 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhySe-RPO: Physics and Semantics Guided Relative Policy Optimization for Diffusion-Based Surgical Smoke Removal
Mar 25, 2026Surgical smoke severely degrades intraoperative video quality, obscuring anatomical structures and limiting surgical perception. Existing learning-based desmoking approaches rely on scarce paired supervision and deterministic restoration pipelines, making it difficult to perform exploration or reinforcement-driven refinement under real surgical conditions. We propose PhySe-RPO, a diffusion restoration framework optimized through Physics- and Semantics-Guided Relative Policy Optimization. The core idea is to transform deterministic restoration into a stochastic policy, enabling trajectory-level exploration and critic-free updates via group-relative optimization. A physics-guided reward imposes illumination and color consistency, while a visual-concept semantic reward learned from CLIP-based surgical concepts promotes smoke-free and anatomically coherent restoration. Together with a reference-free perceptual constraint, PhySe-RPO produces results that are physically consistent, semantically faithful, and clinically interpretable across synthetic and real robotic surgical datasets, providing a principled route to robust diffusion-based restoration under limited paired supervision.
Noise-aware few-shot learning through bi-directional multi-view prompt alignment
Mar 12, 2026Vision-language models offer strong few-shot capability through prompt tuning but remain vulnerable to noisy labels, which can corrupt prompts and degrade cross-modal alignment. Existing approaches struggle because they often lack the ability to model fine-grained semantic cues and to adaptively separate clean from noisy signals. To address these challenges, we propose NA-MVP, a framework for Noise-Aware few-shot learning through bi-directional Multi-View Prompt alignment. NA-MVP is built upon a key conceptual shift: robust prompt learning requires moving from global matching to region-aware alignment that explicitly distinguishes clean cues from noisy ones. To realize this, NA-MVP employs (1) multi-view prompts combined with unbalanced optimal transport to achieve fine-grained patch-to-prompt correspondence while suppressing unreliable regions; (2) a bi-directional prompt design that captures complementary clean-oriented and noise-aware cues, enabling the model to focus on stable semantics; and (3) an alignment-guided selective refinement strategy that uses optimal transport to correct only mislabeled samples while retaining reliable data. Experiments on synthetic and real-world noisy benchmarks demonstrate that NA-MVP consistently outperforms state-of-the-art baselines, confirming its effectiveness in enabling robust few-shot learning under noisy supervision.
CauCLIP: Bridging the Sim-to-Real Gap in Surgical Video Understanding via Causality-Inspired Vision-Language Modeling
Feb 06, 2026Surgical phase recognition is a critical component for context-aware decision support in intelligent operating rooms, yet training robust models is hindered by limited annotated clinical videos and large domain gaps between synthetic and real surgical data. To address this, we propose CauCLIP, a causality-inspired vision-language framework that leverages CLIP to learn domain-invariant representations for surgical phase recognition without access to target domain data. Our approach integrates a frequency-based augmentation strategy to perturb domain-specific attributes while preserving semantic structures, and a causal suppression loss that mitigates non-causal biases and reinforces causal surgical features. These components are combined in a unified training framework that enables the model to focus on stable causal factors underlying surgical workflows. Experiments on the SurgVisDom hard adaptation benchmark demonstrate that our method substantially outperforms all competing approaches, highlighting the effectiveness of causality-guided vision-language models for domain-generalizable surgical video understanding.
Statistics-Informed Parameterized Quantum Circuit via Maximum Entropy Principle for Data Science and Finance
Jun 03, 2024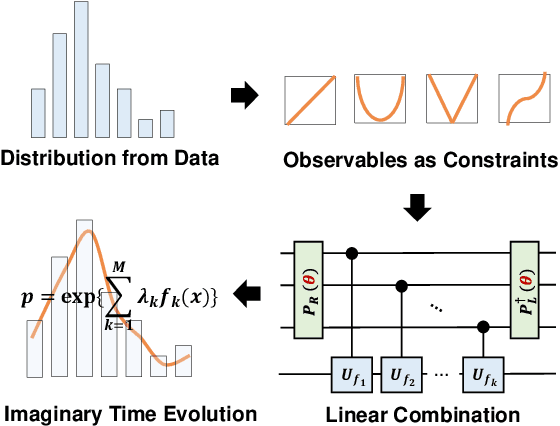
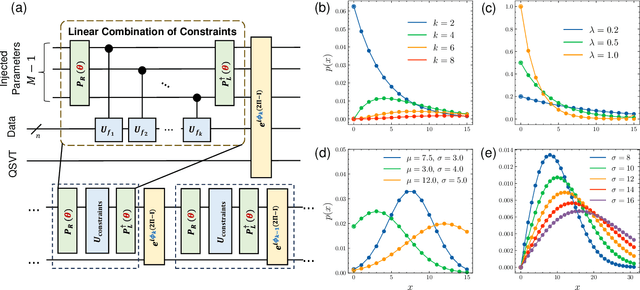
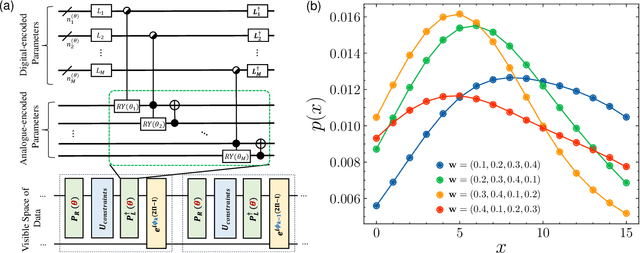
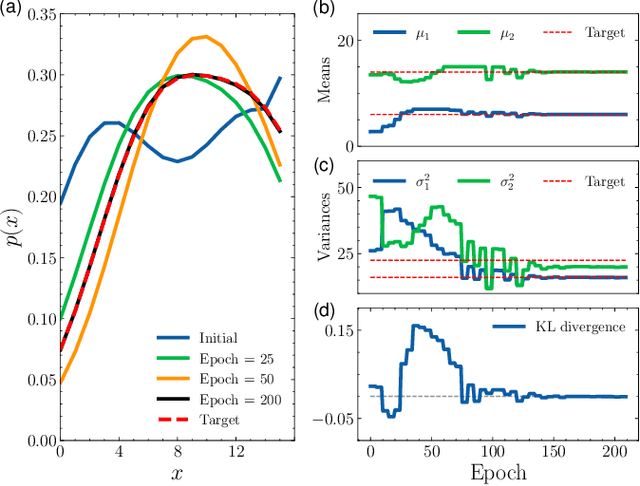
Quantum machine learning has demonstrated significant potential in solving practical problems, particularly in statistics-focused areas such as data science and finance. However, challenges remain in preparing and learning statistical models on a quantum processor due to issues with trainability and interpretability. In this letter, we utilize the maximum entropy principle to design a statistics-informed parameterized quantum circuit (SI-PQC) that efficiently prepares and trains quantum computational statistical models, including arbitrary distributions and their weighted mixtures. The SI-PQC features a static structure with trainable parameters, enabling in-depth optimized circuit compilation, exponential reductions in resource and time consumption, and improved trainability and interpretability for learning quantum states and classical model parameters simultaneously. As an efficient subroutine for preparing and learning in various quantum algorithms, the SI-PQC addresses the input bottleneck and facilitates the injection of prior knowledge.
SpineCLUE: Automatic Vertebrae Identification Using Contrastive Learning and Uncertainty Estimation
Jan 14, 2024Vertebrae identification in arbitrary fields-of-view plays a crucial role in diagnosing spine disease. Most spine CT contain only local regions, such as the neck, chest, and abdomen. Therefore, identification should not depend on specific vertebrae or a particular number of vertebrae being visible. Existing methods at the spine-level are unable to meet this challenge. In this paper, we propose a three-stage method to address the challenges in 3D CT vertebrae identification at vertebrae-level. By sequentially performing the tasks of vertebrae localization, segmentation, and identification, the anatomical prior information of the vertebrae is effectively utilized throughout the process. Specifically, we introduce a dual-factor density clustering algorithm to acquire localization information for individual vertebra, thereby facilitating subsequent segmentation and identification processes. In addition, to tackle the issue of interclass similarity and intra-class variability, we pre-train our identification network by using a supervised contrastive learning method. To further optimize the identification results, we estimated the uncertainty of the classification network and utilized the message fusion module to combine the uncertainty scores, while aggregating global information about the spine. Our method achieves state-of-the-art results on the VerSe19 and VerSe20 challenge benchmarks. Additionally, our approach demonstrates outstanding generalization performance on an collected dataset containing a wide range of abnormal cases.
Rapid Open-World Adaptation by Adaptation Principles Learning
Dec 18, 2023Novelty adaptation is the ability of an intelligent agent to adjust its behavior in response to changes in its environment. This is an important characteristic of intelligent agents, as it allows them to continue to function effectively in novel or unexpected situations, but still stands as a critical challenge for deep reinforcement learning (DRL). To tackle this challenge, we propose a simple yet effective novel method, NAPPING (Novelty Adaptation Principles Learning), that allows trained DRL agents to respond to different classes of novelties in open worlds rapidly. With NAPPING, DRL agents can learn to adjust the trained policy only when necessary. They can quickly generalize to similar novel situations without affecting the part of the trained policy that still works. To demonstrate the efficiency and efficacy of NAPPING, we evaluate our method on four action domains that are different in reward structures and the type of task. The domains are CartPole and MountainCar (classic control), CrossRoad (path-finding), and AngryBirds (physical reasoning). We compare NAPPING with standard online and fine-tuning DRL methods in CartPole, MountainCar and CrossRoad, and state-of-the-art methods in the more complicated AngryBirds domain. Our evaluation results demonstrate that with our proposed method, DRL agents can rapidly and effectively adjust to a wide range of novel situations across all tested domains.
Efficient Open-world Reinforcement Learning via Knowledge Distillation and Autonomous Rule Discovery
Nov 24, 2023Deep reinforcement learning suffers from catastrophic forgetting and sample inefficiency making it less applicable to the ever-changing real world. However, the ability to use previously learned knowledge is essential for AI agents to quickly adapt to novelties. Often, certain spatial information observed by the agent in the previous interactions can be leveraged to infer task-specific rules. Inferred rules can then help the agent to avoid potentially dangerous situations in the previously unseen states and guide the learning process increasing agent's novelty adaptation speed. In this work, we propose a general framework that is applicable to deep reinforcement learning agents. Our framework provides the agent with an autonomous way to discover the task-specific rules in the novel environments and self-supervise it's learning. We provide a rule-driven deep Q-learning agent (RDQ) as one possible implementation of that framework. We show that RDQ successfully extracts task-specific rules as it interacts with the world and uses them to drastically increase its learning efficiency. In our experiments, we show that the RDQ agent is significantly more resilient to the novelties than the baseline agents, and is able to detect and adapt to novel situations faster.
Morphology-inspired Unsupervised Gland Segmentation via Selective Semantic Grouping
Jul 22, 2023Designing deep learning algorithms for gland segmentation is crucial for automatic cancer diagnosis and prognosis, yet the expensive annotation cost hinders the development and application of this technology. In this paper, we make a first attempt to explore a deep learning method for unsupervised gland segmentation, where no manual annotations are required. Existing unsupervised semantic segmentation methods encounter a huge challenge on gland images: They either over-segment a gland into many fractions or under-segment the gland regions by confusing many of them with the background. To overcome this challenge, our key insight is to introduce an empirical cue about gland morphology as extra knowledge to guide the segmentation process. To this end, we propose a novel Morphology-inspired method via Selective Semantic Grouping. We first leverage the empirical cue to selectively mine out proposals for gland sub-regions with variant appearances. Then, a Morphology-aware Semantic Grouping module is employed to summarize the overall information about the gland by explicitly grouping the semantics of its sub-region proposals. In this way, the final segmentation network could learn comprehensive knowledge about glands and produce well-delineated, complete predictions. We conduct experiments on GlaS dataset and CRAG dataset. Our method exceeds the second-best counterpart over 10.56% at mIOU.
Knowledge Boosting: Rethinking Medical Contrastive Vision-Language Pre-Training
Jul 17, 2023



The foundation models based on pre-training technology have significantly advanced artificial intelligence from theoretical to practical applications. These models have facilitated the feasibility of computer-aided diagnosis for widespread use. Medical contrastive vision-language pre-training, which does not require human annotations, is an effective approach for guiding representation learning using description information in diagnostic reports. However, the effectiveness of pre-training is limited by the large-scale semantic overlap and shifting problems in medical field. To address these issues, we propose the Knowledge-Boosting Contrastive Vision-Language Pre-training framework (KoBo), which integrates clinical knowledge into the learning of vision-language semantic consistency. The framework uses an unbiased, open-set sample-wise knowledge representation to measure negative sample noise and supplement the correspondence between vision-language mutual information and clinical knowledge. Extensive experiments validate the effect of our framework on eight tasks including classification, segmentation, retrieval, and semantic relatedness, achieving comparable or better performance with the zero-shot or few-shot settings. Our code is open on https://github.com/ChenXiaoFei-CS/KoBo.
NovPhy: A Testbed for Physical Reasoning in Open-world Environments
Mar 03, 2023



Due to the emergence of AI systems that interact with the physical environment, there is an increased interest in incorporating physical reasoning capabilities into those AI systems. But is it enough to only have physical reasoning capabilities to operate in a real physical environment? In the real world, we constantly face novel situations we have not encountered before. As humans, we are competent at successfully adapting to those situations. Similarly, an agent needs to have the ability to function under the impact of novelties in order to properly operate in an open-world physical environment. To facilitate the development of such AI systems, we propose a new testbed, NovPhy, that requires an agent to reason about physical scenarios in the presence of novelties and take actions accordingly. The testbed consists of tasks that require agents to detect and adapt to novelties in physical scenarios. To create tasks in the testbed, we develop eight novelties representing a diverse novelty space and apply them to five commonly encountered scenarios in a physical environment. According to our testbed design, we evaluate two capabilities of an agent: the performance on a novelty when it is applied to different physical scenarios and the performance on a physical scenario when different novelties are applied to it. We conduct a thorough evaluation with human players, learning agents, and heuristic agents. Our evaluation shows that humans' performance is far beyond the agents' performance. Some agents, even with good normal task performance, perform significantly worse when there is a novelty, and the agents that can adapt to novelties typically adapt slower than humans. We promote the development of intelligent agents capable of performing at the human level or above when operating in open-world physical environments. Testbed website: https://github.com/phy-q/novphy