 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Causal-Origin Taxonomy of Distributional Shifts in Reinforcement Learning
Jun 15, 2026Reinforcement learning (RL) systems often degrade when operating conditions differ from those previously encountered, reflecting distributional shifts in the underlying data-generating process. Such shifts may occur between training and evaluation, as in In-Distribution (ID) and Out-of-Distribution (OOD) generalization, or within non-stationary settings where environment dynamics evolve over time. However, the formal relationship between these views remains unclear, and existing work mainly focuses on mitigation rather than the causal origin of shift within the agent-environment interaction. This work develops a unified causal-origin taxonomy that characterizes sources of distributional shift in RL and relates ID/OOD generalization to non-stationary settings. We transfer the classical dataset-shift principle from supervised learning to RL by reformulating distributional shift in terms of the generative interaction process. Using a Partially Observable Markov Decision Process (POMDP), we decompose the interaction into structural components, including the state distribution, observation process, policy, reward, and transition dynamics, together with the shifted-time boundary. The proposed taxonomy distinguishes internal, agent-driven, and external, environment-driven, distributional shifts. The shifted-time boundary perspective further characterizes explicit, implicit, and hybrid shifts. This formulation unifies ID/OOD generalization and non-stationarity as structured changes in the underlying process. We also introduce an evaluation framework for measuring shift impact and adaptation through performance degradation and recovery metrics. By grounding distributional shift in the causal-origin structure of RL, this work supports systematic analysis of robustness under distributional shift.
3D Underwater Path Planning via Generative Flow Field Surrogates
Jun 04, 2026Autonomous underwater vehicle (AUV) launch and recovery (LAR) into the hull of an advancing host platform requires traversal of a complex, three-dimensional propeller wake whose hydrodynamic structure cannot be characterised by a uniform current model. High-fidelity Reynolds-Averaged Navier-Stokes (RANS) Computational Fluid Dynamics (CFD) simulations resolve this structure with sufficient accuracy for path planning, but their computational cost renders them impractical for onboard use. We address this gap by integrating two conditional generative adversarial network (cGAN) architectures -- a regularised PatchGAN and a 2D3DGAN with self-attention -- as drop-in replacements for RANS CFD data within a three-dimensional, energy-weighted A* path planning framework. Both generators are driven by a hierarchical pipeline that synthesises full $128^3$ voxel flow field volumes from scalar operating condition inputs alone, with end-to-end inference times of approximately 28-146 $μ$s, compared to hours for a single RANS computation. We benchmark all four environmental knowledge levels: uniform current, ground-truth CFD, PatchGAN, and 2D3DGAN~SA across 19,800 independently generated trajectories spanning 550 distinct flow conditions. Full CFD wake knowledge reduces energy expenditure by 5.7-12.5% and high-velocity wake-core encounters by up to 77.8% relative to uniform-current planning, with both benefits scaling with operating severity. The cGAN surrogates recover approximately 45-60% of the CFD energy benefit and high-velocity cell avoidance benefit while operating at inference speeds compatible with edge device use. These results provide the first systematic quantification of the downstream path planning value of cGAN-predicted hydrodynamic fields in a three-dimensional maritime robotics application.
WAKESET: A Large-Scale, High-Reynolds Number Flow Dataset for Machine Learning of Turbulent Wake Dynamics
Feb 01, 2026Machine learning (ML) offers transformative potential for computational fluid dynamics (CFD), promising to accelerate simulations, improve turbulence modelling, and enable real-time flow prediction and control-capabilities that could fundamentally change how engineers approach fluid dynamics problems. However, the exploration of ML in fluid dynamics is critically hampered by the scarcity of large, diverse, and high-fidelity datasets suitable for training robust models. This limitation is particularly acute for highly turbulent flows, which dominate practical engineering applications yet remain computationally prohibitive to simulate at scale. High-Reynolds number turbulent datasets are essential for ML models to learn the complex, multi-scale physics characteristic of real-world flows, enabling generalisation beyond the simplified, low-Reynolds number regimes often represented in existing datasets. This paper introduces WAKESET, a novel, large-scale CFD dataset of highly turbulent flows, designed to address this critical gap. The dataset captures the complex hydrodynamic interactions during the underwater recovery of an autonomous underwater vehicle by a larger extra-large uncrewed underwater vehicle. It comprises 1,091 high-fidelity Reynolds-Averaged Navier-Stokes simulations, augmented to 4,364 instances, covering a wide operational envelope of speeds (up to Reynolds numbers of 1.09 x 10^8) and turning angles. This work details the motivation for this new dataset by reviewing existing resources, outlines the hydrodynamic modelling and validation underpinning its creation, and describes its structure. The dataset's focus on a practical engineering problem, its scale, and its high turbulence characteristics make it a valuable resource for developing and benchmarking ML models for flow field prediction, surrogate modelling, and autonomous navigation in complex underwater environments.
Improving Underwater Acoustic Classification Through Learnable Gabor Filter Convolution and Attention Mechanisms
Dec 09, 2025Remotely detecting and classifying underwater acoustic targets is critical for environmental monitoring and defence. However, the complex nature of ship-radiated and environmental underwater noise poses significant challenges to accurate signal processing. While recent advancements in machine learning have improved classification accuracy, issues such as limited dataset availability and a lack of standardised experimentation hinder generalisation and robustness. This paper introduces GSE ResNeXt, a deep learning architecture integrating learnable Gabor convolutional layers with a ResNeXt backbone enhanced by squeeze-and-excitation attention mechanisms. The Gabor filters serve as two-dimensional adaptive band-pass filters, extending the feature channel representation. Its combination with channel attention improves training stability and convergence while enhancing the model's ability to extract discriminative features. The model is evaluated on three classification tasks of increasing complexity. In particular, the impact of temporal differences between the training and testing data is explored, revealing that the distance between the vessel and sensor significantly affects performance. Results show that, GSE ResNeXt consistently outperforms baseline models like Xception, ResNet, and MobileNetV2, in terms of classification performance. Regarding stability and convergence, the addition of Gabor convolutions in the initial layers of the model represents a 28% reduction in training time. These results emphasise the importance of signal processing strategies in improving the reliability and generalisation of models under different environmental conditions, especially in data-limited underwater acoustic classification scenarios. Future developments should focus on mitigating the impact of environmental factors on input signals.
Towards Bio-inspired Heuristically Accelerated Reinforcement Learning for Adaptive Underwater Multi-Agents Behaviour
Feb 10, 2025

This paper describes the problem of coordination of an autonomous Multi-Agent System which aims to solve the coverage planning problem in a complex environment. The considered applications are the detection and identification of objects of interest while covering an area. These tasks, which are highly relevant for space applications, are also of interest among various domains including the underwater context, which is the focus of this study. In this context, coverage planning is traditionally modelled as a Markov Decision Process where a coordinated MAS, a swarm of heterogeneous autonomous underwater vehicles, is required to survey an area and search for objects. This MDP is associated with several challenges: environment uncertainties, communication constraints, and an ensemble of hazards, including time-varying and unpredictable changes in the underwater environment. MARL algorithms can solve highly non-linear problems using deep neural networks and display great scalability against an increased number of agents. Nevertheless, most of the current results in the underwater domain are limited to simulation due to the high learning time of MARL algorithms. For this reason, a novel strategy is introduced to accelerate this convergence rate by incorporating biologically inspired heuristics to guide the policy during training. The PSO method, which is inspired by the behaviour of a group of animals, is selected as a heuristic. It allows the policy to explore the highest quality regions of the action and state spaces, from the beginning of the training, optimizing the exploration/exploitation trade-off. The resulting agent requires fewer interactions to reach optimal performance. The method is applied to the MSAC algorithm and evaluated for a 2D covering area mission in a continuous control environment.
Wake-Informed 3D Path Planning for Autonomous Underwater Vehicles Using A* and Neural Network Approximations
Feb 04, 2025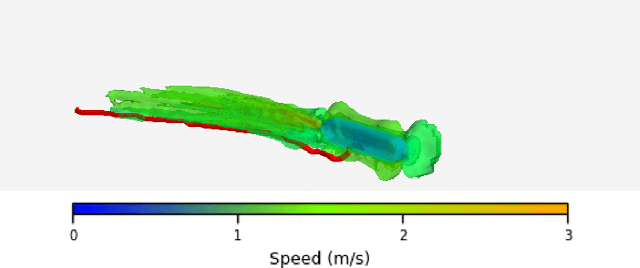
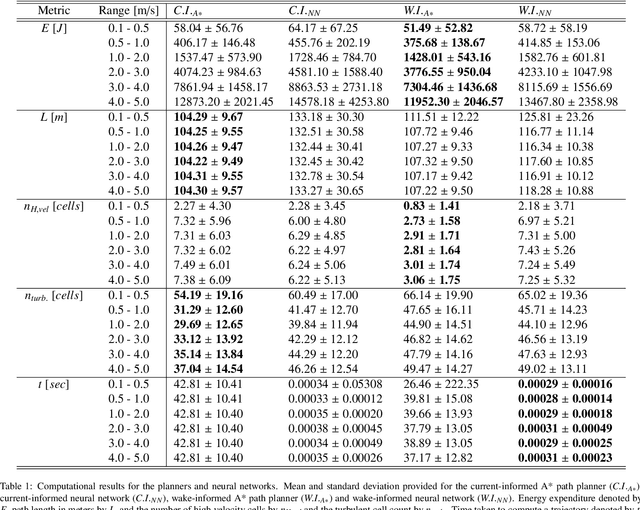
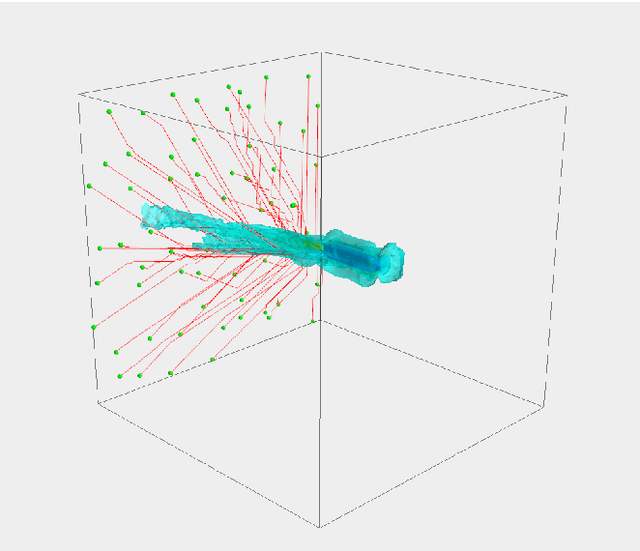
Autonomous Underwater Vehicles (AUVs) encounter significant energy, control and navigation challenges in complex underwater environments, particularly during close-proximity operations, such as launch and recovery (LAR), where fluid interactions and wake effects present additional navigational and energy challenges. Traditional path planning methods fail to incorporate these detailed wake structures, resulting in increased energy consumption, reduced control stability, and heightened safety risks. This paper presents a novel wake-informed, 3D path planning approach that fully integrates localized wake effects and global currents into the planning algorithm. Two variants of the A* algorithm - a current-informed planner and a wake-informed planner - are created to assess its validity and two neural network models are then trained to approximate these planners for real-time applications. Both the A* planners and NN models are evaluated using important metrics such as energy expenditure, path length, and encounters with high-velocity and turbulent regions. The results demonstrate a wake-informed A* planner consistently achieves the lowest energy expenditure and minimizes encounters with high-velocity regions, reducing energy consumption by up to 11.3%. The neural network models are observed to offer computational speedup of 6 orders of magnitude, but exhibit 4.51 - 19.79% higher energy expenditures and 9.81 - 24.38% less optimal paths. These findings underscore the importance of incorporating detailed wake structures into traditional path planning algorithms and the benefits of neural network approximations to enhance energy efficiency and operational safety for AUVs in complex 3D domains.
A generalised novel loss function for computational fluid dynamics
Nov 26, 2024



Computational fluid dynamics (CFD) simulations are crucial in automotive, aerospace, maritime and medical applications, but are limited by the complexity, cost and computational requirements of directly calculating the flow, often taking days of compute time. Machine-learning architectures, such as controlled generative adversarial networks (cGANs) hold significant potential in enhancing or replacing CFD investigations, due to cGANs ability to approximate the underlying data distribution of a dataset. Unlike traditional cGAN applications, where the entire image carries information, CFD data contains small regions of highly variant data, immersed in a large context of low variance that is of minimal importance. This renders most existing deep learning techniques that give equal importance to every portion of the data during training, inefficient. To mitigate this, a novel loss function is proposed called Gradient Mean Squared Error (GMSE) which automatically and dynamically identifies the regions of importance on a field-by-field basis, assigning appropriate weights according to the local variance. To assess the effectiveness of the proposed solution, three identical networks were trained; optimised with Mean Squared Error (MSE) loss, proposed GMSE loss and a dynamic variant of GMSE (DGMSE). The novel loss function resulted in faster loss convergence, correlating to reduced training time, whilst also displaying an 83.6% reduction in structural similarity error between the generated field and ground truth simulations, a 76.6% higher maximum rate of loss and an increased ability to fool a discriminator network. It is hoped that this loss function will enable accelerated machine learning within computational fluid dynamics.
Real-Time Scene Graph Generation
May 25, 2024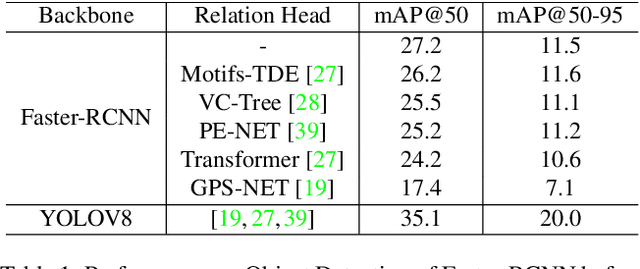



Scene Graph Generation (SGG) can extract abstract semantic relations between entities in images as graph representations. This task holds strong promises for other downstream tasks such as the embodied cognition of an autonomous agent. However, to power such applications, SGG needs to solve the gap of real-time latency. In this work, we propose to investigate the bottlenecks of current approaches for real-time constraint applications. Then, we propose a simple yet effective implementation of a real-time SGG approach using YOLOV8 as an object detection backbone. Our implementation is the first to obtain more than 48 FPS for the task with no loss of accuracy, successfully outperforming any other lightweight approaches. Our code is freely available at https://github.com/Maelic/SGG-Benchmark.
Hybrid Navigation Acceptability and Safety
Apr 18, 2024



Autonomous vessels have emerged as a prominent and accepted solution, particularly in the naval defence sector. However, achieving full autonomy for marine vessels demands the development of robust and reliable control and guidance systems that can handle various encounters with manned and unmanned vessels while operating effectively under diverse weather and sea conditions. A significant challenge in this pursuit is ensuring the autonomous vessels' compliance with the International Regulations for Preventing Collisions at Sea (COLREGs). These regulations present a formidable hurdle for the human-level understanding by autonomous systems as they were originally designed from common navigation practices created since the mid-19th century. Their ambiguous language assumes experienced sailors' interpretation and execution, and therefore demands a high-level (cognitive) understanding of language and agent intentions. These capabilities surpass the current state-of-the-art in intelligent systems. This position paper highlights the critical requirements for a trustworthy control and guidance system, exploring the complexity of adapting COLREGs for safe vessel-on-vessel encounters considering autonomous maritime technology competing and/or cooperating with manned vessels.
Sim-to-Real Transfer of Adaptive Control Parameters for AUV Stabilization under Current Disturbance
Oct 17, 2023Learning-based adaptive control methods hold the premise of enabling autonomous agents to reduce the effect of process variations with minimal human intervention. However, its application to autonomous underwater vehicles (AUVs) has so far been restricted due to 1) unknown dynamics under the form of sea current disturbance that we can not model properly nor measure due to limited sensor capability and 2) the nonlinearity of AUVs tasks where the controller response at some operating points must be overly conservative in order to satisfy the specification at other operating points. Deep Reinforcement Learning (DRL) can alleviates these limitations by training general-purpose neural network policies, but applications of DRL algorithms to AUVs have been restricted to simulated environments, due to their inherent high sample complexity and distribution shift problem. This paper presents a novel approach, merging the Maximum Entropy Deep Reinforcement Learning framework with a classic model-based control architecture, to formulate an adaptive controller. Within this framework, we introduce a Sim-to-Real transfer strategy comprising the following components: a bio-inspired experience replay mechanism, an enhanced domain randomisation technique, and an evaluation protocol executed on a physical platform. Our experimental assessments demonstrate that this method effectively learns proficient policies from suboptimal simulated models of the AUV, resulting in control performance 3 times higher when transferred to a real-world vehicle, compared to its model-based nonadaptive but optimal counterpart.