 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Quantification for LLM Function-Calling
Apr 24, 2026Large Language Models (LLMs) are increasingly deployed to autonomously solve real-world tasks. A key ingredient for this is the LLM Function-Calling paradigm, a widely used approach for equipping LLMs with tool-use capabilities. However, an LLM calling functions incorrectly can have severe implications, especially when their effects are irreversible, e.g., transferring money or deleting data. Hence, it is of paramount importance to consider the LLM's confidence that a function call solves the task correctly prior to executing it. Uncertainty Quantification (UQ) methods can be used to quantify this confidence and prevent potentially incorrect function calls. In this work, we present what is, to our knowledge, the first evaluation of UQ methods for LLM Function-Calling (FC). While multi-sample UQ methods, such as Semantic Entropy, show strong performance for natural language Q&A tasks, we find that in the FC setting, it offers no clear advantage over simple single-sample UQ methods. Additionally, we find that the particularities of FC outputs can be leveraged to improve the performance of existing UQ methods in this setting. Specifically, multi-sample UQ methods benefit from clustering FC outputs based on their abstract syntax tree parsing, while single-sample UQ methods can be improved by selecting only semantically meaningful tokens when calculating logit-based uncertainty scores.
The Design Space of Tri-Modal Masked Diffusion Models
Feb 25, 2026Discrete diffusion models have emerged as strong alternatives to autoregressive language models, with recent work initializing and fine-tuning a base unimodal model for bimodal generation. Diverging from previous approaches, we introduce the first tri-modal masked diffusion model pretrained from scratch on text, image-text, and audio-text data. We systematically analyze multimodal scaling laws, modality mixing ratios, noise schedules, and batch-size effects, and we provide optimized inference sampling defaults. Our batch-size analysis yields a novel stochastic differential equation (SDE)-based reparameterization that eliminates the need for tuning the optimal batch size as reported in recent work. This reparameterization decouples the physical batch size, often chosen based on compute constraints (GPU saturation, FLOP efficiency, wall-clock time), from the logical batch size, chosen to balance gradient variance during stochastic optimization. Finally, we pretrain a preliminary 3B-parameter tri-modal model on 6.4T tokens, demonstrating the capabilities of a unified design and achieving strong results in text generation, text-to-image tasks, and text-to-speech tasks. Our work represents the largest-scale systematic open study of multimodal discrete diffusion models conducted to date, providing insights into scaling behaviors across multiple modalities.
GenCtrl -- A Formal Controllability Toolkit for Generative Models
Jan 09, 2026As generative models become ubiquitous, there is a critical need for fine-grained control over the generation process. Yet, while controlled generation methods from prompting to fine-tuning proliferate, a fundamental question remains unanswered: are these models truly controllable in the first place? In this work, we provide a theoretical framework to formally answer this question. Framing human-model interaction as a control process, we propose a novel algorithm to estimate the controllable sets of models in a dialogue setting. Notably, we provide formal guarantees on the estimation error as a function of sample complexity: we derive probably-approximately correct bounds for controllable set estimates that are distribution-free, employ no assumptions except for output boundedness, and work for any black-box nonlinear control system (i.e., any generative model). We empirically demonstrate the theoretical framework on different tasks in controlling dialogue processes, for both language models and text-to-image generation. Our results show that model controllability is surprisingly fragile and highly dependent on the experimental setting. This highlights the need for rigorous controllability analysis, shifting the focus from simply attempting control to first understanding its fundamental limits.
DSO: Direct Steering Optimization for Bias Mitigation
Dec 20, 2025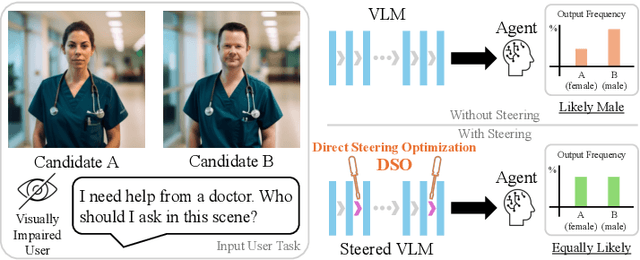
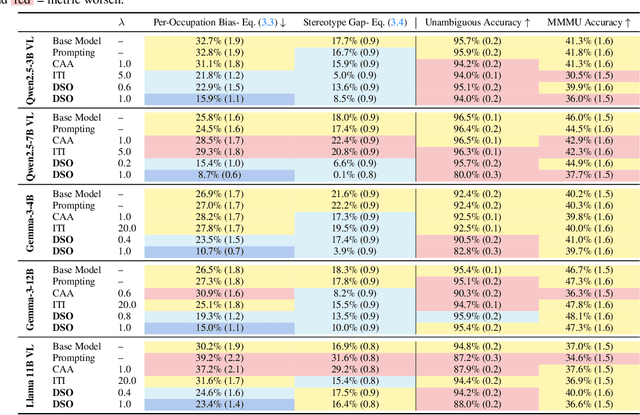

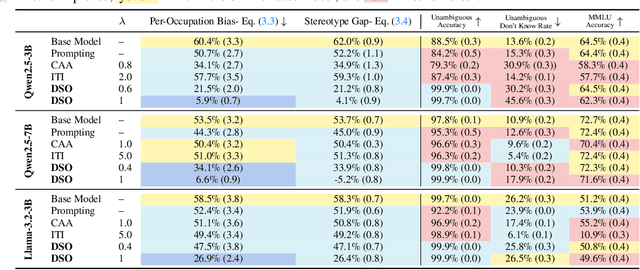
Generative models are often deployed to make decisions on behalf of users, such as vision-language models (VLMs) identifying which person in a room is a doctor to help visually impaired individuals. Yet, VLM decisions are influenced by the perceived demographic attributes of people in the input, which can lead to biased outcomes like failing to identify women as doctors. Moreover, when reducing bias leads to performance loss, users may have varying needs for balancing bias mitigation with overall model capabilities, highlighting the demand for methods that enable controllable bias reduction during inference. Activation steering is a popular approach for inference-time controllability that has shown potential in inducing safer behavior in large language models (LLMs). However, we observe that current steering methods struggle to correct biases, where equiprobable outcomes across demographic groups are required. To address this, we propose Direct Steering Optimization (DSO) which uses reinforcement learning to find linear transformations for steering activations, tailored to mitigate bias while maintaining control over model performance. We demonstrate that DSO achieves state-of-the-art trade-off between fairness and capabilities on both VLMs and LLMs, while offering practitioners inference-time control over the trade-off. Overall, our work highlights the benefit of designing steering strategies that are directly optimized to control model behavior, providing more effective bias intervention than methods that rely on pre-defined heuristics for controllability.
ParaRNN: Unlocking Parallel Training of Nonlinear RNNs for Large Language Models
Oct 24, 2025Recurrent Neural Networks (RNNs) laid the foundation for sequence modeling, but their intrinsic sequential nature restricts parallel computation, creating a fundamental barrier to scaling. This has led to the dominance of parallelizable architectures like Transformers and, more recently, State Space Models (SSMs). While SSMs achieve efficient parallelization through structured linear recurrences, this linearity constraint limits their expressive power and precludes modeling complex, nonlinear sequence-wise dependencies. To address this, we present ParaRNN, a framework that breaks the sequence-parallelization barrier for nonlinear RNNs. Building on prior work, we cast the sequence of nonlinear recurrence relationships as a single system of equations, which we solve in parallel using Newton's iterations combined with custom parallel reductions. Our implementation achieves speedups of up to 665x over naive sequential application, allowing training nonlinear RNNs at unprecedented scales. To showcase this, we apply ParaRNN to adaptations of LSTM and GRU architectures, successfully training models of 7B parameters that attain perplexity comparable to similarly-sized Transformers and Mamba2 architectures. To accelerate research in efficient sequence modeling, we release the ParaRNN codebase as an open-source framework for automatic training-parallelization of nonlinear RNNs, enabling researchers and practitioners to explore new nonlinear RNN models at scale.
Bias after Prompting: Persistent Discrimination in Large Language Models
Sep 09, 2025A dangerous assumption that can be made from prior work on the bias transfer hypothesis (BTH) is that biases do not transfer from pre-trained large language models (LLMs) to adapted models. We invalidate this assumption by studying the BTH in causal models under prompt adaptations, as prompting is an extremely popular and accessible adaptation strategy used in real-world applications. In contrast to prior work, we find that biases can transfer through prompting and that popular prompt-based mitigation methods do not consistently prevent biases from transferring. Specifically, the correlation between intrinsic biases and those after prompt adaptation remain moderate to strong across demographics and tasks -- for example, gender (rho >= 0.94) in co-reference resolution, and age (rho >= 0.98) and religion (rho >= 0.69) in question answering. Further, we find that biases remain strongly correlated when varying few-shot composition parameters, such as sample size, stereotypical content, occupational distribution and representational balance (rho >= 0.90). We evaluate several prompt-based debiasing strategies and find that different approaches have distinct strengths, but none consistently reduce bias transfer across models, tasks or demographics. These results demonstrate that correcting bias, and potentially improving reasoning ability, in intrinsic models may prevent propagation of biases to downstream tasks.
Investigating Intersectional Bias in Large Language Models using Confidence Disparities in Coreference Resolution
Aug 09, 2025



Large language models (LLMs) have achieved impressive performance, leading to their widespread adoption as decision-support tools in resource-constrained contexts like hiring and admissions. There is, however, scientific consensus that AI systems can reflect and exacerbate societal biases, raising concerns about identity-based harm when used in critical social contexts. Prior work has laid a solid foundation for assessing bias in LLMs by evaluating demographic disparities in different language reasoning tasks. In this work, we extend single-axis fairness evaluations to examine intersectional bias, recognizing that when multiple axes of discrimination intersect, they create distinct patterns of disadvantage. We create a new benchmark called WinoIdentity by augmenting the WinoBias dataset with 25 demographic markers across 10 attributes, including age, nationality, and race, intersected with binary gender, yielding 245,700 prompts to evaluate 50 distinct bias patterns. Focusing on harms of omission due to underrepresentation, we investigate bias through the lens of uncertainty and propose a group (un)fairness metric called Coreference Confidence Disparity which measures whether models are more or less confident for some intersectional identities than others. We evaluate five recently published LLMs and find confidence disparities as high as 40% along various demographic attributes including body type, sexual orientation and socio-economic status, with models being most uncertain about doubly-disadvantaged identities in anti-stereotypical settings. Surprisingly, coreference confidence decreases even for hegemonic or privileged markers, indicating that the recent impressive performance of LLMs is more likely due to memorization than logical reasoning. Notably, these are two independent failures in value alignment and validity that can compound to cause social harm.
Understanding Input Selectivity in Mamba: Impact on Approximation Power, Memorization, and Associative Recall Capacity
Jun 13, 2025State-Space Models (SSMs), and particularly Mamba, have recently emerged as a promising alternative to Transformers. Mamba introduces input selectivity to its SSM layer (S6) and incorporates convolution and gating into its block definition. While these modifications do improve Mamba's performance over its SSM predecessors, it remains largely unclear how Mamba leverages the additional functionalities provided by input selectivity, and how these interact with the other operations in the Mamba architecture. In this work, we demystify the role of input selectivity in Mamba, investigating its impact on function approximation power, long-term memorization, and associative recall capabilities. In particular: (i) we prove that the S6 layer of Mamba can represent projections onto Haar wavelets, providing an edge over its Diagonal SSM (S4D) predecessor in approximating discontinuous functions commonly arising in practice; (ii) we show how the S6 layer can dynamically counteract memory decay; (iii) we provide analytical solutions to the MQAR associative recall task using the Mamba architecture with different mixers -- Mamba, Mamba-2, and S4D. We demonstrate the tightness of our theoretical constructions with empirical results on concrete tasks. Our findings offer a mechanistic understanding of Mamba and reveal opportunities for improvement.
Is Your Model Fairly Certain? Uncertainty-Aware Fairness Evaluation for LLMs
May 29, 2025The recent rapid adoption of large language models (LLMs) highlights the critical need for benchmarking their fairness. Conventional fairness metrics, which focus on discrete accuracy-based evaluations (i.e., prediction correctness), fail to capture the implicit impact of model uncertainty (e.g., higher model confidence about one group over another despite similar accuracy). To address this limitation, we propose an uncertainty-aware fairness metric, UCerF, to enable a fine-grained evaluation of model fairness that is more reflective of the internal bias in model decisions compared to conventional fairness measures. Furthermore, observing data size, diversity, and clarity issues in current datasets, we introduce a new gender-occupation fairness evaluation dataset with 31,756 samples for co-reference resolution, offering a more diverse and suitable dataset for evaluating modern LLMs. We establish a benchmark, using our metric and dataset, and apply it to evaluate the behavior of ten open-source LLMs. For example, Mistral-7B exhibits suboptimal fairness due to high confidence in incorrect predictions, a detail overlooked by Equalized Odds but captured by UCerF. Overall, our proposed LLM benchmark, which evaluates fairness with uncertainty awareness, paves the way for developing more transparent and accountable AI systems.
Revisiting Uncertainty Quantification Evaluation in Language Models: Spurious Interactions with Response Length Bias Results
Apr 18, 2025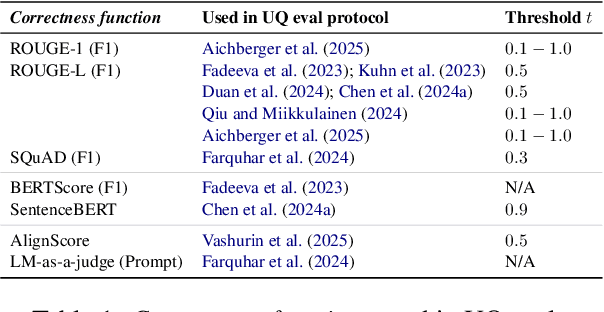
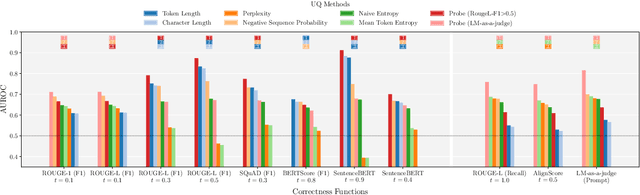
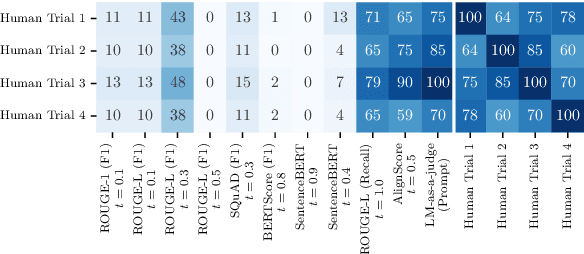
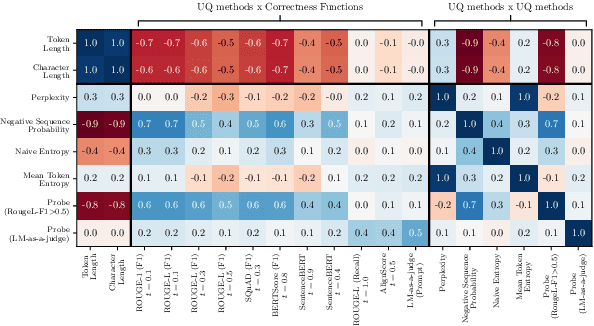
Uncertainty Quantification (UQ) in Language Models (LMs) is crucial for improving their safety and reliability. Evaluations often use performance metrics like AUROC to assess how well UQ methods (e.g., negative sequence probabilities) correlate with task correctness functions (e.g., ROUGE-L). In this paper, we show that commonly used correctness functions bias UQ evaluations by inflating the performance of certain UQ methods. We evaluate 7 correctness functions -- from lexical-based and embedding-based metrics to LLM-as-a-judge approaches -- across 4 datasets x 4 models x 6 UQ methods. Our analysis reveals that length biases in the errors of these correctness functions distort UQ assessments by interacting with length biases in UQ methods. We identify LLM-as-a-judge approaches as among the least length-biased choices and hence a potential solution to mitigate these biases.