements for training dynamics, learning and inference, which are verified with thorough ablation studies on CIFAR10 $32 \times 32$, AFHQv2 $64 \times 64$, and FFHQ $64 \times 64$. Combining all our techniques, we achieve state-of-the-art FID scores (without / with guidance, resp.) for fast generation via neural ODEs: $2.23$ / $1.98$ on CIFAR10, $2.30$ / $1.91$ on AFHQv2, $2.84$ / $2.67$ on FFHQ, and $3.49$ / $1.74$ on ImageNet-64, all with merely $9$ neural function evaluations.
Progressive Entropic Optimal Transport Solvers
Jun 07, 2024Optimal transport (OT) has profoundly impacted machine learning by providing theoretical and computational tools to realign datasets. In this context, given two large point clouds of sizes $n$ and $m$ in $\mathbb{R}^d$, entropic OT (EOT) solvers have emerged as the most reliable tool to either solve the Kantorovich problem and output a $n\times m$ coupling matrix, or to solve the Monge problem and learn a vector-valued push-forward map. While the robustness of EOT couplings/maps makes them a go-to choice in practical applications, EOT solvers remain difficult to tune because of a small but influential set of hyperparameters, notably the omnipresent entropic regularization strength $\varepsilon$. Setting $\varepsilon$ can be difficult, as it simultaneously impacts various performance metrics, such as compute speed, statistical performance, generalization, and bias. In this work, we propose a new class of EOT solvers (ProgOT), that can estimate both plans and transport maps. We take advantage of several opportunities to optimize the computation of EOT solutions by dividing mass displacement using a time discretization, borrowing inspiration from dynamic OT formulations, and conquering each of these steps using EOT with properly scheduled parameters. We provide experimental evidence demonstrating that ProgOT is a faster and more robust alternative to standard solvers when computing couplings at large scales, even outperforming neural network-based approaches. We also prove statistical consistency of our approach for estimating optimal transport maps.
Contrasting Multiple Representations with the Multi-Marginal Matching Gap
May 29, 2024



Learning meaningful representations of complex objects that can be seen through multiple ($k\geq 3$) views or modalities is a core task in machine learning. Existing methods use losses originally intended for paired views, and extend them to $k$ views, either by instantiating $\tfrac12k(k-1)$ loss-pairs, or by using reduced embeddings, following a \textit{one vs. average-of-rest} strategy. We propose the multi-marginal matching gap (M3G), a loss that borrows tools from multi-marginal optimal transport (MM-OT) theory to simultaneously incorporate all $k$ views. Given a batch of $n$ points, each seen as a $k$-tuple of views subsequently transformed into $k$ embeddings, our loss contrasts the cost of matching these $n$ ground-truth $k$-tuples with the MM-OT polymatching cost, which seeks $n$ optimally arranged $k$-tuples chosen within these $n\times k$ vectors. While the exponential complexity $O(n^k$) of the MM-OT problem may seem daunting, we show in experiments that a suitable generalization of the Sinkhorn algorithm for that problem can scale to, e.g., $k=3\sim 6$ views using mini-batches of size $64~\sim128$. Our experiments demonstrate improved performance over multiview extensions of pairwise losses, for both self-supervised and multimodal tasks.