 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatGPT4PCG 2 Competition: Prompt Engineering for Science Birds Level Generation
Mar 05, 2024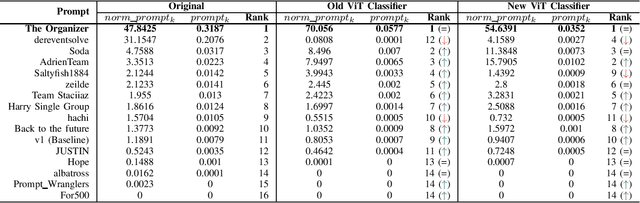

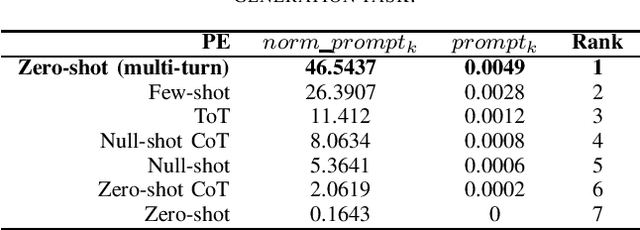
This paper presents the second ChatGPT4PCG competition at the 2024 IEEE Conference on Games. In this edition of the competition, we follow the first edition, but make several improvements and changes. We introduce a new evaluation metric along with allowing a more flexible format for participants' submissions and making several improvements to the evaluation pipeline. Continuing from the first edition, we aim to foster and explore the realm of prompt engineering (PE) for procedural content generation (PCG). While the first competition saw success, it was hindered by various limitations; we aim to mitigate these limitations in this edition. We introduce diversity as a new metric to discourage submissions aimed at producing repetitive structures. Furthermore, we allow submission of a Python program instead of a prompt text file for greater flexibility in implementing advanced PE approaches, which may require control flow, including conditions and iterations. We also make several improvements to the evaluation pipeline with a better classifier for similarity evaluation and better-performing function signatures. We thoroughly evaluate the effectiveness of the new metric and the improved classifier. Additionally, we perform an ablation study to select a function signature to instruct ChatGPT for level generation. Finally, we provide implementation examples of various PE techniques in Python and evaluate their preliminary performance. We hope this competition serves as a resource and platform for learning about PE and PCG in general.
Rapid Open-World Adaptation by Adaptation Principles Learning
Dec 18, 2023Novelty adaptation is the ability of an intelligent agent to adjust its behavior in response to changes in its environment. This is an important characteristic of intelligent agents, as it allows them to continue to function effectively in novel or unexpected situations, but still stands as a critical challenge for deep reinforcement learning (DRL). To tackle this challenge, we propose a simple yet effective novel method, NAPPING (Novelty Adaptation Principles Learning), that allows trained DRL agents to respond to different classes of novelties in open worlds rapidly. With NAPPING, DRL agents can learn to adjust the trained policy only when necessary. They can quickly generalize to similar novel situations without affecting the part of the trained policy that still works. To demonstrate the efficiency and efficacy of NAPPING, we evaluate our method on four action domains that are different in reward structures and the type of task. The domains are CartPole and MountainCar (classic control), CrossRoad (path-finding), and AngryBirds (physical reasoning). We compare NAPPING with standard online and fine-tuning DRL methods in CartPole, MountainCar and CrossRoad, and state-of-the-art methods in the more complicated AngryBirds domain. Our evaluation results demonstrate that with our proposed method, DRL agents can rapidly and effectively adjust to a wide range of novel situations across all tested domains.
Efficient Open-world Reinforcement Learning via Knowledge Distillation and Autonomous Rule Discovery
Nov 24, 2023Deep reinforcement learning suffers from catastrophic forgetting and sample inefficiency making it less applicable to the ever-changing real world. However, the ability to use previously learned knowledge is essential for AI agents to quickly adapt to novelties. Often, certain spatial information observed by the agent in the previous interactions can be leveraged to infer task-specific rules. Inferred rules can then help the agent to avoid potentially dangerous situations in the previously unseen states and guide the learning process increasing agent's novelty adaptation speed. In this work, we propose a general framework that is applicable to deep reinforcement learning agents. Our framework provides the agent with an autonomous way to discover the task-specific rules in the novel environments and self-supervise it's learning. We provide a rule-driven deep Q-learning agent (RDQ) as one possible implementation of that framework. We show that RDQ successfully extracts task-specific rules as it interacts with the world and uses them to drastically increase its learning efficiency. In our experiments, we show that the RDQ agent is significantly more resilient to the novelties than the baseline agents, and is able to detect and adapt to novel situations faster.
Physics-Based Task Generation through Causal Sequence of Physical Interactions
Aug 16, 2023



Performing tasks in a physical environment is a crucial yet challenging problem for AI systems operating in the real world. Physics simulation-based tasks are often employed to facilitate research that addresses this challenge. In this paper, first, we present a systematic approach for defining a physical scenario using a causal sequence of physical interactions between objects. Then, we propose a methodology for generating tasks in a physics-simulating environment using these defined scenarios as inputs. Our approach enables a better understanding of the granular mechanics required for solving physics-based tasks, thereby facilitating accurate evaluation of AI systems' physical reasoning capabilities. We demonstrate our proposed task generation methodology using the physics-based puzzle game Angry Birds and evaluate the generated tasks using a range of metrics, including physical stability, solvability using intended physical interactions, and accidental solvability using unintended solutions. We believe that the tasks generated using our proposed methodology can facilitate a nuanced evaluation of physical reasoning agents, thus paving the way for the development of agents for more sophisticated real-world applications.
ChatGPT4PCG Competition: Character-like Level Generation for Science Birds
Mar 28, 2023



This paper presents the first ChatGPT4PCG Competition at the 2023 IEEE Conference on Games. The objective of this competition is for participants to create effective prompts for ChatGPT--enabling it to generate Science Birds levels with high stability and character-like qualities--fully using their creativity as well as prompt engineering skills. ChatGPT is a conversational agent developed by OpenAI. Science Birds is selected as the competition platform because designing an Angry Birds-like level is not a trivial task due to the in-game gravity; the playability of the levels is determined by their stability. To lower the entry barrier to the competition, we limit the task to the generation of capitalized English alphabetical characters. Here, the quality of the generated levels is determined by their stability and similarity to the given characters. A sample prompt is provided to participants for their reference. An experiment is conducted to determine the effectiveness of its modified versions on level stability and similarity by testing them on several characters. To the best of our knowledge, we believe that ChatGPT4PCG is the first competition of its kind and hope to inspire enthusiasm for prompt engineering in procedural content generation.
NovPhy: A Testbed for Physical Reasoning in Open-world Environments
Mar 03, 2023



Due to the emergence of AI systems that interact with the physical environment, there is an increased interest in incorporating physical reasoning capabilities into those AI systems. But is it enough to only have physical reasoning capabilities to operate in a real physical environment? In the real world, we constantly face novel situations we have not encountered before. As humans, we are competent at successfully adapting to those situations. Similarly, an agent needs to have the ability to function under the impact of novelties in order to properly operate in an open-world physical environment. To facilitate the development of such AI systems, we propose a new testbed, NovPhy, that requires an agent to reason about physical scenarios in the presence of novelties and take actions accordingly. The testbed consists of tasks that require agents to detect and adapt to novelties in physical scenarios. To create tasks in the testbed, we develop eight novelties representing a diverse novelty space and apply them to five commonly encountered scenarios in a physical environment. According to our testbed design, we evaluate two capabilities of an agent: the performance on a novelty when it is applied to different physical scenarios and the performance on a physical scenario when different novelties are applied to it. We conduct a thorough evaluation with human players, learning agents, and heuristic agents. Our evaluation shows that humans' performance is far beyond the agents' performance. Some agents, even with good normal task performance, perform significantly worse when there is a novelty, and the agents that can adapt to novelties typically adapt slower than humans. We promote the development of intelligent agents capable of performing at the human level or above when operating in open-world physical environments. Testbed website: https://github.com/phy-q/novphy
Don't do it: Safer Reinforcement Learning With Rule-based Guidance
Dec 28, 2022



During training, reinforcement learning systems interact with the world without considering the safety of their actions. When deployed into the real world, such systems can be dangerous and cause harm to their surroundings. Often, dangerous situations can be mitigated by defining a set of rules that the system should not violate under any conditions. For example, in robot navigation, one safety rule would be to avoid colliding with surrounding objects and people. In this work, we define safety rules in terms of the relationships between the agent and objects and use them to prevent reinforcement learning systems from performing potentially harmful actions. We propose a new safe epsilon-greedy algorithm that uses safety rules to override agents' actions if they are considered to be unsafe. In our experiments, we show that a safe epsilon-greedy policy significantly increases the safety of the agent during training, improves the learning efficiency resulting in much faster convergence, and achieves better performance than the base model.
Measuring Difficulty of Novelty Reaction
Jul 28, 2022
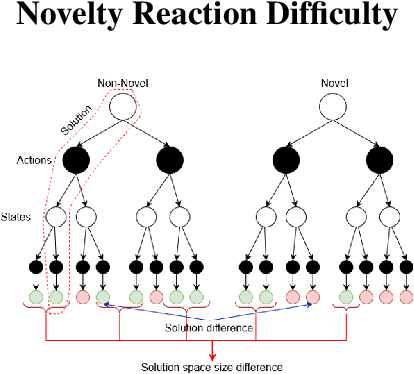

Current AI systems are designed to solve close-world problems with the assumption that the underlying world is remaining more or less the same. However, when dealing with real-world problems such assumptions can be invalid as sudden and unexpected changes can occur. To effectively deploy AI-powered systems in the real world, AI systems should be able to deal with open-world novelty quickly. Inevitably, dealing with open-world novelty raises an important question of novelty difficulty. Knowing whether one novelty is harder to deal with than another, can help researchers to train their systems systematically. In addition, it can also serve as a measurement of the performance of novelty robust AI systems. In this paper, we propose to define the novelty reaction difficulty as a relative difficulty of performing the known task after the introduction of the novelty. We propose a universal method that can be applied to approximate the difficulty. We present the approximations of the difficulty using our method and show how it aligns with the results of the evaluation of AI agents designed to deal with novelty.
Phy-Q: A Benchmark for Physical Reasoning
Aug 31, 2021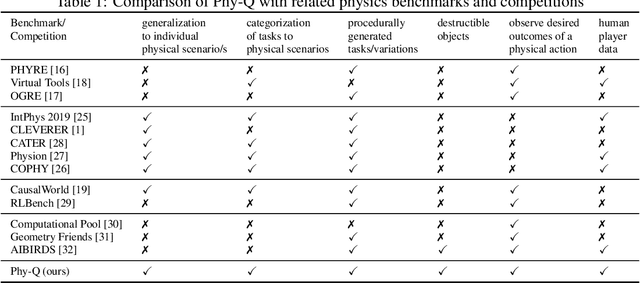

Humans are well-versed in reasoning about the behaviors of physical objects when choosing actions to accomplish tasks, while it remains a major challenge for AI. To facilitate research addressing this problem, we propose a new benchmark that requires an agent to reason about physical scenarios and take an action accordingly. Inspired by the physical knowledge acquired in infancy and the capabilities required for robots to operate in real-world environments, we identify 15 essential physical scenarios. For each scenario, we create a wide variety of distinct task templates, and we ensure all the task templates within the same scenario can be solved by using one specific physical rule. By having such a design, we evaluate two distinct levels of generalization, namely the local generalization and the broad generalization. We conduct an extensive evaluation with human players, learning agents with varying input types and architectures, and heuristic agents with different strategies. The benchmark gives a Phy-Q (physical reasoning quotient) score that reflects the physical reasoning ability of the agents. Our evaluation shows that 1) all agents fail to reach human performance, and 2) learning agents, even with good local generalization ability, struggle to learn the underlying physical reasoning rules and fail to generalize broadly. We encourage the development of intelligent agents with broad generalization abilities in physical domains.
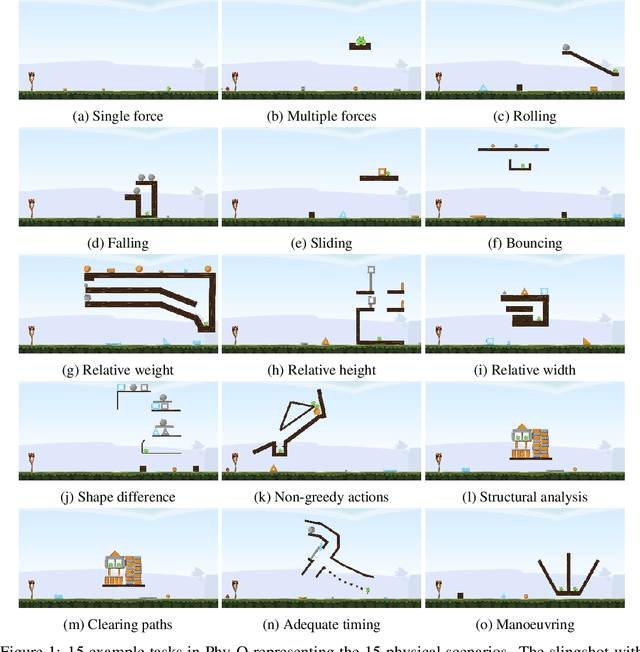
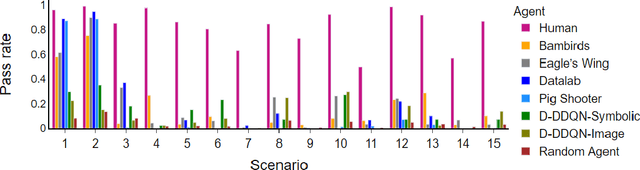
Hi-Phy: A Benchmark for Hierarchical Physical Reasoning
Jun 17, 2021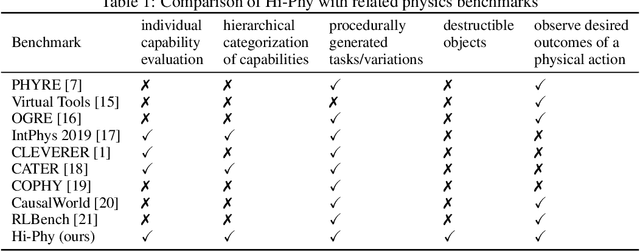


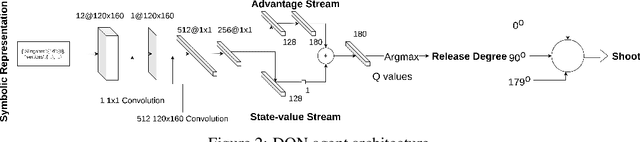
Reasoning about the behaviour of physical objects is a key capability of agents operating in physical worlds. Humans are very experienced in physical reasoning while it remains a major challenge for AI. To facilitate research addressing this problem, several benchmarks have been proposed recently. However, these benchmarks do not enable us to measure an agent's granular physical reasoning capabilities when solving a complex reasoning task. In this paper, we propose a new benchmark for physical reasoning that allows us to test individual physical reasoning capabilities. Inspired by how humans acquire these capabilities, we propose a general hierarchy of physical reasoning capabilities with increasing complexity. Our benchmark tests capabilities according to this hierarchy through generated physical reasoning tasks in the video game Angry Birds. This benchmark enables us to conduct a comprehensive agent evaluation by measuring the agent's granular physical reasoning capabilities. We conduct an evaluation with human players, learning agents, and heuristic agents and determine their capabilities. Our evaluation shows that learning agents, with good local generalization ability, still struggle to learn the underlying physical reasoning capabilities and perform worse than current state-of-the-art heuristic agents and humans. We believe that this benchmark will encourage researchers to develop intelligent agents with advanced, human-like physical reasoning capabilities. URL: https://github.com/Cheng-Xue/Hi-Phy