 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Robots Do Matters More Than What They Look Like: Task Context Shapes Trust in Educational HRI
Jun 12, 2026Socially assistive robots (SARs) are increasingly deployed in educational and information-sharing contexts, supported by advances in large language models that enable fluent real-time interaction. Despite the growing diversity of robot embodiments, it remains unclear whether a single robot appearance is appropriate across different interaction tasks or whether trust depends primarily on contextual factors. In this study, we examine how robot appearance and task type jointly influence trust in robots. Using a within-subjects video-based experiment (N = 81), participants evaluated three robots with distinct appearances while performing three educationally relevant tasks: teaching, procedural instruction, and personal-information discussion. Results from repeated-measures analyses show a strong main effect of task on trust, with participants reporting the highest trust during instructional guidance, moderate trust during teaching activities, and significantly lower trust when robots requested personal information. In contrast, robot appearance showed no significant main effect, and the interaction between appearance and task was marginal. These findings suggest that trust in human-robot interaction is shaped more strongly by task context than by physical embodiment alone. By focusing on future educators as end users, this work contributes empirical evidence toward task-aware robot deployment in educational environments and highlights the importance of aligning robot roles and behaviors with interaction goals rather than relying solely on anthropomorphic design.
Humor Style Drives Laughter, Topic Shapes Acceptability: Evaluating Bilingual Personal and Political Robot-Delivered AI Jokes
Jun 11, 2026Humor plays a central role in human social relationships, and recent advances in computational humor create new opportunities for integrating humor into human-robot interaction (HRI). While large language models (LLMs) can generate diverse forms of humor, it remains unclear how humor style, joke content, and language preference shape perceptions of robot-delivered humor in group settings. In this exploratory study, we employed a mixed factorial design in which participants evaluated AI-generated jokes delivered by a robot in a university classroom. We examined the effects of humor type (Affiliative, Self-Enhancing, Aggressive, Self-Defeating) and joke content (person-related vs. political) on perceived funniness and appropriateness, as well as preferred language. Results show that humor type significantly influences funniness, with Aggressive and Affiliative humor rated higher, while joke content primarily affects appropriateness, with person-related jokes preferred over political ones. Language preference was shaped by both joke content and participants' self-reported fluency and humor practices.
GraSP-VLA: Graph-based Symbolic Action Representation for Long-Horizon Planning with VLA Policies
Nov 06, 2025Deploying autonomous robots that can learn new skills from demonstrations is an important challenge of modern robotics. Existing solutions often apply end-to-end imitation learning with Vision-Language Action (VLA) models or symbolic approaches with Action Model Learning (AML). On the one hand, current VLA models are limited by the lack of high-level symbolic planning, which hinders their abilities in long-horizon tasks. On the other hand, symbolic approaches in AML lack generalization and scalability perspectives. In this paper we present a new neuro-symbolic approach, GraSP-VLA, a framework that uses a Continuous Scene Graph representation to generate a symbolic representation of human demonstrations. This representation is used to generate new planning domains during inference and serves as an orchestrator for low-level VLA policies, scaling up the number of actions that can be reproduced in a row. Our results show that GraSP-VLA is effective for modeling symbolic representations on the task of automatic planning domain generation from observations. In addition, results on real-world experiments show the potential of our Continuous Scene Graph representation to orchestrate low-level VLA policies in long-horizon tasks.
What killed the cat? Towards a logical formalization of curiosity (and suspense, and surprise) in narratives
Oct 11, 2024

We provide a unified framework in which the three emotions at the heart of narrative tension (curiosity, suspense and surprise) are formalized. This framework is built on nonmonotonic reasoning which allows us to compactly represent the default behavior of the world and to simulate the affective evolution of an agent receiving a story. After formalizing the notions of awareness, curiosity, surprise and suspense, we explore the properties induced by our definitions and study the computational complexity of detecting them. We finally propose means to evaluate these emotions' intensity for a given agent listening to a story.
Real-Time Scene Graph Generation
May 25, 2024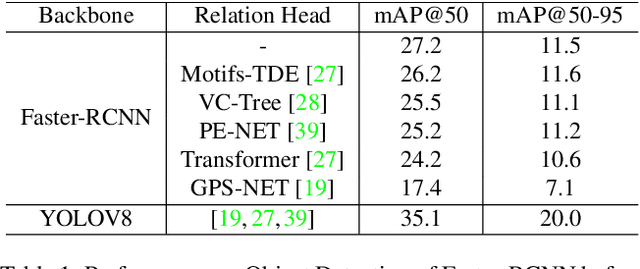



Scene Graph Generation (SGG) can extract abstract semantic relations between entities in images as graph representations. This task holds strong promises for other downstream tasks such as the embodied cognition of an autonomous agent. However, to power such applications, SGG needs to solve the gap of real-time latency. In this work, we propose to investigate the bottlenecks of current approaches for real-time constraint applications. Then, we propose a simple yet effective implementation of a real-time SGG approach using YOLOV8 as an object detection backbone. Our implementation is the first to obtain more than 48 FPS for the task with no loss of accuracy, successfully outperforming any other lightweight approaches. Our code is freely available at https://github.com/Maelic/SGG-Benchmark.
Fine-Grained is Too Coarse: A Novel Data-Centric Approach for Efficient Scene Graph Generation
May 30, 2023



Learning to compose visual relationships from raw images in the form of scene graphs is a highly challenging task due to contextual dependencies, but it is essential in computer vision applications that depend on scene understanding. However, no current approaches in Scene Graph Generation (SGG) aim at providing useful graphs for downstream tasks. Instead, the main focus has primarily been on the task of unbiasing the data distribution for predicting more fine-grained relations. That being said, all fine-grained relations are not equally relevant and at least a part of them are of no use for real-world applications. In this work, we introduce the task of Efficient SGG that prioritizes the generation of relevant relations, facilitating the use of Scene Graphs in downstream tasks such as Image Generation. To support further approaches in this task, we present a new dataset, VG150-curated, based on the annotations of the popular Visual Genome dataset. We show through a set of experiments that this dataset contains more high-quality and diverse annotations than the one usually adopted by approaches in SGG. Finally, we show the efficiency of this dataset in the task of Image Generation from Scene Graphs. Our approach can be easily replicated to improve the quality of other Scene Graph Generation datasets.
Commonsense Reasoning for Identifying and Understanding the Implicit Need of Help and Synthesizing Assistive Actions
Feb 23, 2022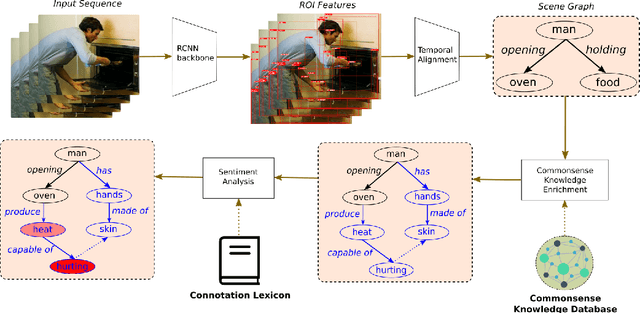
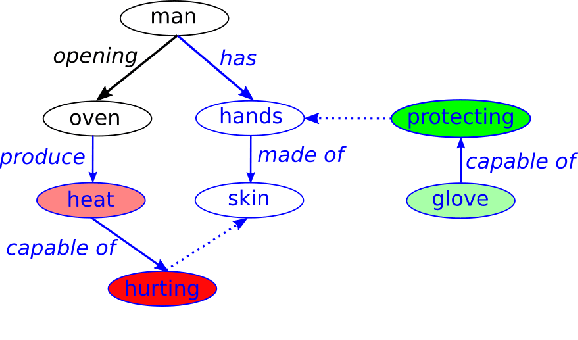
Human-Robot Interaction (HRI) is an emerging subfield of service robotics. While most existing approaches rely on explicit signals (i.e. voice, gesture) to engage, current literature is lacking solutions to address implicit user needs. In this paper, we present an architecture to (a) detect user implicit need of help and (b) generate a set of assistive actions without prior learning. Task (a) will be performed using state-of-the-art solutions for Scene Graph Generation coupled to the use of commonsense knowledge; whereas, task (b) will be performed using additional commonsense knowledge as well as a sentiment analysis on graph structure. Finally, we propose an evaluation of our solution using established benchmarks (e.g. ActionGenome dataset) along with human experiments. The main motivation of our approach is the embedding of the perception-decision-action loop in a single architecture.