 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNDAI Agreements
Feb 11, 2025We study a fundamental challenge in the economics of innovation: an inventor must reveal details of a new idea to secure compensation or funding, yet such disclosure risks expropriation. We present a model in which a seller (inventor) and buyer (investor) bargain over an information good under the threat of hold-up. In the classical setting, the seller withholds disclosure to avoid misappropriation, leading to inefficiency. We show that trusted execution environments (TEEs) combined with AI agents can mitigate and even fully eliminate this hold-up problem. By delegating the disclosure and payment decisions to tamper-proof programs, the seller can safely reveal the invention without risking expropriation, achieving full disclosure and an efficient ex post transfer. Moreover, even if the invention's value exceeds a threshold that TEEs can fully secure, partial disclosure still improves outcomes compared to no disclosure. Recognizing that real AI agents are imperfect, we model "agent errors" in payments or disclosures and demonstrate that budget caps and acceptance thresholds suffice to preserve most of the efficiency gains. Our results imply that cryptographic or hardware-based solutions can function as an "ironclad NDA," substantially mitigating the fundamental disclosure-appropriation paradox first identified by Arrow (1962) and Nelson (1959). This has far-reaching policy implications for fostering R&D, technology transfer, and collaboration.
OML: Open, Monetizable, and Loyal AI
Nov 01, 2024



Artificial Intelligence (AI) has steadily improved across a wide range of tasks. However, the development and deployment of AI are almost entirely controlled by a few powerful organizations that are racing to create Artificial General Intelligence (AGI). The centralized entities make decisions with little public oversight, shaping the future of humanity, often with unforeseen consequences. In this paper, we propose OML, which stands for Open, Monetizable, and Loyal AI, an approach designed to democratize AI development. OML is realized through an interdisciplinary framework spanning AI, blockchain, and cryptography. We present several ideas for constructing OML using technologies such as Trusted Execution Environments (TEE), traditional cryptographic primitives like fully homomorphic encryption and functional encryption, obfuscation, and AI-native solutions rooted in the sample complexity and intrinsic hardness of AI tasks. A key innovation of our work is introducing a new scientific field: AI-native cryptography. Unlike conventional cryptography, which focuses on discrete data and binary security guarantees, AI-native cryptography exploits the continuous nature of AI data representations and their low-dimensional manifolds, focusing on improving approximate performance. One core idea is to transform AI attack methods, such as data poisoning, into security tools. This novel approach serves as a foundation for OML 1.0 which uses model fingerprinting to protect the integrity and ownership of AI models. The spirit of OML is to establish a decentralized, open, and transparent platform for AI development, enabling the community to contribute, monetize, and take ownership of AI models. By decentralizing control and ensuring transparency through blockchain technology, OML prevents the concentration of power and provides accountability in AI development that has not been possible before.
Considerations for Distribution Shift Robustness of Diagnostic Models in Healthcare
Oct 25, 2024
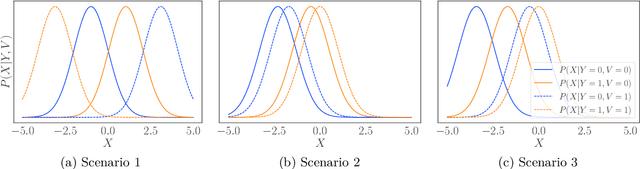
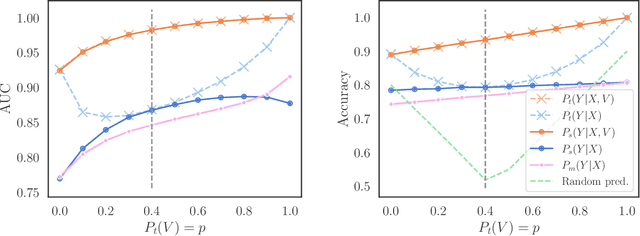
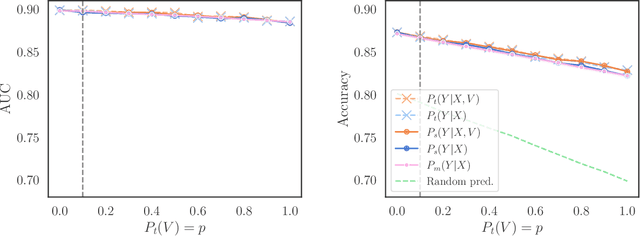
We consider robustness to distribution shifts in the context of diagnostic models in healthcare, where the prediction target $Y$, e.g., the presence of a disease, is causally upstream of the observations $X$, e.g., a biomarker. Distribution shifts may occur, for instance, when the training data is collected in a domain with patients having particular demographic characteristics while the model is deployed on patients from a different demographic group. In the domain of applied ML for health, it is common to predict $Y$ from $X$ without considering further information about the patient. However, beyond the direct influence of the disease $Y$ on biomarker $X$, a predictive model may learn to exploit confounding dependencies (or shortcuts) between $X$ and $Y$ that are unstable under certain distribution shifts. In this work, we highlight a data generating mechanism common to healthcare settings and discuss how recent theoretical results from the causality literature can be applied to build robust predictive models. We theoretically show why ignoring covariates as well as common invariant learning approaches will in general not yield robust predictors in the studied setting, while including certain covariates into the prediction model will. In an extensive simulation study, we showcase the robustness (or lack thereof) of different predictors under various data generating processes. Lastly, we analyze the performance of the different approaches using the PTB-XL dataset, a public dataset of annotated ECG recordings.
A Causal Framework to Evaluate Racial Bias in Law Enforcement Systems
Feb 22, 2024We are interested in developing a data-driven method to evaluate race-induced biases in law enforcement systems. While the recent works have addressed this question in the context of police-civilian interactions using police stop data, they have two key limitations. First, bias can only be properly quantified if true criminality is accounted for in addition to race, but it is absent in prior works. Second, law enforcement systems are multi-stage and hence it is important to isolate the true source of bias within the "causal chain of interactions" rather than simply focusing on the end outcome; this can help guide reforms. In this work, we address these challenges by presenting a multi-stage causal framework incorporating criminality. We provide a theoretical characterization and an associated data-driven method to evaluate (a) the presence of any form of racial bias, and (b) if so, the primary source of such a bias in terms of race and criminality. Our framework identifies three canonical scenarios with distinct characteristics: in settings like (1) airport security, the primary source of observed bias against a race is likely to be bias in law enforcement against innocents of that race; (2) AI-empowered policing, the primary source of observed bias against a race is likely to be bias in law enforcement against criminals of that race; and (3) police-civilian interaction, the primary source of observed bias against a race could be bias in law enforcement against that race or bias from the general public in reporting against the other race. Through an extensive empirical study using police-civilian interaction data and 911 call data, we find an instance of such a counter-intuitive phenomenon: in New Orleans, the observed bias is against the majority race and the likely reason for it is the over-reporting (via 911 calls) of incidents involving the minority race by the general public.
Hidden Markov Models with Momentum
Jun 08, 2022
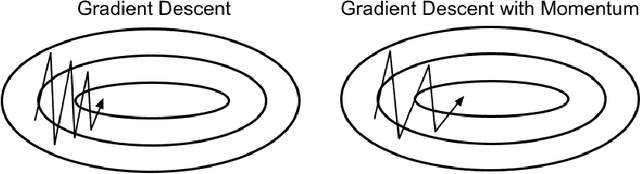
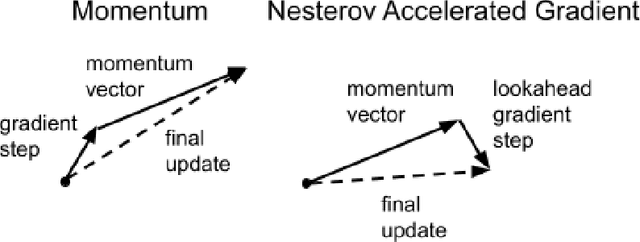
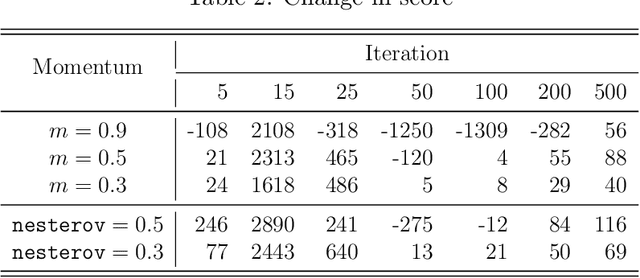
Momentum is a popular technique for improving convergence rates during gradient descent. In this research, we experiment with adding momentum to the Baum-Welch expectation-maximization algorithm for training Hidden Markov Models. We compare discrete Hidden Markov Models trained with and without momentum on English text and malware opcode data. The effectiveness of momentum is determined by measuring the changes in model score and classification accuracy due to momentum. Our extensive experiments indicate that adding momentum to Baum-Welch can reduce the number of iterations required for initial convergence during HMM training, particularly in cases where the model is slow to converge. However, momentum does not seem to improve the final model performance at a high number of iterations.
Mechanics-based Analysis on Flagellated Robots
Dec 27, 2021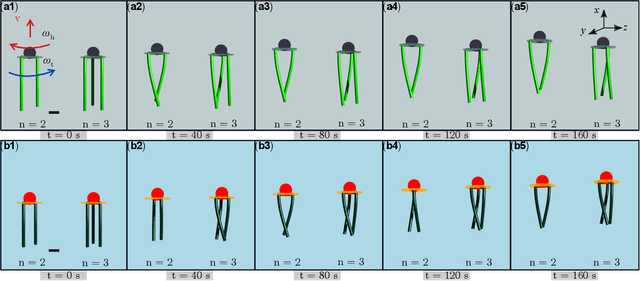
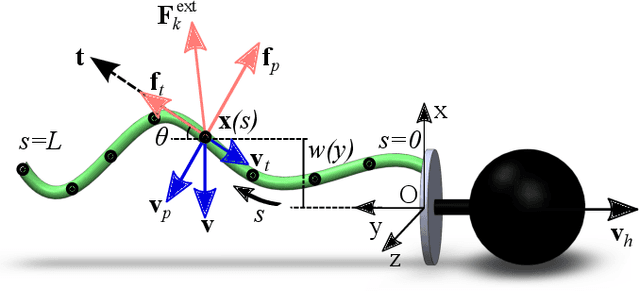

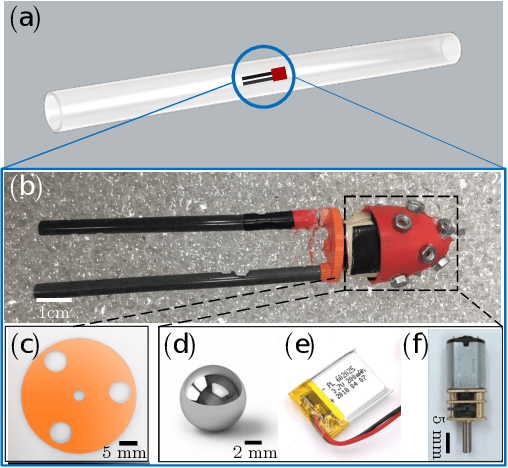
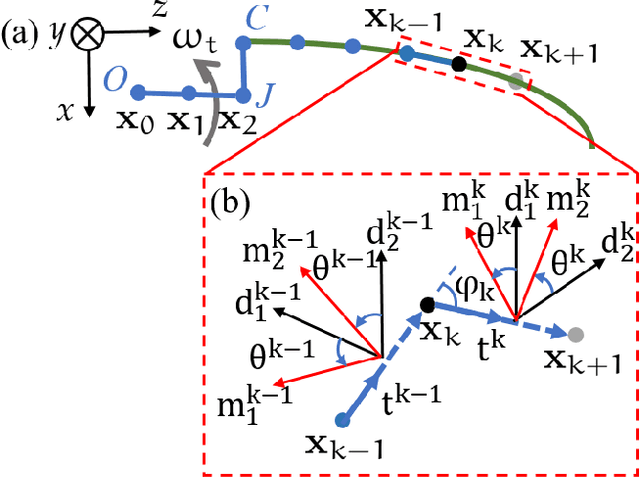
We explore the locomotion of soft robots in granular medium (GM) resulting from the elastic deformation of slender rods. A low-cost, rapidly fabricable robot inspired by the physiological structure of bacteria is presented. It consists of a rigid head, with a motor and batteries embedded, and multiple elastic rods (our model for flagella) to investigate locomotion in GM. The elastic flagella are rotated at one end by the motor, and they deform due to the drag from GM, propelling the robot. The external drag is determined by the flagellar shape, while the latter changes due to the competition between external loading and elastic forces. In this coupled fluid-structure interaction problem, we observe that increasing the number of flagella can decrease or increase the propulsive speed of the robot, depending on the physical parameters of the system. This nonlinearity in the functional relation between propulsion and the parameters of this simple robot motivates us to fundamentally analyze its mechanics using theory, numerical simulation, and experiments. We present a simple Euler-Bernoulli beam theory-based analytical framework that is capable of qualitatively capturing both cases. Theoretical prediction quantitatively matches experiments when the flagellar deformation is small. To account for the geometrically nonlinear deformation often encountered in soft robots and microbes, we implement a simulation framework that incorporates discrete differential geometry-based simulations of elastic rods, a resistive force theory-based model for drag, and a modified Stokes law for the hydrodynamics of the robot head. Comparison with experimental data indicates that the simulations can quantitatively predict robotic motion. Overall, the theoretical and numerical tools presented in this paper can shed light on the design and control of this class of articulated robots in granular or fluid media.
Simple Flagellated Soft Robot for Locomotion near Air-Fluid Interface
Mar 09, 2021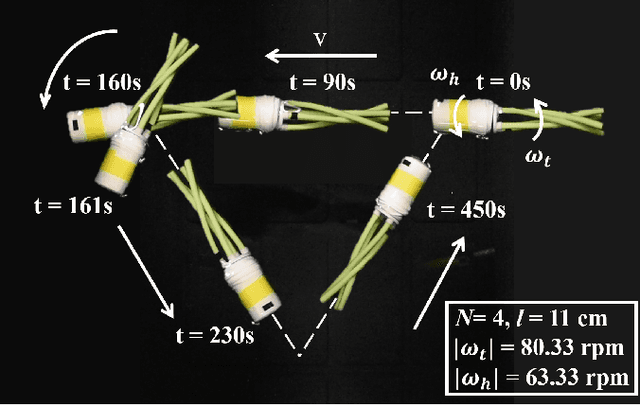


A wide range of microorganisms, e.g. bacteria, propel themselves by rotation of soft helical tails, also known as flagella. Due to the small size of these organisms, viscous forces overwhelm inertial effects and the flow is at low Reynolds number. In this fluid-structure problem, a competition between elastic forces and hydrodynamic (viscous) forces leads to a net propulsive force forward. A thorough understanding of this highly coupled fluid-structure interaction problem can not only help us better understand biological propulsion but also help us design bio-inspired functional robots with applications in oil spill cleanup, water quality monitoring, and infrastructure inspection. Here, we introduce arguably the simplest soft robot with a single binary control signal, which is capable of moving along an arbitrary 2D trajectory near air-fluid interface and at the interface between two fluids. The robot exploits the variation in viscosity to move along the prescribed trajectory. Our analysis of this newly introduced soft robot consists of three main components. First, we fabricate this simple robot and use it as an experimental testbed. Second, a discrete differential geometry-based modeling framework is used for simulation of the robot. Upon validation of the simulation tool, the third part of this study employs the simulations to develop a control scheme with a single binary input to make the robot follow any prescribed path.
Hierarchical Inducing Point Gaussian Process for Inter-domain Observations
Feb 28, 2021
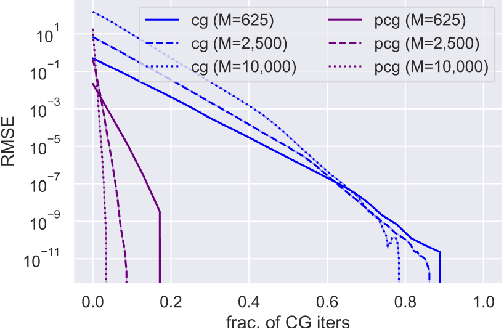
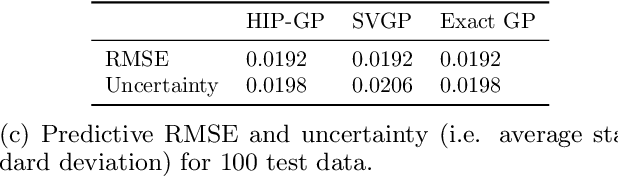
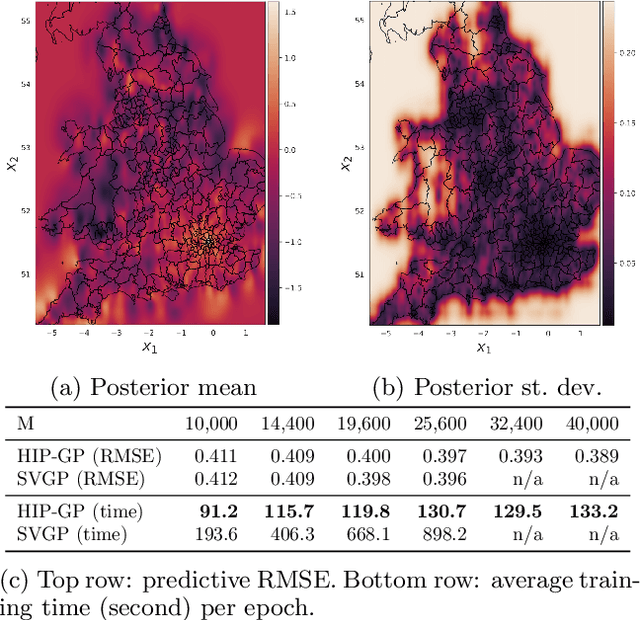
We examine the general problem of inter-domain Gaussian Processes (GPs): problems where the GP realization and the noisy observations of that realization lie on different domains. When the mapping between those domains is linear, such as integration or differentiation, inference is still closed form. However, many of the scaling and approximation techniques that our community has developed do not apply to this setting. In this work, we introduce the hierarchical inducing point GP (HIP-GP), a scalable inter-domain GP inference method that enables us to improve the approximation accuracy by increasing the number of inducing points to the millions. HIP-GP, which relies on inducing points with grid structure and a stationary kernel assumption, is suitable for low-dimensional problems. In developing HIP-GP, we introduce (1) a fast whitening strategy, and (2) a novel preconditioner for conjugate gradients which can be helpful in general GP settings.
Adaptive Synthetic Characters for Military Training
Jan 06, 2021
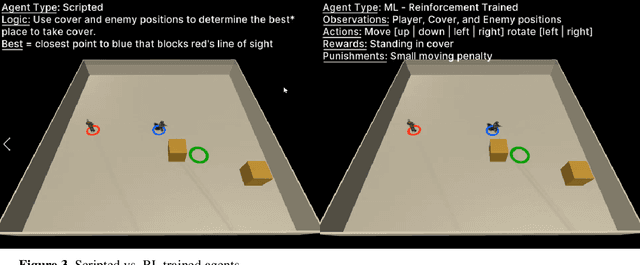
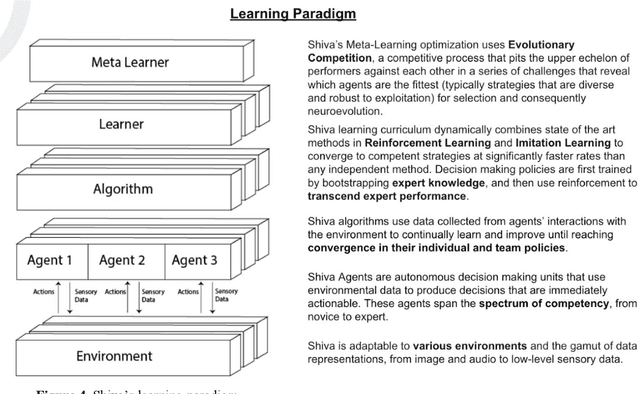
Behaviors of the synthetic characters in current military simulations are limited since they are generally generated by rule-based and reactive computational models with minimal intelligence. Such computational models cannot adapt to reflect the experience of the characters, resulting in brittle intelligence for even the most effective behavior models devised via costly and labor-intensive processes. Observation-based behavior model adaptation that leverages machine learning and the experience of synthetic entities in combination with appropriate prior knowledge can address the issues in the existing computational behavior models to create a better training experience in military training simulations. In this paper, we introduce a framework that aims to create autonomous synthetic characters that can perform coherent sequences of believable behavior while being aware of human trainees and their needs within a training simulation. This framework brings together three mutually complementary components. The first component is a Unity-based simulation environment - Rapid Integration and Development Environment (RIDE) - supporting One World Terrain (OWT) models and capable of running and supporting machine learning experiments. The second is Shiva, a novel multi-agent reinforcement and imitation learning framework that can interface with a variety of simulation environments, and that can additionally utilize a variety of learning algorithms. The final component is the Sigma Cognitive Architecture that will augment the behavior models with symbolic and probabilistic reasoning capabilities. We have successfully created proof-of-concept behavior models leveraging this framework on realistic terrain as an essential step towards bringing machine learning into military simulations.
Celeste: Variational inference for a generative model of astronomical images
Jun 03, 2015
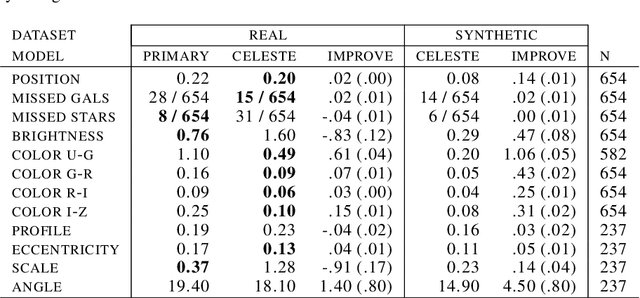
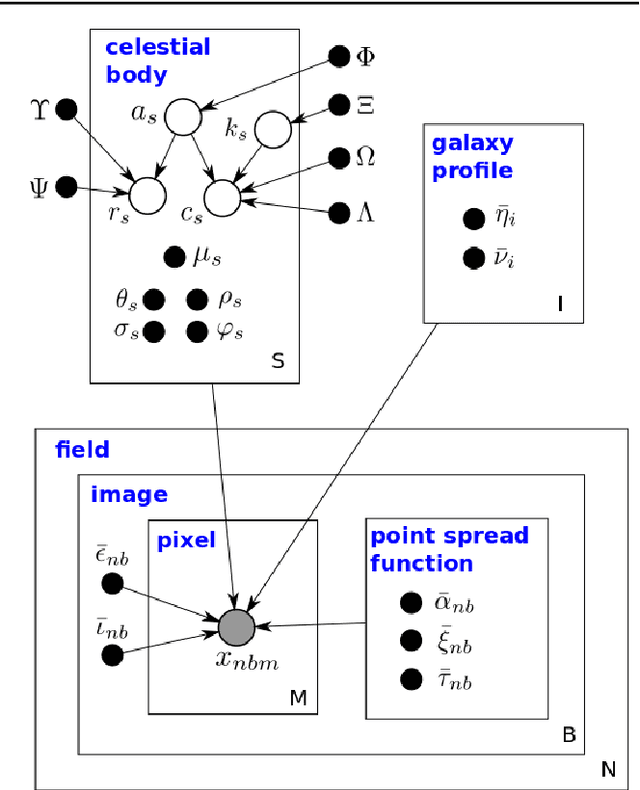
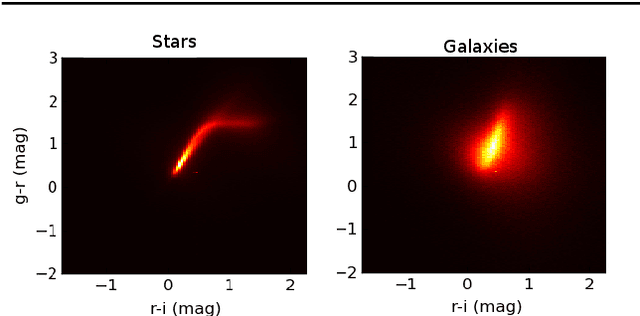
We present a new, fully generative model of optical telescope image sets, along with a variational procedure for inference. Each pixel intensity is treated as a Poisson random variable, with a rate parameter dependent on latent properties of stars and galaxies. Key latent properties are themselves random, with scientific prior distributions constructed from large ancillary data sets. We check our approach on synthetic images. We also run it on images from a major sky survey, where it exceeds the performance of the current state-of-the-art method for locating celestial bodies and measuring their colors.