 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLangMap: A Hierarchical Benchmark for Open-Vocabulary Goal Navigation
Feb 02, 2026The relationships between objects and language are fundamental to meaningful communication between humans and AI, and to practically useful embodied intelligence. We introduce HieraNav, a multi-granularity, open-vocabulary goal navigation task where agents interpret natural language instructions to reach targets at four semantic levels: scene, room, region, and instance. To this end, we present Language as a Map (LangMap), a large-scale benchmark built on real-world 3D indoor scans with comprehensive human-verified annotations and tasks spanning these levels. LangMap provides region labels, discriminative region descriptions, discriminative instance descriptions covering 414 object categories, and over 18K navigation tasks. Each target features both concise and detailed descriptions, enabling evaluation across different instruction styles. LangMap achieves superior annotation quality, outperforming GOAT-Bench by 23.8% in discriminative accuracy using four times fewer words. Comprehensive evaluations of zero-shot and supervised models on LangMap reveal that richer context and memory improve success, while long-tailed, small, context-dependent, and distant goals, as well as multi-goal completion, remain challenging. HieraNav and LangMap establish a rigorous testbed for advancing language-driven embodied navigation. Project: https://bo-miao.github.io/LangMap
Vision Foundation Models for Domain Generalisable Cross-View Localisation in Planetary Ground-Aerial Robotic Teams
Jan 14, 2026Accurate localisation in planetary robotics enables the advanced autonomy required to support the increased scale and scope of future missions. The successes of the Ingenuity helicopter and multiple planetary orbiters lay the groundwork for future missions that use ground-aerial robotic teams. In this paper, we consider rovers using machine learning to localise themselves in a local aerial map using limited field-of-view monocular ground-view RGB images as input. A key consideration for machine learning methods is that real space data with ground-truth position labels suitable for training is scarce. In this work, we propose a novel method of localising rovers in an aerial map using cross-view-localising dual-encoder deep neural networks. We leverage semantic segmentation with vision foundation models and high volume synthetic data to bridge the domain gap to real images. We also contribute a new cross-view dataset of real-world rover trajectories with corresponding ground-truth localisation data captured in a planetary analogue facility, plus a high volume dataset of analogous synthetic image pairs. Using particle filters for state estimation with the cross-view networks allows accurate position estimation over simple and complex trajectories based on sequences of ground-view images.
AIMC-Spec: A Benchmark Dataset for Automatic Intrapulse Modulation Classification under Variable Noise Conditions
Jan 13, 2026A lack of standardized datasets has long hindered progress in automatic intrapulse modulation classification (AIMC) - a critical task in radar signal analysis for electronic support systems, particularly under noisy or degraded conditions. AIMC seeks to identify the modulation type embedded within a single radar pulse from its complex in-phase and quadrature (I/Q) representation, enabling automated interpretation of intrapulse structure. This paper introduces AIMC-Spec, a comprehensive synthetic dataset for spectrogram-based image classification, encompassing 33 modulation types across 13 signal-to-noise ratio (SNR) levels. To benchmark AIMC-Spec, five representative deep learning algorithms - ranging from lightweight CNNs and denoising architectures to transformer-based networks - were re-implemented and evaluated under a unified input format. The results reveal significant performance variation, with frequency-modulated (FM) signals classified more reliably than phase or hybrid types, particularly at low SNRs. A focused FM-only test further highlights how modulation type and network architecture influence classifier robustness. AIMC-Spec establishes a reproducible baseline and provides a foundation for future research and standardization in the AIMC domain.
SceneEdited: A City-Scale Benchmark for 3D HD Map Updating via Image-Guided Change Detection
Nov 19, 2025



Accurate, up-to-date High-Definition (HD) maps are critical for urban planning, infrastructure monitoring, and autonomous navigation. However, these maps quickly become outdated as environments evolve, creating a need for robust methods that not only detect changes but also incorporate them into updated 3D representations. While change detection techniques have advanced significantly, there remains a clear gap between detecting changes and actually updating 3D maps, particularly when relying on 2D image-based change detection. To address this gap, we introduce SceneEdited, the first city-scale dataset explicitly designed to support research on HD map maintenance through 3D point cloud updating. SceneEdited contains over 800 up-to-date scenes covering 73 km of driving and approximate 3 $\text{km}^2$ of urban area, with more than 23,000 synthesized object changes created both manually and automatically across 2000+ out-of-date versions, simulating realistic urban modifications such as missing roadside infrastructure, buildings, overpasses, and utility poles. Each scene includes calibrated RGB images, LiDAR scans, and detailed change masks for training and evaluation. We also provide baseline methods using a foundational image-based structure-from-motion pipeline for updating outdated scenes, as well as a comprehensive toolkit supporting scalability, trackability, and portability for future dataset expansion and unification of out-of-date object annotations. Both the dataset and the toolkit are publicly available at https://github.com/ChadLin9596/ScenePoint-ETK, establising a standardized benchmark for 3D map updating research.
ObjectReact: Learning Object-Relative Control for Visual Navigation
Sep 11, 2025Visual navigation using only a single camera and a topological map has recently become an appealing alternative to methods that require additional sensors and 3D maps. This is typically achieved through an "image-relative" approach to estimating control from a given pair of current observation and subgoal image. However, image-level representations of the world have limitations because images are strictly tied to the agent's pose and embodiment. In contrast, objects, being a property of the map, offer an embodiment- and trajectory-invariant world representation. In this work, we present a new paradigm of learning "object-relative" control that exhibits several desirable characteristics: a) new routes can be traversed without strictly requiring to imitate prior experience, b) the control prediction problem can be decoupled from solving the image matching problem, and c) high invariance can be achieved in cross-embodiment deployment for variations across both training-testing and mapping-execution settings. We propose a topometric map representation in the form of a "relative" 3D scene graph, which is used to obtain more informative object-level global path planning costs. We train a local controller, dubbed "ObjectReact", conditioned directly on a high-level "WayObject Costmap" representation that eliminates the need for an explicit RGB input. We demonstrate the advantages of learning object-relative control over its image-relative counterpart across sensor height variations and multiple navigation tasks that challenge the underlying spatial understanding capability, e.g., navigating a map trajectory in the reverse direction. We further show that our sim-only policy is able to generalize well to real-world indoor environments. Code and supplementary material are accessible via project page: https://object-react.github.io/
TANGO: Traversability-Aware Navigation with Local Metric Control for Topological Goals
Sep 10, 2025Visual navigation in robotics traditionally relies on globally-consistent 3D maps or learned controllers, which can be computationally expensive and difficult to generalize across diverse environments. In this work, we present a novel RGB-only, object-level topometric navigation pipeline that enables zero-shot, long-horizon robot navigation without requiring 3D maps or pre-trained controllers. Our approach integrates global topological path planning with local metric trajectory control, allowing the robot to navigate towards object-level sub-goals while avoiding obstacles. We address key limitations of previous methods by continuously predicting local trajectory using monocular depth and traversability estimation, and incorporating an auto-switching mechanism that falls back to a baseline controller when necessary. The system operates using foundational models, ensuring open-set applicability without the need for domain-specific fine-tuning. We demonstrate the effectiveness of our method in both simulated environments and real-world tests, highlighting its robustness and deployability. Our approach outperforms existing state-of-the-art methods, offering a more adaptable and effective solution for visual navigation in open-set environments. The source code is made publicly available: https://github.com/podgorki/TANGO.
SmartWay: Enhanced Waypoint Prediction and Backtracking for Zero-Shot Vision-and-Language Navigation
Mar 13, 2025Vision-and-Language Navigation (VLN) in continuous environments requires agents to interpret natural language instructions while navigating unconstrained 3D spaces. Existing VLN-CE frameworks rely on a two-stage approach: a waypoint predictor to generate waypoints and a navigator to execute movements. However, current waypoint predictors struggle with spatial awareness, while navigators lack historical reasoning and backtracking capabilities, limiting adaptability. We propose a zero-shot VLN-CE framework integrating an enhanced waypoint predictor with a Multi-modal Large Language Model (MLLM)-based navigator. Our predictor employs a stronger vision encoder, masked cross-attention fusion, and an occupancy-aware loss for better waypoint quality. The navigator incorporates history-aware reasoning and adaptive path planning with backtracking, improving robustness. Experiments on R2R-CE and MP3D benchmarks show our method achieves state-of-the-art (SOTA) performance in zero-shot settings, demonstrating competitive results compared to fully supervised methods. Real-world validation on Turtlebot 4 further highlights its adaptability.
QueryAdapter: Rapid Adaptation of Vision-Language Models in Response to Natural Language Queries
Feb 26, 2025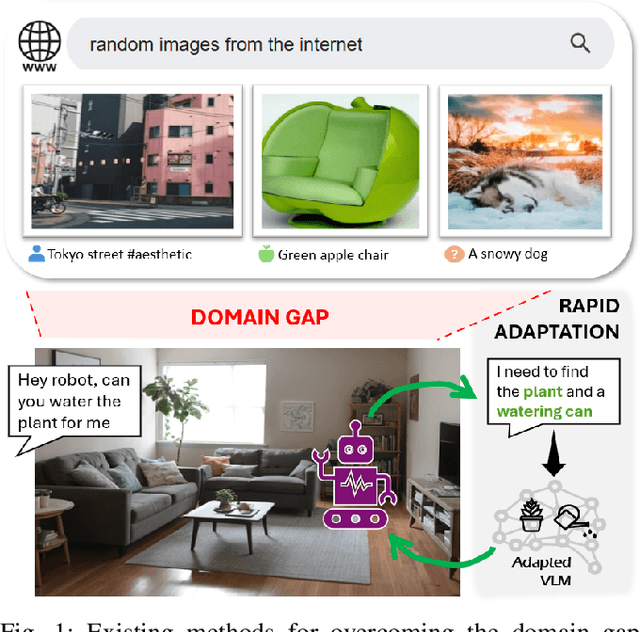


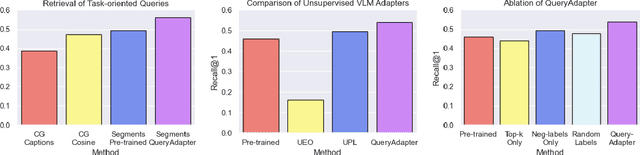
A domain shift exists between the large-scale, internet data used to train a Vision-Language Model (VLM) and the raw image streams collected by a robot. Existing adaptation strategies require the definition of a closed-set of classes, which is impractical for a robot that must respond to diverse natural language queries. In response, we present QueryAdapter; a novel framework for rapidly adapting a pre-trained VLM in response to a natural language query. QueryAdapter leverages unlabelled data collected during previous deployments to align VLM features with semantic classes related to the query. By optimising learnable prompt tokens and actively selecting objects for training, an adapted model can be produced in a matter of minutes. We also explore how objects unrelated to the query should be dealt with when using real-world data for adaptation. In turn, we propose the use of object captions as negative class labels, helping to produce better calibrated confidence scores during adaptation. Extensive experiments on ScanNet++ demonstrate that QueryAdapter significantly enhances object retrieval performance compared to state-of-the-art unsupervised VLM adapters and 3D scene graph methods. Furthermore, the approach exhibits robust generalization to abstract affordance queries and other datasets, such as Ego4D.
3D-LLaVA: Towards Generalist 3D LMMs with Omni Superpoint Transformer
Jan 02, 2025



Current 3D Large Multimodal Models (3D LMMs) have shown tremendous potential in 3D-vision-based dialogue and reasoning. However, how to further enhance 3D LMMs to achieve fine-grained scene understanding and facilitate flexible human-agent interaction remains a challenging problem. In this work, we introduce 3D-LLaVA, a simple yet highly powerful 3D LMM designed to act as an intelligent assistant in comprehending, reasoning, and interacting with the 3D world. Unlike existing top-performing methods that rely on complicated pipelines-such as offline multi-view feature extraction or additional task-specific heads-3D-LLaVA adopts a minimalist design with integrated architecture and only takes point clouds as input. At the core of 3D-LLaVA is a new Omni Superpoint Transformer (OST), which integrates three functionalities: (1) a visual feature selector that converts and selects visual tokens, (2) a visual prompt encoder that embeds interactive visual prompts into the visual token space, and (3) a referring mask decoder that produces 3D masks based on text description. This versatile OST is empowered by the hybrid pretraining to obtain perception priors and leveraged as the visual connector that bridges the 3D data to the LLM. After performing unified instruction tuning, our 3D-LLaVA reports impressive results on various benchmarks. The code and model will be released to promote future exploration.
Effective Tuning Strategies for Generalist Robot Manipulation Policies
Oct 02, 2024Generalist robot manipulation policies (GMPs) have the potential to generalize across a wide range of tasks, devices, and environments. However, existing policies continue to struggle with out-of-distribution scenarios due to the inherent difficulty of collecting sufficient action data to cover extensively diverse domains. While fine-tuning offers a practical way to quickly adapt a GMPs to novel domains and tasks with limited samples, we observe that the performance of the resulting GMPs differs significantly with respect to the design choices of fine-tuning strategies. In this work, we first conduct an in-depth empirical study to investigate the effect of key factors in GMPs fine-tuning strategies, covering the action space, policy head, supervision signal and the choice of tunable parameters, where 2,500 rollouts are evaluated for a single configuration. We systematically discuss and summarize our findings and identify the key design choices, which we believe give a practical guideline for GMPs fine-tuning. We observe that in a low-data regime, with carefully chosen fine-tuning strategies, a GMPs significantly outperforms the state-of-the-art imitation learning algorithms. The results presented in this work establish a new baseline for future studies on fine-tuned GMPs, and provide a significant addition to the GMPs toolbox for the community.