 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNDAI Agreements
Feb 11, 2025We study a fundamental challenge in the economics of innovation: an inventor must reveal details of a new idea to secure compensation or funding, yet such disclosure risks expropriation. We present a model in which a seller (inventor) and buyer (investor) bargain over an information good under the threat of hold-up. In the classical setting, the seller withholds disclosure to avoid misappropriation, leading to inefficiency. We show that trusted execution environments (TEEs) combined with AI agents can mitigate and even fully eliminate this hold-up problem. By delegating the disclosure and payment decisions to tamper-proof programs, the seller can safely reveal the invention without risking expropriation, achieving full disclosure and an efficient ex post transfer. Moreover, even if the invention's value exceeds a threshold that TEEs can fully secure, partial disclosure still improves outcomes compared to no disclosure. Recognizing that real AI agents are imperfect, we model "agent errors" in payments or disclosures and demonstrate that budget caps and acceptance thresholds suffice to preserve most of the efficiency gains. Our results imply that cryptographic or hardware-based solutions can function as an "ironclad NDA," substantially mitigating the fundamental disclosure-appropriation paradox first identified by Arrow (1962) and Nelson (1959). This has far-reaching policy implications for fostering R&D, technology transfer, and collaboration.
Towards Bio-inspired Heuristically Accelerated Reinforcement Learning for Adaptive Underwater Multi-Agents Behaviour
Feb 10, 2025

This paper describes the problem of coordination of an autonomous Multi-Agent System which aims to solve the coverage planning problem in a complex environment. The considered applications are the detection and identification of objects of interest while covering an area. These tasks, which are highly relevant for space applications, are also of interest among various domains including the underwater context, which is the focus of this study. In this context, coverage planning is traditionally modelled as a Markov Decision Process where a coordinated MAS, a swarm of heterogeneous autonomous underwater vehicles, is required to survey an area and search for objects. This MDP is associated with several challenges: environment uncertainties, communication constraints, and an ensemble of hazards, including time-varying and unpredictable changes in the underwater environment. MARL algorithms can solve highly non-linear problems using deep neural networks and display great scalability against an increased number of agents. Nevertheless, most of the current results in the underwater domain are limited to simulation due to the high learning time of MARL algorithms. For this reason, a novel strategy is introduced to accelerate this convergence rate by incorporating biologically inspired heuristics to guide the policy during training. The PSO method, which is inspired by the behaviour of a group of animals, is selected as a heuristic. It allows the policy to explore the highest quality regions of the action and state spaces, from the beginning of the training, optimizing the exploration/exploitation trade-off. The resulting agent requires fewer interactions to reach optimal performance. The method is applied to the MSAC algorithm and evaluated for a 2D covering area mission in a continuous control environment.
Codenames as a Benchmark for Large Language Models
Dec 16, 2024



In this paper, we propose the use of the popular word-based board game Codenames as a suitable benchmark for evaluating the reasoning capabilities of Large Language Models (LLMs). Codenames presents a highly interesting challenge for achieving successful AI performance, requiring both a sophisticated understanding of language, theory of mind, and epistemic reasoning capabilities. Prior attempts to develop agents for Codenames have largely relied on word embedding techniques, which have a limited vocabulary range and perform poorly when paired with differing approaches. LLMs have demonstrated enhanced reasoning and comprehension capabilities for language-based tasks, but can still suffer in lateral thinking challenges. We evaluate the capabilities of several state-of-the-art LLMs, including GPT-4o, Gemini 1.5, Claude 3.5 Sonnet, and Llama 3.1, across a variety of board setups. Our results indicate that while certain LLMs perform better than others overall, different models exhibit varying emergent behaviours during gameplay and excel at specific roles. We also evaluate the performance of different combinations of LLMs when playing cooperatively together, demonstrating that LLM agents are more generalisable to a wider range of teammates than prior techniques.
GAVEL: Generating Games Via Evolution and Language Models
Jul 12, 2024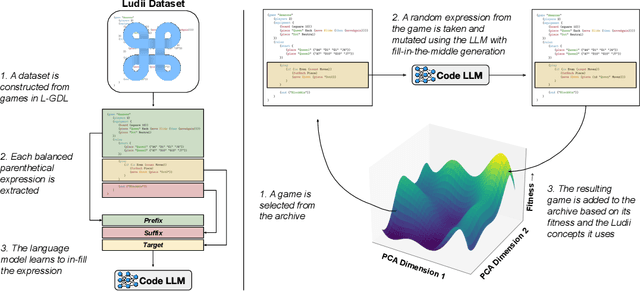

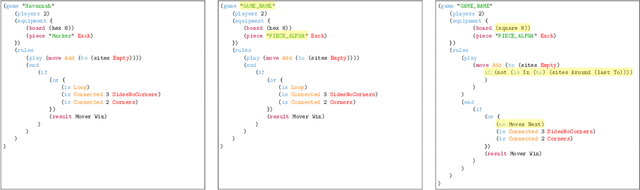

Automatically generating novel and interesting games is a complex task. Challenges include representing game rules in a computationally workable form, searching through the large space of potential games under most such representations, and accurately evaluating the originality and quality of previously unseen games. Prior work in automated game generation has largely focused on relatively restricted rule representations and relied on domain-specific heuristics. In this work, we explore the generation of novel games in the comparatively expansive Ludii game description language, which encodes the rules of over 1000 board games in a variety of styles and modes of play. We draw inspiration from recent advances in large language models and evolutionary computation in order to train a model that intelligently mutates and recombines games and mechanics expressed as code. We demonstrate both quantitatively and qualitatively that our approach is capable of generating new and interesting games, including in regions of the potential rules space not covered by existing games in the Ludii dataset. A sample of the generated games are available to play online through the Ludii portal.
Utilizing Generative Adversarial Networks for Stable Structure Generation in Angry Birds
Sep 05, 2023
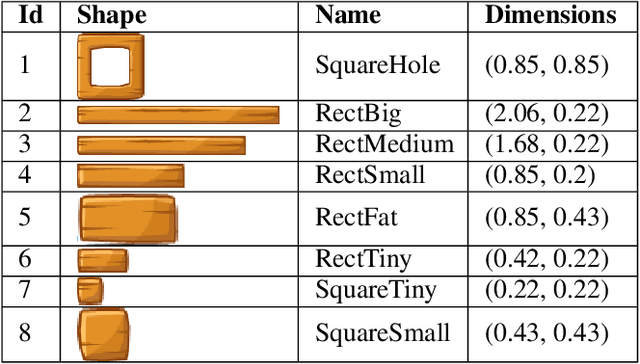
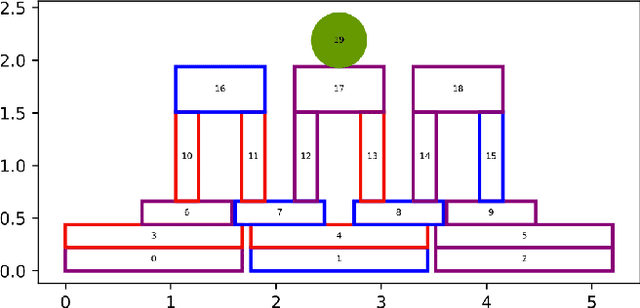

This paper investigates the suitability of using Generative Adversarial Networks (GANs) to generate stable structures for the physics-based puzzle game Angry Birds. While previous applications of GANs for level generation have been mostly limited to tile-based representations, this paper explores their suitability for creating stable structures made from multiple smaller blocks. This includes a detailed encoding/decoding process for converting between Angry Birds level descriptions and a suitable grid-based representation, as well as utilizing state-of-the-art GAN architectures and training methods to produce new structure designs. Our results show that GANs can be successfully applied to generate a varied range of complex and stable Angry Birds structures.
Physics-Based Task Generation through Causal Sequence of Physical Interactions
Aug 16, 2023



Performing tasks in a physical environment is a crucial yet challenging problem for AI systems operating in the real world. Physics simulation-based tasks are often employed to facilitate research that addresses this challenge. In this paper, first, we present a systematic approach for defining a physical scenario using a causal sequence of physical interactions between objects. Then, we propose a methodology for generating tasks in a physics-simulating environment using these defined scenarios as inputs. Our approach enables a better understanding of the granular mechanics required for solving physics-based tasks, thereby facilitating accurate evaluation of AI systems' physical reasoning capabilities. We demonstrate our proposed task generation methodology using the physics-based puzzle game Angry Birds and evaluate the generated tasks using a range of metrics, including physical stability, solvability using intended physical interactions, and accidental solvability using unintended solutions. We believe that the tasks generated using our proposed methodology can facilitate a nuanced evaluation of physical reasoning agents, thus paving the way for the development of agents for more sophisticated real-world applications.
NovPhy: A Testbed for Physical Reasoning in Open-world Environments
Mar 03, 2023



Due to the emergence of AI systems that interact with the physical environment, there is an increased interest in incorporating physical reasoning capabilities into those AI systems. But is it enough to only have physical reasoning capabilities to operate in a real physical environment? In the real world, we constantly face novel situations we have not encountered before. As humans, we are competent at successfully adapting to those situations. Similarly, an agent needs to have the ability to function under the impact of novelties in order to properly operate in an open-world physical environment. To facilitate the development of such AI systems, we propose a new testbed, NovPhy, that requires an agent to reason about physical scenarios in the presence of novelties and take actions accordingly. The testbed consists of tasks that require agents to detect and adapt to novelties in physical scenarios. To create tasks in the testbed, we develop eight novelties representing a diverse novelty space and apply them to five commonly encountered scenarios in a physical environment. According to our testbed design, we evaluate two capabilities of an agent: the performance on a novelty when it is applied to different physical scenarios and the performance on a physical scenario when different novelties are applied to it. We conduct a thorough evaluation with human players, learning agents, and heuristic agents. Our evaluation shows that humans' performance is far beyond the agents' performance. Some agents, even with good normal task performance, perform significantly worse when there is a novelty, and the agents that can adapt to novelties typically adapt slower than humans. We promote the development of intelligent agents capable of performing at the human level or above when operating in open-world physical environments. Testbed website: https://github.com/phy-q/novphy
Measuring Board Game Distance
Jan 10, 2023This paper presents a general approach for measuring distances between board games within the Ludii general game system. These distances are calculated using a previously published set of general board game concepts, each of which represents a common game idea or shared property. Our results compare and contrast two different measures of distance, highlighting the subjective nature of such metrics and discussing the different ways that they can be interpreted.
The Ludii Game Description Language is Universal
May 03, 2022



There are several different game description languages (GDLs), each intended to allow wide ranges of arbitrary games (i.e., general games) to be described in a single higher-level language than general-purpose programming languages. Games described in such formats can subsequently be presented as challenges for automated general game playing agents, which are expected to be capable of playing any arbitrary game described in such a language without prior knowledge about the games to be played. The language used by the Ludii general game system was previously shown to be capable of representing equivalent games for any arbitrary, finite, deterministic, fully observable extensive-form game. In this paper, we prove its universality by extending this to include finite non-deterministic and imperfect-information games.
Spatial State-Action Features for General Games
Jan 17, 2022In many board games and other abstract games, patterns have been used as features that can guide automated game-playing agents. Such patterns or features often represent particular configurations of pieces, empty positions, etc., which may be relevant for a game's strategies. Their use has been particularly prevalent in the game of Go, but also many other games used as benchmarks for AI research. Simple, linear policies of such features are unlikely to produce state-of-the-art playing strength like the deep neural networks that have been more commonly used in recent years do. However, they typically require significantly fewer resources to train, which is paramount for large-scale studies of hundreds to thousands of distinct games. In this paper, we formulate a design and efficient implementation of spatial state-action features for general games. These are patterns that can be trained to incentivise or disincentivise actions based on whether or not they match variables of the state in a local area around action variables. We provide extensive details on several design and implementation choices, with a primary focus on achieving a high degree of generality to support a wide variety of different games using different board geometries or other graphs. Secondly, we propose an efficient approach for evaluating active features for any given set of features. In this approach, we take inspiration from heuristics used in problems such as SAT to optimise the order in which parts of patterns are matched and prune unnecessary evaluations. An empirical evaluation on 33 distinct games in the Ludii general game system demonstrates the efficiency of this approach in comparison to a naive baseline, as well as a baseline based on prefix trees.