 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden Markov Models with Momentum
Paper and Code
Jun 08, 2022
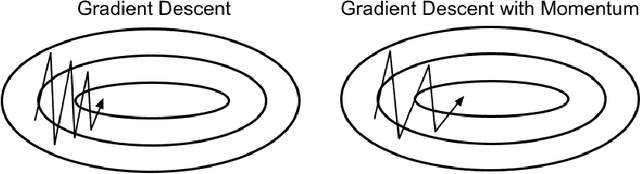
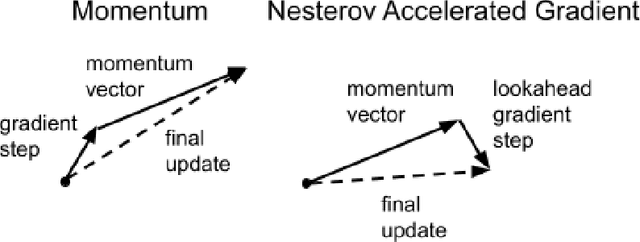
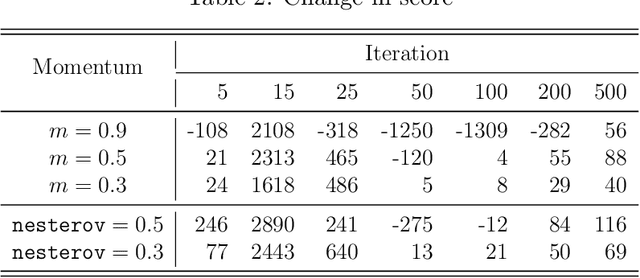
Momentum is a popular technique for improving convergence rates during gradient descent. In this research, we experiment with adding momentum to the Baum-Welch expectation-maximization algorithm for training Hidden Markov Models. We compare discrete Hidden Markov Models trained with and without momentum on English text and malware opcode data. The effectiveness of momentum is determined by measuring the changes in model score and classification accuracy due to momentum. Our extensive experiments indicate that adding momentum to Baum-Welch can reduce the number of iterations required for initial convergence during HMM training, particularly in cases where the model is slow to converge. However, momentum does not seem to improve the final model performance at a high number of iterations.