 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Based Task Generation through Causal Sequence of Physical Interactions
Aug 16, 2023



Performing tasks in a physical environment is a crucial yet challenging problem for AI systems operating in the real world. Physics simulation-based tasks are often employed to facilitate research that addresses this challenge. In this paper, first, we present a systematic approach for defining a physical scenario using a causal sequence of physical interactions between objects. Then, we propose a methodology for generating tasks in a physics-simulating environment using these defined scenarios as inputs. Our approach enables a better understanding of the granular mechanics required for solving physics-based tasks, thereby facilitating accurate evaluation of AI systems' physical reasoning capabilities. We demonstrate our proposed task generation methodology using the physics-based puzzle game Angry Birds and evaluate the generated tasks using a range of metrics, including physical stability, solvability using intended physical interactions, and accidental solvability using unintended solutions. We believe that the tasks generated using our proposed methodology can facilitate a nuanced evaluation of physical reasoning agents, thus paving the way for the development of agents for more sophisticated real-world applications.
NovPhy: A Testbed for Physical Reasoning in Open-world Environments
Mar 03, 2023



Due to the emergence of AI systems that interact with the physical environment, there is an increased interest in incorporating physical reasoning capabilities into those AI systems. But is it enough to only have physical reasoning capabilities to operate in a real physical environment? In the real world, we constantly face novel situations we have not encountered before. As humans, we are competent at successfully adapting to those situations. Similarly, an agent needs to have the ability to function under the impact of novelties in order to properly operate in an open-world physical environment. To facilitate the development of such AI systems, we propose a new testbed, NovPhy, that requires an agent to reason about physical scenarios in the presence of novelties and take actions accordingly. The testbed consists of tasks that require agents to detect and adapt to novelties in physical scenarios. To create tasks in the testbed, we develop eight novelties representing a diverse novelty space and apply them to five commonly encountered scenarios in a physical environment. According to our testbed design, we evaluate two capabilities of an agent: the performance on a novelty when it is applied to different physical scenarios and the performance on a physical scenario when different novelties are applied to it. We conduct a thorough evaluation with human players, learning agents, and heuristic agents. Our evaluation shows that humans' performance is far beyond the agents' performance. Some agents, even with good normal task performance, perform significantly worse when there is a novelty, and the agents that can adapt to novelties typically adapt slower than humans. We promote the development of intelligent agents capable of performing at the human level or above when operating in open-world physical environments. Testbed website: https://github.com/phy-q/novphy
Measuring Difficulty of Novelty Reaction
Jul 28, 2022
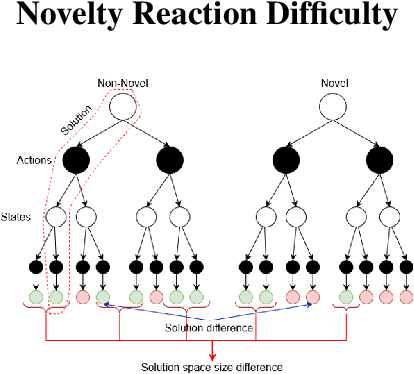

Current AI systems are designed to solve close-world problems with the assumption that the underlying world is remaining more or less the same. However, when dealing with real-world problems such assumptions can be invalid as sudden and unexpected changes can occur. To effectively deploy AI-powered systems in the real world, AI systems should be able to deal with open-world novelty quickly. Inevitably, dealing with open-world novelty raises an important question of novelty difficulty. Knowing whether one novelty is harder to deal with than another, can help researchers to train their systems systematically. In addition, it can also serve as a measurement of the performance of novelty robust AI systems. In this paper, we propose to define the novelty reaction difficulty as a relative difficulty of performing the known task after the introduction of the novelty. We propose a universal method that can be applied to approximate the difficulty. We present the approximations of the difficulty using our method and show how it aligns with the results of the evaluation of AI agents designed to deal with novelty.
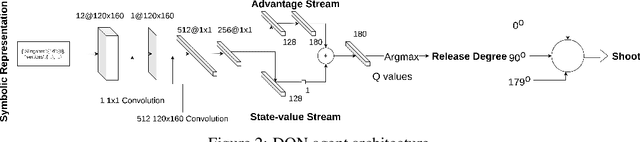
Phy-Q: A Benchmark for Physical Reasoning
Aug 31, 2021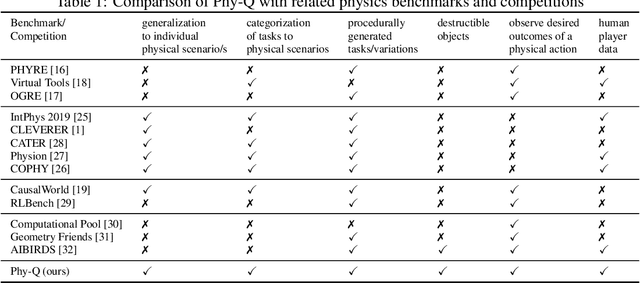
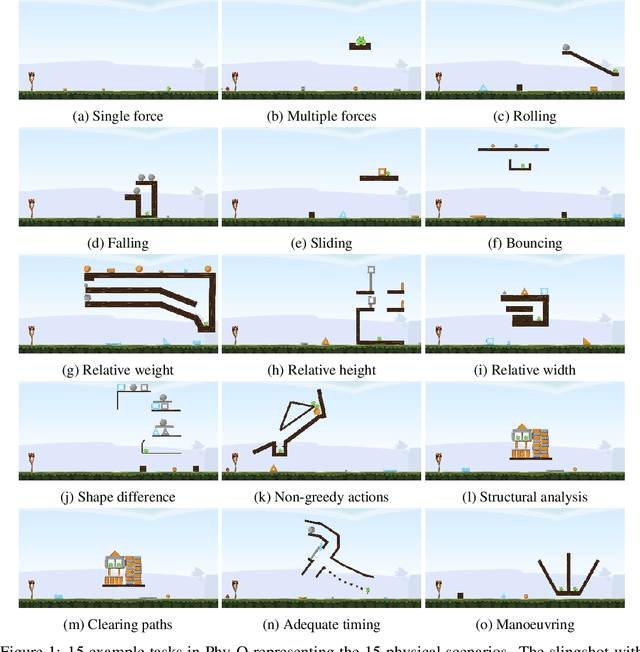

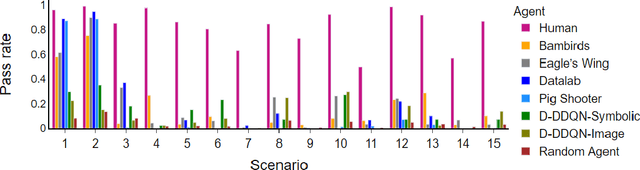
Humans are well-versed in reasoning about the behaviors of physical objects when choosing actions to accomplish tasks, while it remains a major challenge for AI. To facilitate research addressing this problem, we propose a new benchmark that requires an agent to reason about physical scenarios and take an action accordingly. Inspired by the physical knowledge acquired in infancy and the capabilities required for robots to operate in real-world environments, we identify 15 essential physical scenarios. For each scenario, we create a wide variety of distinct task templates, and we ensure all the task templates within the same scenario can be solved by using one specific physical rule. By having such a design, we evaluate two distinct levels of generalization, namely the local generalization and the broad generalization. We conduct an extensive evaluation with human players, learning agents with varying input types and architectures, and heuristic agents with different strategies. The benchmark gives a Phy-Q (physical reasoning quotient) score that reflects the physical reasoning ability of the agents. Our evaluation shows that 1) all agents fail to reach human performance, and 2) learning agents, even with good local generalization ability, struggle to learn the underlying physical reasoning rules and fail to generalize broadly. We encourage the development of intelligent agents with broad generalization abilities in physical domains.
Hi-Phy: A Benchmark for Hierarchical Physical Reasoning
Jun 17, 2021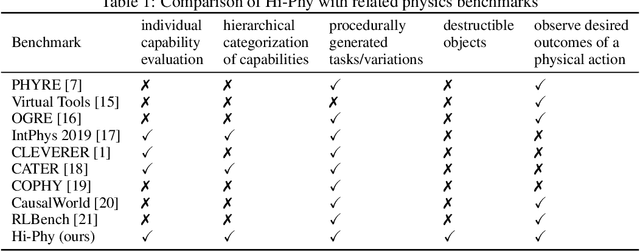


Reasoning about the behaviour of physical objects is a key capability of agents operating in physical worlds. Humans are very experienced in physical reasoning while it remains a major challenge for AI. To facilitate research addressing this problem, several benchmarks have been proposed recently. However, these benchmarks do not enable us to measure an agent's granular physical reasoning capabilities when solving a complex reasoning task. In this paper, we propose a new benchmark for physical reasoning that allows us to test individual physical reasoning capabilities. Inspired by how humans acquire these capabilities, we propose a general hierarchy of physical reasoning capabilities with increasing complexity. Our benchmark tests capabilities according to this hierarchy through generated physical reasoning tasks in the video game Angry Birds. This benchmark enables us to conduct a comprehensive agent evaluation by measuring the agent's granular physical reasoning capabilities. We conduct an evaluation with human players, learning agents, and heuristic agents and determine their capabilities. Our evaluation shows that learning agents, with good local generalization ability, still struggle to learn the underlying physical reasoning capabilities and perform worse than current state-of-the-art heuristic agents and humans. We believe that this benchmark will encourage researchers to develop intelligent agents with advanced, human-like physical reasoning capabilities. URL: https://github.com/Cheng-Xue/Hi-Phy
The Difficulty of Novelty Detection in Open-World Physical Domains: An Application to Angry Birds
Jun 16, 2021

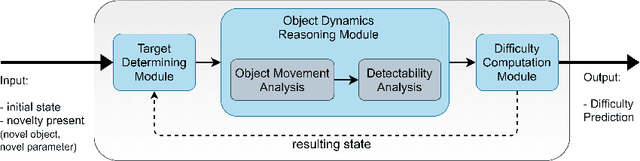
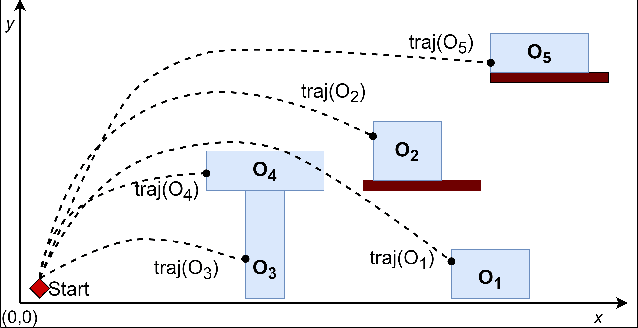
Detecting and responding to novel situations in open-world environments is a key capability of human cognition. Current artificial intelligence (AI) researchers strive to develop systems that can perform in open-world environments. Novelty detection is an important ability of such AI systems. In an open-world, novelties appear in various forms and the difficulty to detect them varies. Therefore, to accurately evaluate the detection capability of AI systems, it is necessary to investigate the difficulty to detect novelties. In this paper, we propose a qualitative physics-based method to quantify the difficulty of novelty detection focusing on open-world physical domains. We apply our method in a popular physics simulation game, Angry Birds. We conduct an experiment with human players with different novelties in Angry Birds to validate our method. Results indicate that the calculated difficulty values are in line with the detection difficulty of the human players.
Deceptive Level Generation for Angry Birds
Jun 03, 2021


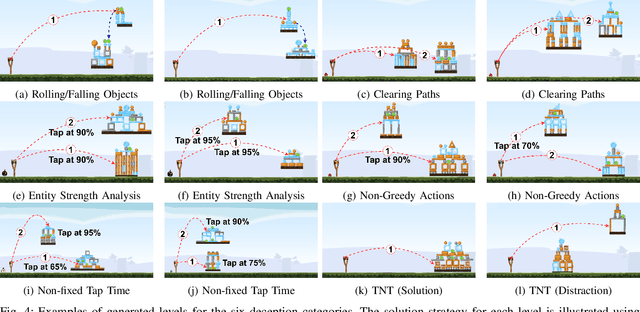
The Angry Birds AI competition has been held over many years to encourage the development of AI agents that can play Angry Birds game levels better than human players. Many different agents with various approaches have been employed over the competition's lifetime to solve this task. Even though the performance of these agents has increased significantly over the past few years, they still show major drawbacks in playing deceptive levels. This is because most of the current agents try to identify the best next shot rather than planning an effective sequence of shots. In order to encourage advancements in such agents, we present an automated methodology to generate deceptive game levels for Angry Birds. Even though there are many existing content generators for Angry Birds, they do not focus on generating deceptive levels. In this paper, we propose a procedure to generate deceptive levels for six deception categories that can fool the state-of-the-art Angry Birds playing AI agents. Our results show that generated deceptive levels exhibit similar characteristics of human-created deceptive levels. Additionally, we define metrics to measure the stability, solvability, and degree of deception of the generated levels.