 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWAKESET: A Large-Scale, High-Reynolds Number Flow Dataset for Machine Learning of Turbulent Wake Dynamics
Feb 01, 2026Machine learning (ML) offers transformative potential for computational fluid dynamics (CFD), promising to accelerate simulations, improve turbulence modelling, and enable real-time flow prediction and control-capabilities that could fundamentally change how engineers approach fluid dynamics problems. However, the exploration of ML in fluid dynamics is critically hampered by the scarcity of large, diverse, and high-fidelity datasets suitable for training robust models. This limitation is particularly acute for highly turbulent flows, which dominate practical engineering applications yet remain computationally prohibitive to simulate at scale. High-Reynolds number turbulent datasets are essential for ML models to learn the complex, multi-scale physics characteristic of real-world flows, enabling generalisation beyond the simplified, low-Reynolds number regimes often represented in existing datasets. This paper introduces WAKESET, a novel, large-scale CFD dataset of highly turbulent flows, designed to address this critical gap. The dataset captures the complex hydrodynamic interactions during the underwater recovery of an autonomous underwater vehicle by a larger extra-large uncrewed underwater vehicle. It comprises 1,091 high-fidelity Reynolds-Averaged Navier-Stokes simulations, augmented to 4,364 instances, covering a wide operational envelope of speeds (up to Reynolds numbers of 1.09 x 10^8) and turning angles. This work details the motivation for this new dataset by reviewing existing resources, outlines the hydrodynamic modelling and validation underpinning its creation, and describes its structure. The dataset's focus on a practical engineering problem, its scale, and its high turbulence characteristics make it a valuable resource for developing and benchmarking ML models for flow field prediction, surrogate modelling, and autonomous navigation in complex underwater environments.
GraSP-VLA: Graph-based Symbolic Action Representation for Long-Horizon Planning with VLA Policies
Nov 06, 2025Deploying autonomous robots that can learn new skills from demonstrations is an important challenge of modern robotics. Existing solutions often apply end-to-end imitation learning with Vision-Language Action (VLA) models or symbolic approaches with Action Model Learning (AML). On the one hand, current VLA models are limited by the lack of high-level symbolic planning, which hinders their abilities in long-horizon tasks. On the other hand, symbolic approaches in AML lack generalization and scalability perspectives. In this paper we present a new neuro-symbolic approach, GraSP-VLA, a framework that uses a Continuous Scene Graph representation to generate a symbolic representation of human demonstrations. This representation is used to generate new planning domains during inference and serves as an orchestrator for low-level VLA policies, scaling up the number of actions that can be reproduced in a row. Our results show that GraSP-VLA is effective for modeling symbolic representations on the task of automatic planning domain generation from observations. In addition, results on real-world experiments show the potential of our Continuous Scene Graph representation to orchestrate low-level VLA policies in long-horizon tasks.
AquaSignal: An Integrated Framework for Robust Underwater Acoustic Analysis
May 20, 2025This paper presents AquaSignal, a modular and scalable pipeline for preprocessing, denoising, classification, and novelty detection of underwater acoustic signals. Designed to operate effectively in noisy and dynamic marine environments, AquaSignal integrates state-of-the-art deep learning architectures to enhance the reliability and accuracy of acoustic signal analysis. The system is evaluated on a combined dataset from the Deepship and Ocean Networks Canada (ONC) benchmarks, providing a diverse set of real-world underwater scenarios. AquaSignal employs a U-Net architecture for denoising, a ResNet18 convolutional neural network for classifying known acoustic events, and an AutoEncoder-based model for unsupervised detection of novel or anomalous signals. To our knowledge, this is the first comprehensive study to apply and evaluate this combination of techniques on maritime vessel acoustic data. Experimental results show that AquaSignal improves signal clarity and task performance, achieving 71% classification accuracy and 91% accuracy in novelty detection. Despite slightly lower classification performance compared to some state-of-the-art models, differences in data partitioning strategies limit direct comparisons. Overall, AquaSignal demonstrates strong potential for real-time underwater acoustic monitoring in scientific, environmental, and maritime domains.
A generalised novel loss function for computational fluid dynamics
Nov 26, 2024



Computational fluid dynamics (CFD) simulations are crucial in automotive, aerospace, maritime and medical applications, but are limited by the complexity, cost and computational requirements of directly calculating the flow, often taking days of compute time. Machine-learning architectures, such as controlled generative adversarial networks (cGANs) hold significant potential in enhancing or replacing CFD investigations, due to cGANs ability to approximate the underlying data distribution of a dataset. Unlike traditional cGAN applications, where the entire image carries information, CFD data contains small regions of highly variant data, immersed in a large context of low variance that is of minimal importance. This renders most existing deep learning techniques that give equal importance to every portion of the data during training, inefficient. To mitigate this, a novel loss function is proposed called Gradient Mean Squared Error (GMSE) which automatically and dynamically identifies the regions of importance on a field-by-field basis, assigning appropriate weights according to the local variance. To assess the effectiveness of the proposed solution, three identical networks were trained; optimised with Mean Squared Error (MSE) loss, proposed GMSE loss and a dynamic variant of GMSE (DGMSE). The novel loss function resulted in faster loss convergence, correlating to reduced training time, whilst also displaying an 83.6% reduction in structural similarity error between the generated field and ground truth simulations, a 76.6% higher maximum rate of loss and an increased ability to fool a discriminator network. It is hoped that this loss function will enable accelerated machine learning within computational fluid dynamics.
Real-Time Scene Graph Generation
May 25, 2024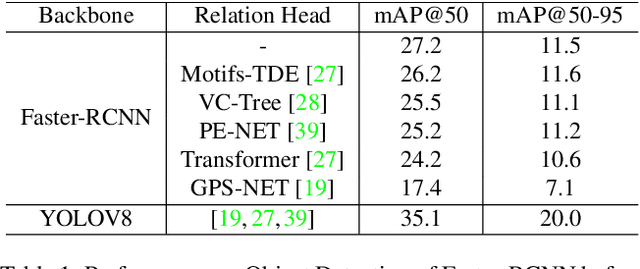



Scene Graph Generation (SGG) can extract abstract semantic relations between entities in images as graph representations. This task holds strong promises for other downstream tasks such as the embodied cognition of an autonomous agent. However, to power such applications, SGG needs to solve the gap of real-time latency. In this work, we propose to investigate the bottlenecks of current approaches for real-time constraint applications. Then, we propose a simple yet effective implementation of a real-time SGG approach using YOLOV8 as an object detection backbone. Our implementation is the first to obtain more than 48 FPS for the task with no loss of accuracy, successfully outperforming any other lightweight approaches. Our code is freely available at https://github.com/Maelic/SGG-Benchmark.
Hybrid Navigation Acceptability and Safety
Apr 18, 2024



Autonomous vessels have emerged as a prominent and accepted solution, particularly in the naval defence sector. However, achieving full autonomy for marine vessels demands the development of robust and reliable control and guidance systems that can handle various encounters with manned and unmanned vessels while operating effectively under diverse weather and sea conditions. A significant challenge in this pursuit is ensuring the autonomous vessels' compliance with the International Regulations for Preventing Collisions at Sea (COLREGs). These regulations present a formidable hurdle for the human-level understanding by autonomous systems as they were originally designed from common navigation practices created since the mid-19th century. Their ambiguous language assumes experienced sailors' interpretation and execution, and therefore demands a high-level (cognitive) understanding of language and agent intentions. These capabilities surpass the current state-of-the-art in intelligent systems. This position paper highlights the critical requirements for a trustworthy control and guidance system, exploring the complexity of adapting COLREGs for safe vessel-on-vessel encounters considering autonomous maritime technology competing and/or cooperating with manned vessels.
Multimodal Speech Emotion Recognition Using Modality-specific Self-Supervised Frameworks
Dec 04, 2023Emotion recognition is a topic of significant interest in assistive robotics due to the need to equip robots with the ability to comprehend human behavior, facilitating their effective interaction in our society. Consequently, efficient and dependable emotion recognition systems supporting optimal human-machine communication are required. Multi-modality (including speech, audio, text, images, and videos) is typically exploited in emotion recognition tasks. Much relevant research is based on merging multiple data modalities and training deep learning models utilizing low-level data representations. However, most existing emotion databases are not large (or complex) enough to allow machine learning approaches to learn detailed representations. This paper explores modalityspecific pre-trained transformer frameworks for self-supervised learning of speech and text representations for data-efficient emotion recognition while achieving state-of-the-art performance in recognizing emotions. This model applies feature-level fusion using nonverbal cue data points from motion capture to provide multimodal speech emotion recognition. The model was trained using the publicly available IEMOCAP dataset, achieving an overall accuracy of 77.58% for four emotions, outperforming state-of-the-art approaches
Guided Navigation from Multiple Viewpoints using Qualitative Spatial Reasoning
Nov 03, 2020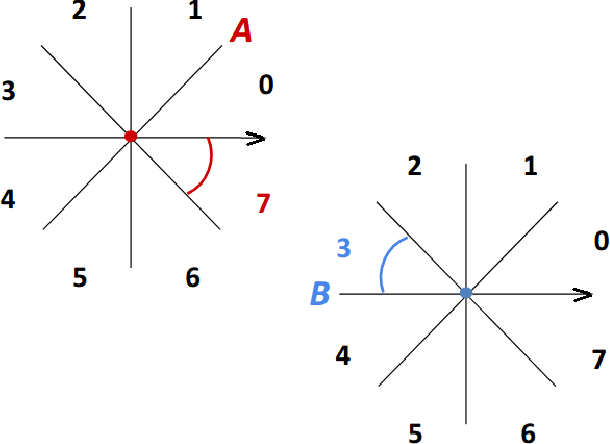
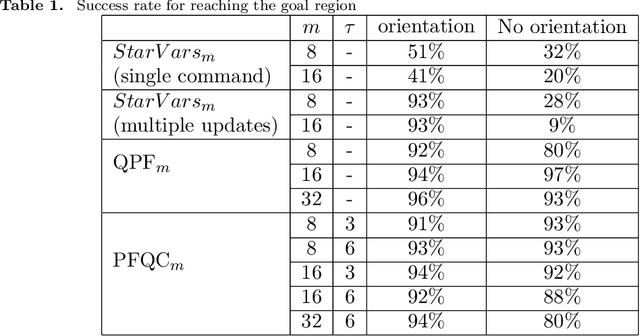

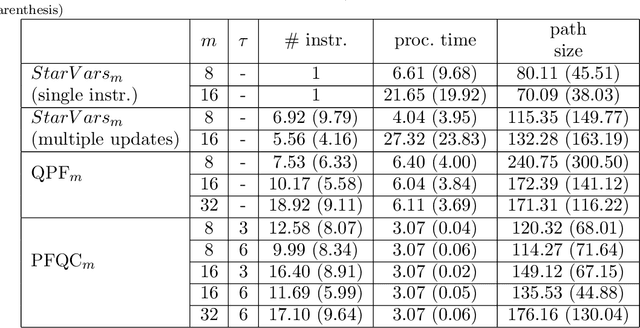
Navigation is an essential ability for mobile agents to be completely autonomous and able to perform complex actions. However, the problem of navigation for agents with limited (or no) perception of the world, or devoid of a fully defined motion model, has received little attention from research in AI and Robotics. One way to tackle this problem is to use guided navigation, in which other autonomous agents, endowed with perception, can combine their distinct viewpoints to infer the localisation and the appropriate commands to guide a sensory deprived agent through a particular path. Due to the limited knowledge about the physical and perceptual characteristics of the guided agent, this task should be conducted on a level of abstraction allowing the use of a generic motion model, and high-level commands, that can be applied by any type of autonomous agents, including humans. The main task considered in this work is, given a group of autonomous agents perceiving their common environment with their independent, egocentric and local vision sensors, the development and evaluation of algorithms capable of producing a set of high-level commands (involving qualitative directions: e.g. move left, go straight ahead) capable of guiding a sensory deprived robot to a goal location.
Heuristics, Answer Set Programming and Markov Decision Process for Solving a Set of Spatial Puzzles
Feb 16, 2019
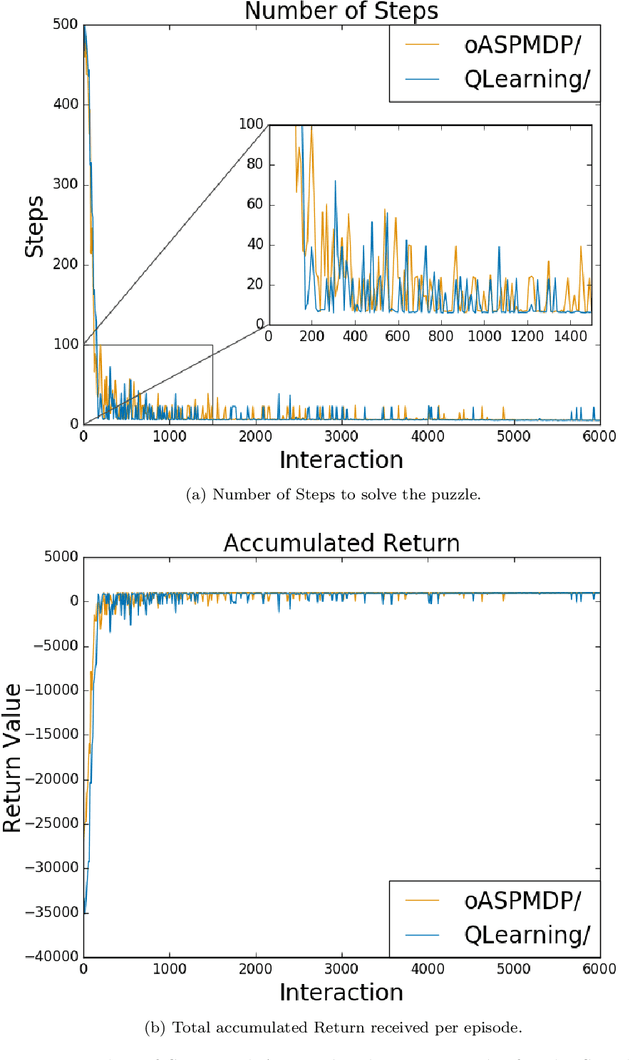
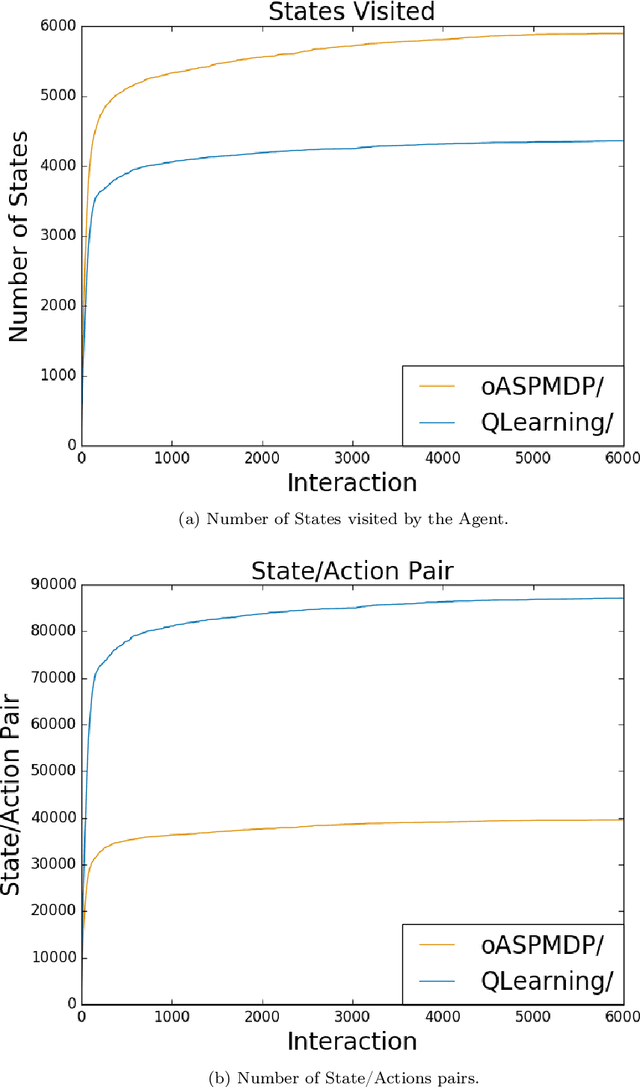
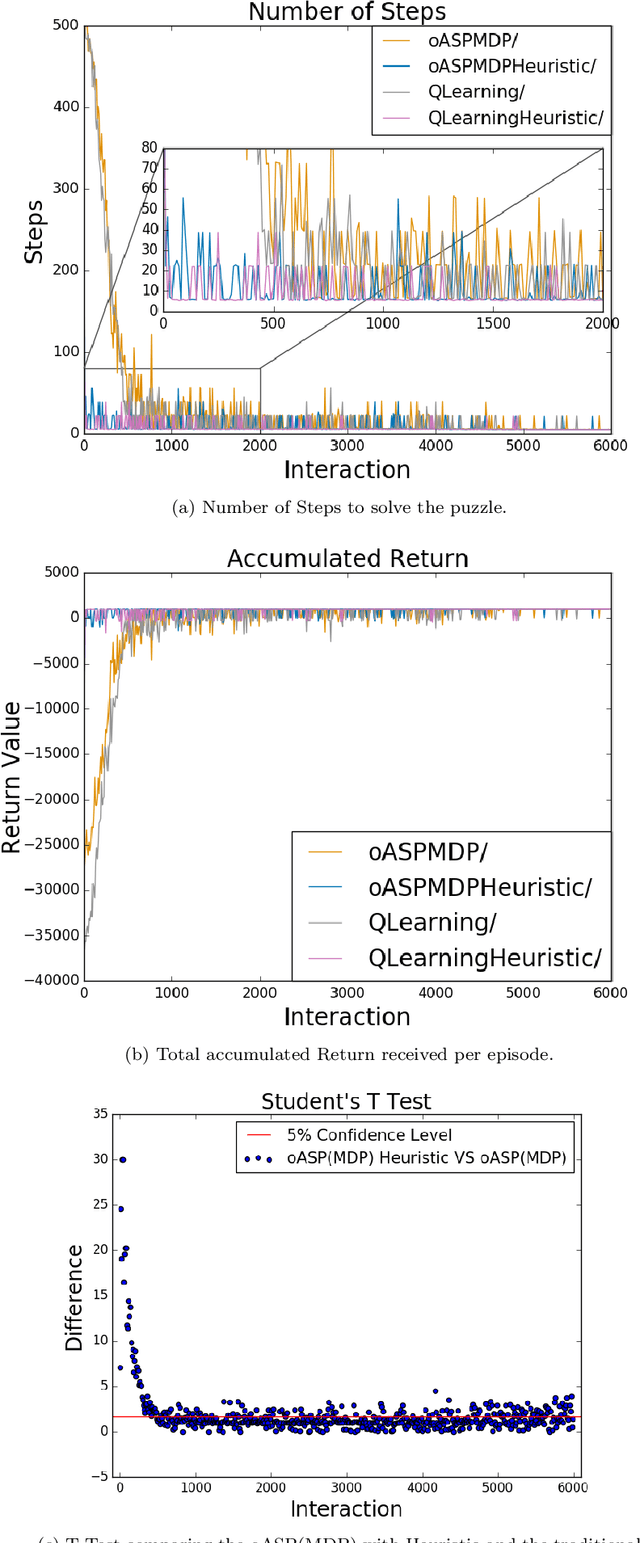
Spatial puzzles composed of rigid objects, flexible strings and holes offer interesting domains for reasoning about spatial entities that are common in the human daily-life's activities. The goal of this work is to investigate the automated solution of this kind of puzzles adapting an algorithm that combines Answer Set Programming (ASP) with Markov Decision Process (MDP), algorithm oASP(MDP), to use heuristics accelerating the learning process. ASP is applied to represent the domain as an MDP, while a Reinforcement Learning algorithm (Q-Learning) is used to find the optimal policies. In this work, the heuristics were obtained from the solution of relaxed versions of the puzzles. Experiments were performed on deterministic, non-deterministic and non-stationary versions of the puzzles. Results show that the proposed approach can accelerate the learning process, presenting an advantage when compared to the non-heuristic versions of oASP(MDP) and Q-Learning.
A method for the online construction of the set of states of a Markov Decision Process using Answer Set Programming
Jun 05, 2017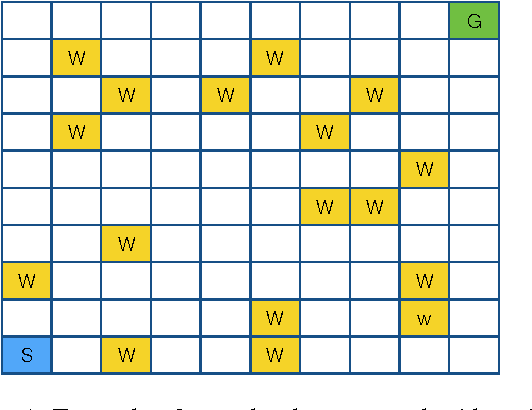
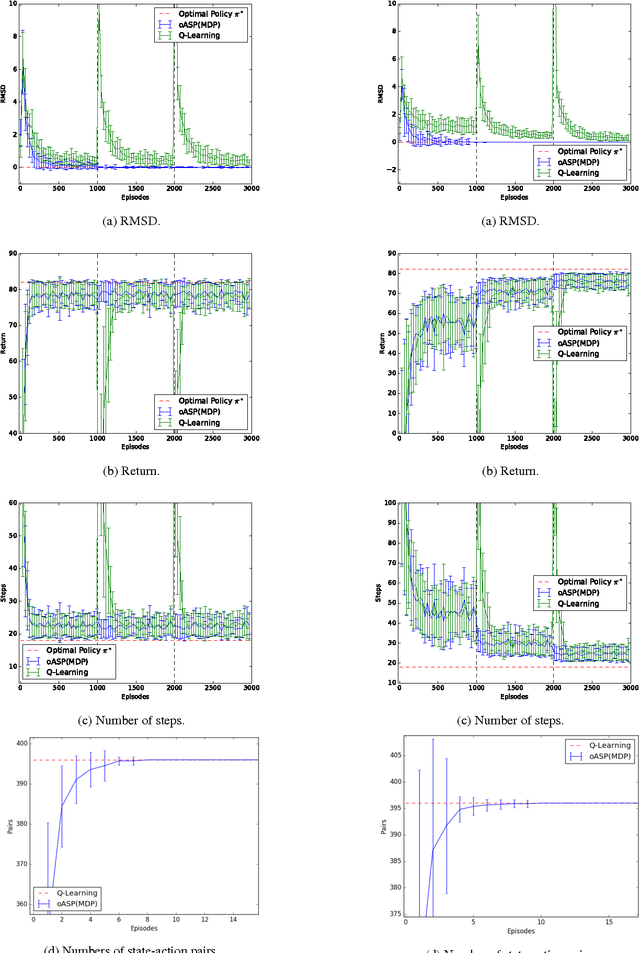
Non-stationary domains, that change in unpredicted ways, are a challenge for agents searching for optimal policies in sequential decision-making problems. This paper presents a combination of Markov Decision Processes (MDP) with Answer Set Programming (ASP), named {\em Online ASP for MDP} (oASP(MDP)), which is a method capable of constructing the set of domain states while the agent interacts with a changing environment. oASP(MDP) updates previously obtained policies, learnt by means of Reinforcement Learning (RL), using rules that represent the domain changes observed by the agent. These rules represent a set of domain constraints that are processed as ASP programs reducing the search space. Results show that oASP(MDP) is capable of finding solutions for problems in non-stationary domains without interfering with the action-value function approximation process.