 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Bio-inspired Heuristically Accelerated Reinforcement Learning for Adaptive Underwater Multi-Agents Behaviour
Feb 10, 2025

This paper describes the problem of coordination of an autonomous Multi-Agent System which aims to solve the coverage planning problem in a complex environment. The considered applications are the detection and identification of objects of interest while covering an area. These tasks, which are highly relevant for space applications, are also of interest among various domains including the underwater context, which is the focus of this study. In this context, coverage planning is traditionally modelled as a Markov Decision Process where a coordinated MAS, a swarm of heterogeneous autonomous underwater vehicles, is required to survey an area and search for objects. This MDP is associated with several challenges: environment uncertainties, communication constraints, and an ensemble of hazards, including time-varying and unpredictable changes in the underwater environment. MARL algorithms can solve highly non-linear problems using deep neural networks and display great scalability against an increased number of agents. Nevertheless, most of the current results in the underwater domain are limited to simulation due to the high learning time of MARL algorithms. For this reason, a novel strategy is introduced to accelerate this convergence rate by incorporating biologically inspired heuristics to guide the policy during training. The PSO method, which is inspired by the behaviour of a group of animals, is selected as a heuristic. It allows the policy to explore the highest quality regions of the action and state spaces, from the beginning of the training, optimizing the exploration/exploitation trade-off. The resulting agent requires fewer interactions to reach optimal performance. The method is applied to the MSAC algorithm and evaluated for a 2D covering area mission in a continuous control environment.
PID Tuning using Cross-Entropy Deep Learning: a Lyapunov Stability Analysis
Apr 18, 2024Underwater Unmanned Vehicles (UUVs) have to constantly compensate for the external disturbing forces acting on their body. Adaptive Control theory is commonly used there to grant the control law some flexibility in its response to process variation. Today, learning-based (LB) adaptive methods are leading the field where model-based control structures are combined with deep model-free learning algorithms. This work proposes experiments and metrics to empirically study the stability of such a controller. We perform this stability analysis on a LB adaptive control system whose adaptive parameters are determined using a Cross-Entropy Deep Learning method.
Sim-to-Real Transfer of Adaptive Control Parameters for AUV Stabilization under Current Disturbance
Oct 17, 2023Learning-based adaptive control methods hold the premise of enabling autonomous agents to reduce the effect of process variations with minimal human intervention. However, its application to autonomous underwater vehicles (AUVs) has so far been restricted due to 1) unknown dynamics under the form of sea current disturbance that we can not model properly nor measure due to limited sensor capability and 2) the nonlinearity of AUVs tasks where the controller response at some operating points must be overly conservative in order to satisfy the specification at other operating points. Deep Reinforcement Learning (DRL) can alleviates these limitations by training general-purpose neural network policies, but applications of DRL algorithms to AUVs have been restricted to simulated environments, due to their inherent high sample complexity and distribution shift problem. This paper presents a novel approach, merging the Maximum Entropy Deep Reinforcement Learning framework with a classic model-based control architecture, to formulate an adaptive controller. Within this framework, we introduce a Sim-to-Real transfer strategy comprising the following components: a bio-inspired experience replay mechanism, an enhanced domain randomisation technique, and an evaluation protocol executed on a physical platform. Our experimental assessments demonstrate that this method effectively learns proficient policies from suboptimal simulated models of the AUV, resulting in control performance 3 times higher when transferred to a real-world vehicle, compared to its model-based nonadaptive but optimal counterpart.
Learning-based vs Model-free Adaptive Control of a MAV under Wind Gust
Jan 29, 2021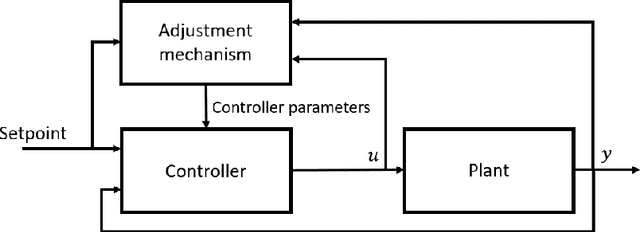
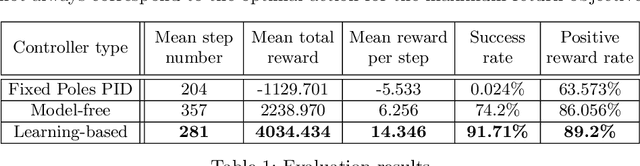
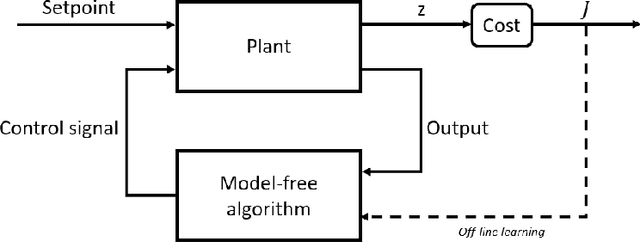

Navigation problems under unknown varying conditions are among the most important and well-studied problems in the control field. Classic model-based adaptive control methods can be applied only when a convenient model of the plant or environment is provided. Recent model-free adaptive control methods aim at removing this dependency by learning the physical characteristics of the plant and/or process directly from sensor feedback. Although there have been prior attempts at improving these techniques, it remains an open question as to whether it is possible to cope with real-world uncertainties in a control system that is fully based on either paradigm. We propose a conceptually simple learning-based approach composed of a full state feedback controller, tuned robustly by a deep reinforcement learning framework based on the Soft Actor-Critic algorithm. We compare it, in realistic simulations, to a model-free controller that uses the same deep reinforcement learning framework for the control of a micro aerial vehicle under wind gust. The results indicate the great potential of learning-based adaptive control methods in modern dynamical systems.
Sim-to-Real Transfer with Incremental Environment Complexity for Reinforcement Learning of Depth-Based Robot Navigation
Apr 30, 2020
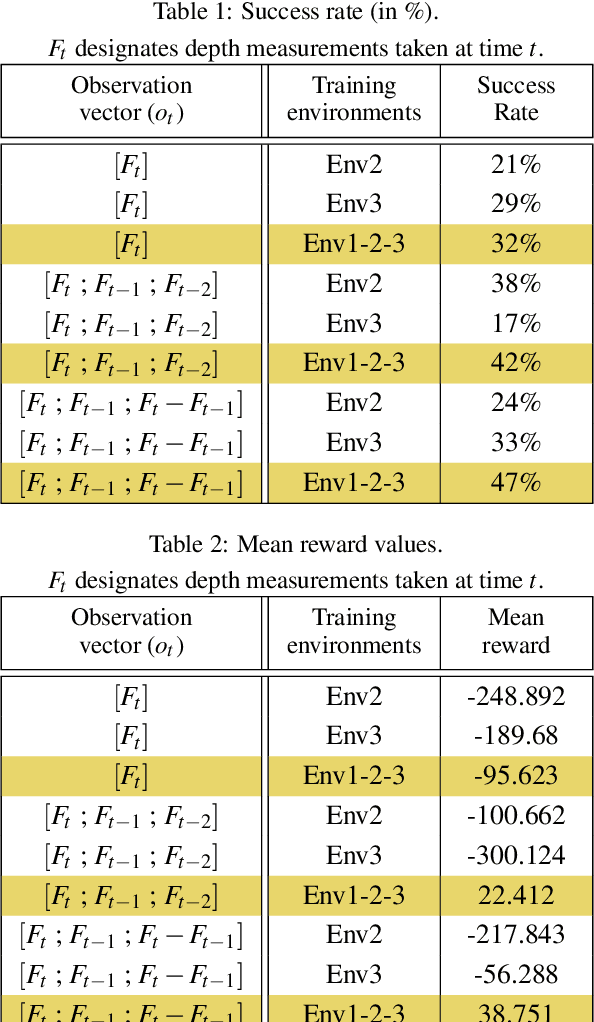
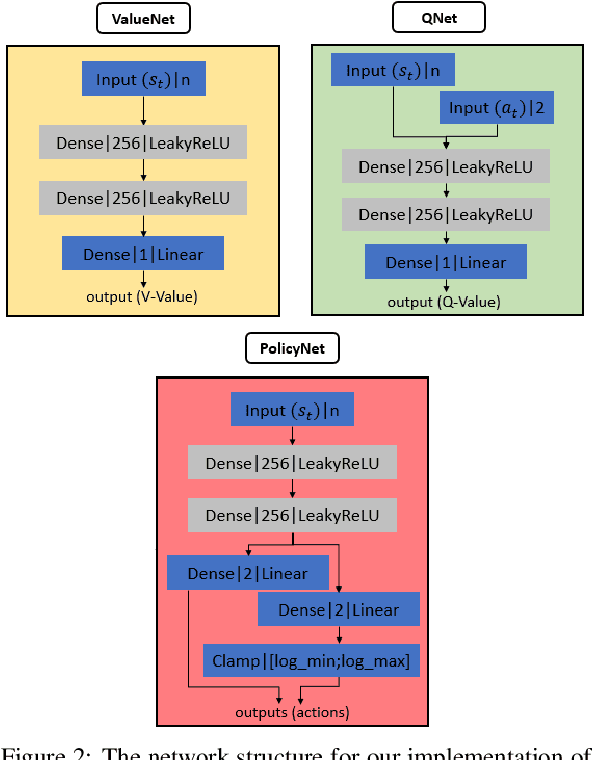
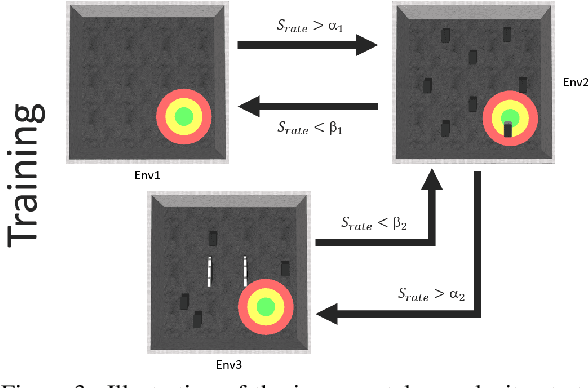
Transferring learning-based models to the real world remains one of the hardest problems in model-free control theory. Due to the cost of data collection on a real robot and the limited sample efficiency of Deep Reinforcement Learning algorithms, models are usually trained in a simulator which theoretically provides an infinite amount of data. Despite offering unbounded trial and error runs, the reality gap between simulation and the physical world brings little guarantee about the policy behavior in real operation. Depending on the problem, expensive real fine-tuning and/or a complex domain randomization strategy may be required to produce a relevant policy. In this paper, a Soft-Actor Critic (SAC) training strategy using incremental environment complexity is proposed to drastically reduce the need for additional training in the real world. The application addressed is depth-based mapless navigation, where a mobile robot should reach a given waypoint in a cluttered environment with no prior mapping information. Experimental results in simulated and real environments are presented to assess quantitatively the efficiency of the proposed approach, which demonstrated a success rate twice higher than a naive strategy.
Exploiting Physical Contacts for Robustness Improvement of a Dot-Painting Mission by a Micro Air Vehicle
Jun 15, 2019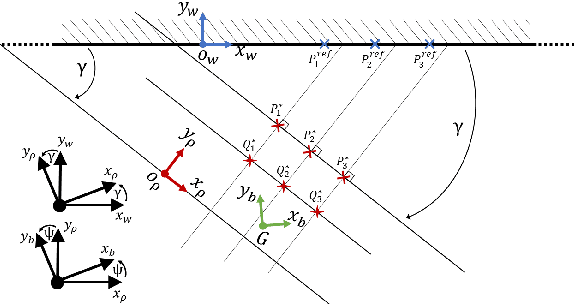
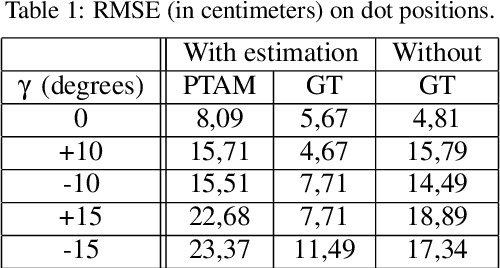
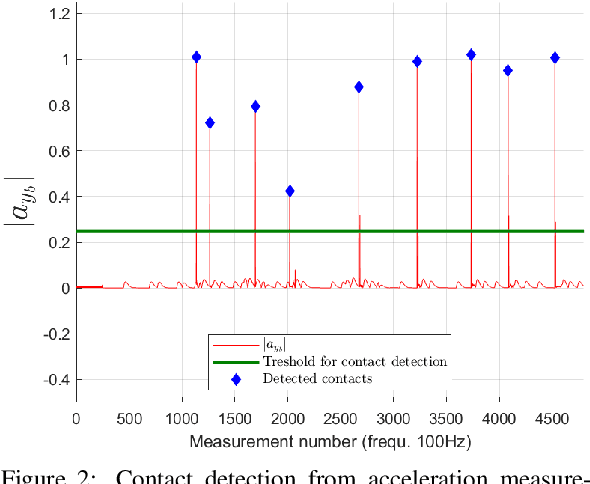
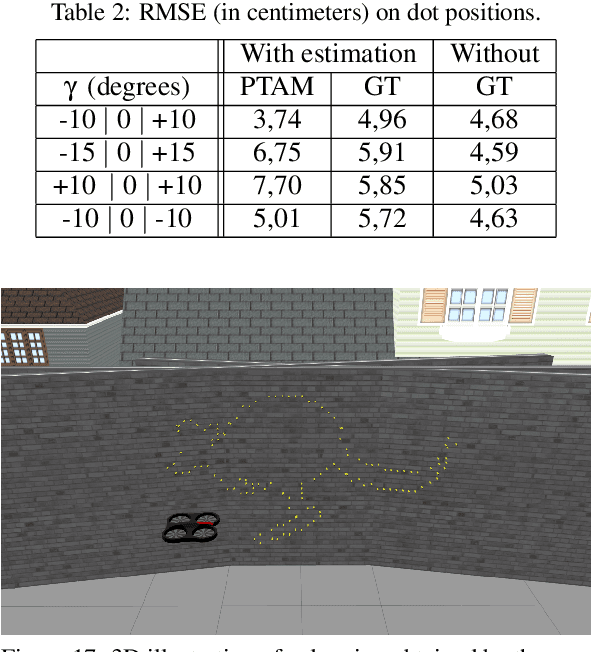
In this paper we address the problem of dot painting on a wall by a quadrotor Micro Air Vehicle (MAV), using on-board low cost sensors (monocular camera and IMU) for localization. A method is proposed to cope with uncertainties on the initial positioning of the MAV with respect to the wall and to deal with walls composed of multiple segments. This method is based on an online estimation algorithm that makes use of information of physical contacts detected by the drone during the flight to improve the positioning accuracy of the painted dots. Simulation results are presented to assess quantitatively the efficiency of the proposed approaches.