 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhy-Q: A Benchmark for Physical Reasoning
Paper and Code
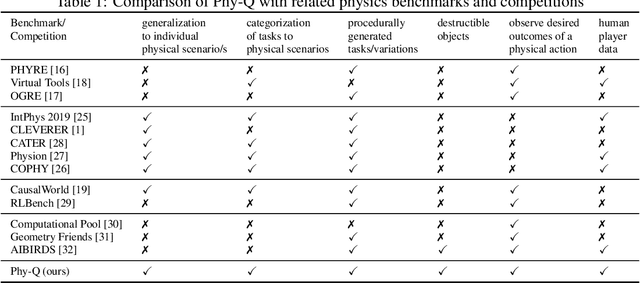
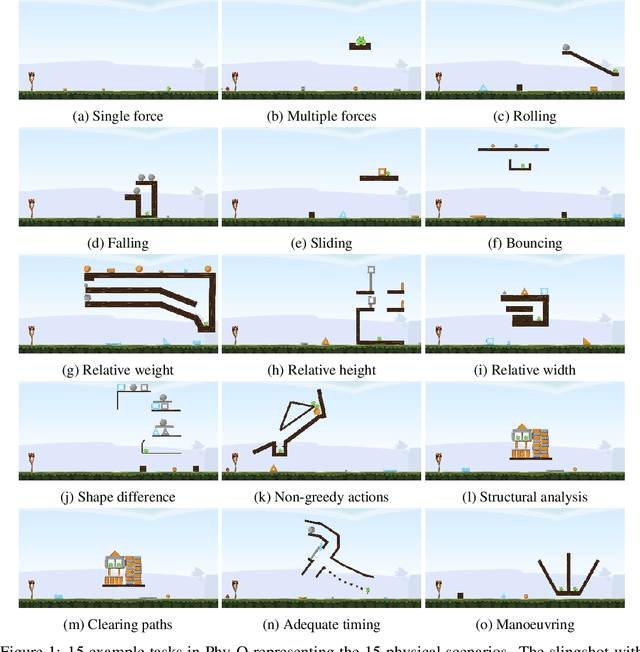

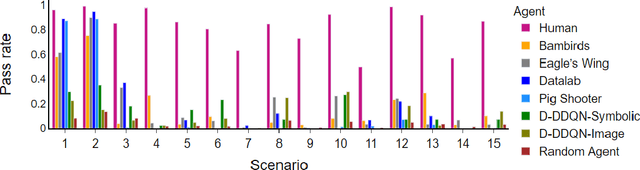
Humans are well-versed in reasoning about the behaviors of physical objects when choosing actions to accomplish tasks, while it remains a major challenge for AI. To facilitate research addressing this problem, we propose a new benchmark that requires an agent to reason about physical scenarios and take an action accordingly. Inspired by the physical knowledge acquired in infancy and the capabilities required for robots to operate in real-world environments, we identify 15 essential physical scenarios. For each scenario, we create a wide variety of distinct task templates, and we ensure all the task templates within the same scenario can be solved by using one specific physical rule. By having such a design, we evaluate two distinct levels of generalization, namely the local generalization and the broad generalization. We conduct an extensive evaluation with human players, learning agents with varying input types and architectures, and heuristic agents with different strategies. The benchmark gives a Phy-Q (physical reasoning quotient) score that reflects the physical reasoning ability of the agents. Our evaluation shows that 1) all agents fail to reach human performance, and 2) learning agents, even with good local generalization ability, struggle to learn the underlying physical reasoning rules and fail to generalize broadly. We encourage the development of intelligent agents with broad generalization abilities in physical domains.