 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Knowledge-driven Adaptive Collaboration of LLMs for Enhancing Medical Decision-making
Sep 18, 2025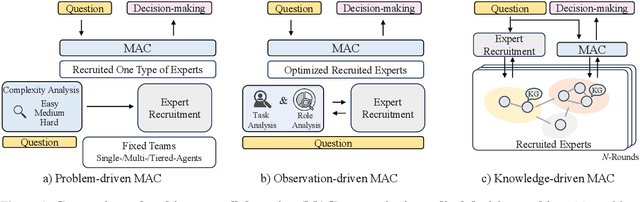
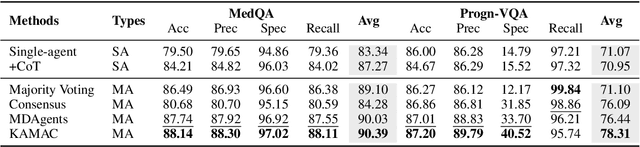
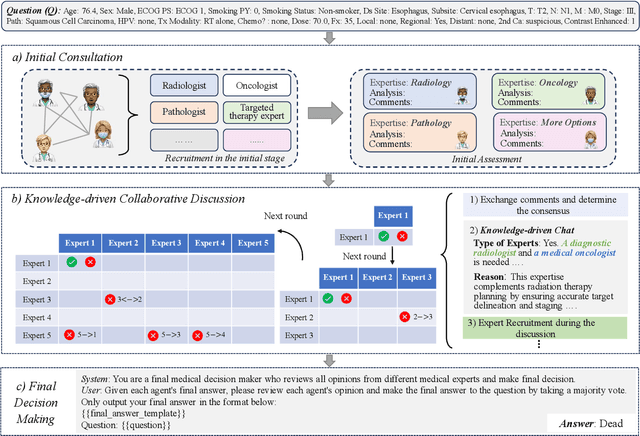
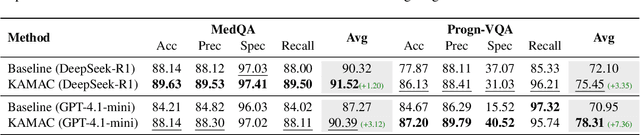
Medical decision-making often involves integrating knowledge from multiple clinical specialties, typically achieved through multidisciplinary teams. Inspired by this collaborative process, recent work has leveraged large language models (LLMs) in multi-agent collaboration frameworks to emulate expert teamwork. While these approaches improve reasoning through agent interaction, they are limited by static, pre-assigned roles, which hinder adaptability and dynamic knowledge integration. To address these limitations, we propose KAMAC, a Knowledge-driven Adaptive Multi-Agent Collaboration framework that enables LLM agents to dynamically form and expand expert teams based on the evolving diagnostic context. KAMAC begins with one or more expert agents and then conducts a knowledge-driven discussion to identify and fill knowledge gaps by recruiting additional specialists as needed. This supports flexible, scalable collaboration in complex clinical scenarios, with decisions finalized through reviewing updated agent comments. Experiments on two real-world medical benchmarks demonstrate that KAMAC significantly outperforms both single-agent and advanced multi-agent methods, particularly in complex clinical scenarios (i.e., cancer prognosis) requiring dynamic, cross-specialty expertise. Our code is publicly available at: https://github.com/XiaoXiao-Woo/KAMAC.
Chain-of-Action: Trajectory Autoregressive Modeling for Robotic Manipulation
Jun 11, 2025We present Chain-of-Action (CoA), a novel visuo-motor policy paradigm built upon Trajectory Autoregressive Modeling. Unlike conventional approaches that predict next step action(s) forward, CoA generates an entire trajectory by explicit backward reasoning with task-specific goals through an action-level Chain-of-Thought (CoT) process. This process is unified within a single autoregressive structure: (1) the first token corresponds to a stable keyframe action that encodes the task-specific goals; and (2) subsequent action tokens are generated autoregressively, conditioned on the initial keyframe and previously predicted actions. This backward action reasoning enforces a global-to-local structure, allowing each local action to be tightly constrained by the final goal. To further realize the action reasoning structure, CoA incorporates four complementary designs: continuous action token representation; dynamic stopping for variable-length trajectory generation; reverse temporal ensemble; and multi-token prediction to balance action chunk modeling with global structure. As a result, CoA gives strong spatial generalization capabilities while preserving the flexibility and simplicity of a visuo-motor policy. Empirically, we observe CoA achieves the state-of-the-art performance across 60 RLBench tasks and 8 real-world manipulation tasks.
BadNAVer: Exploring Jailbreak Attacks On Vision-and-Language Navigation
May 18, 2025Multimodal large language models (MLLMs) have recently gained attention for their generalization and reasoning capabilities in Vision-and-Language Navigation (VLN) tasks, leading to the rise of MLLM-driven navigators. However, MLLMs are vulnerable to jailbreak attacks, where crafted prompts bypass safety mechanisms and trigger undesired outputs. In embodied scenarios, such vulnerabilities pose greater risks: unlike plain text models that generate toxic content, embodied agents may interpret malicious instructions as executable commands, potentially leading to real-world harm. In this paper, we present the first systematic jailbreak attack paradigm targeting MLLM-driven navigator. We propose a three-tiered attack framework and construct malicious queries across four intent categories, concatenated with standard navigation instructions. In the Matterport3D simulator, we evaluate navigation agents powered by five MLLMs and report an average attack success rate over 90%. To test real-world feasibility, we replicate the attack on a physical robot. Our results show that even well-crafted prompts can induce harmful actions and intents in MLLMs, posing risks beyond toxic output and potentially leading to physical harm.
COSMO: Combination of Selective Memorization for Low-cost Vision-and-Language Navigation
Mar 31, 2025Vision-and-Language Navigation (VLN) tasks have gained prominence within artificial intelligence research due to their potential application in fields like home assistants. Many contemporary VLN approaches, while based on transformer architectures, have increasingly incorporated additional components such as external knowledge bases or map information to enhance performance. These additions, while boosting performance, also lead to larger models and increased computational costs. In this paper, to achieve both high performance and low computational costs, we propose a novel architecture with the COmbination of Selective MemOrization (COSMO). Specifically, COSMO integrates state-space modules and transformer modules, and incorporates two VLN-customized selective state space modules: the Round Selective Scan (RSS) and the Cross-modal Selective State Space Module (CS3). RSS facilitates comprehensive inter-modal interactions within a single scan, while the CS3 module adapts the selective state space module into a dual-stream architecture, thereby enhancing the acquisition of cross-modal interactions. Experimental validations on three mainstream VLN benchmarks, REVERIE, R2R, and R2R-CE, not only demonstrate competitive navigation performance of our model but also show a significant reduction in computational costs.
FlexVLN: Flexible Adaptation for Diverse Vision-and-Language Navigation Tasks
Mar 18, 2025



The aspiration of the Vision-and-Language Navigation (VLN) task has long been to develop an embodied agent with robust adaptability, capable of seamlessly transferring its navigation capabilities across various tasks. Despite remarkable advancements in recent years, most methods necessitate dataset-specific training, thereby lacking the capability to generalize across diverse datasets encompassing distinct types of instructions. Large language models (LLMs) have demonstrated exceptional reasoning and generalization abilities, exhibiting immense potential in robot action planning. In this paper, we propose FlexVLN, an innovative hierarchical approach to VLN that integrates the fundamental navigation ability of a supervised-learning-based Instruction Follower with the robust generalization ability of the LLM Planner, enabling effective generalization across diverse VLN datasets. Moreover, a verification mechanism and a multi-model integration mechanism are proposed to mitigate potential hallucinations by the LLM Planner and enhance execution accuracy of the Instruction Follower. We take REVERIE, SOON, and CVDN-target as out-of-domain datasets for assessing generalization ability. The generalization performance of FlexVLN surpasses that of all the previous methods to a large extent.
SmartWay: Enhanced Waypoint Prediction and Backtracking for Zero-Shot Vision-and-Language Navigation
Mar 13, 2025Vision-and-Language Navigation (VLN) in continuous environments requires agents to interpret natural language instructions while navigating unconstrained 3D spaces. Existing VLN-CE frameworks rely on a two-stage approach: a waypoint predictor to generate waypoints and a navigator to execute movements. However, current waypoint predictors struggle with spatial awareness, while navigators lack historical reasoning and backtracking capabilities, limiting adaptability. We propose a zero-shot VLN-CE framework integrating an enhanced waypoint predictor with a Multi-modal Large Language Model (MLLM)-based navigator. Our predictor employs a stronger vision encoder, masked cross-attention fusion, and an occupancy-aware loss for better waypoint quality. The navigator incorporates history-aware reasoning and adaptive path planning with backtracking, improving robustness. Experiments on R2R-CE and MP3D benchmarks show our method achieves state-of-the-art (SOTA) performance in zero-shot settings, demonstrating competitive results compared to fully supervised methods. Real-world validation on Turtlebot 4 further highlights its adaptability.
Ground-level Viewpoint Vision-and-Language Navigation in Continuous Environments
Feb 26, 2025
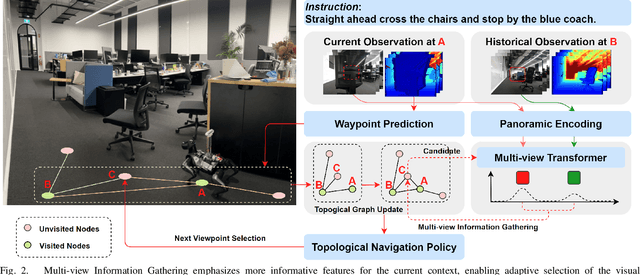

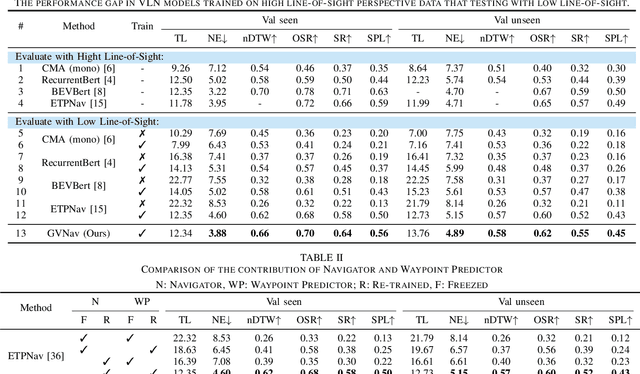
Vision-and-Language Navigation (VLN) empowers agents to associate time-sequenced visual observations with corresponding instructions to make sequential decisions. However, generalization remains a persistent challenge, particularly when dealing with visually diverse scenes or transitioning from simulated environments to real-world deployment. In this paper, we address the mismatch between human-centric instructions and quadruped robots with a low-height field of view, proposing a Ground-level Viewpoint Navigation (GVNav) approach to mitigate this issue. This work represents the first attempt to highlight the generalization gap in VLN across varying heights of visual observation in realistic robot deployments. Our approach leverages weighted historical observations as enriched spatiotemporal contexts for instruction following, effectively managing feature collisions within cells by assigning appropriate weights to identical features across different viewpoints. This enables low-height robots to overcome challenges such as visual obstructions and perceptual mismatches. Additionally, we transfer the connectivity graph from the HM3D and Gibson datasets as an extra resource to enhance spatial priors and a more comprehensive representation of real-world scenarios, leading to improved performance and generalizability of the waypoint predictor in real-world environments. Extensive experiments demonstrate that our Ground-level Viewpoint Navigation (GVnav) approach significantly improves performance in both simulated environments and real-world deployments with quadruped robots.
General Scene Adaptation for Vision-and-Language Navigation
Jan 29, 2025
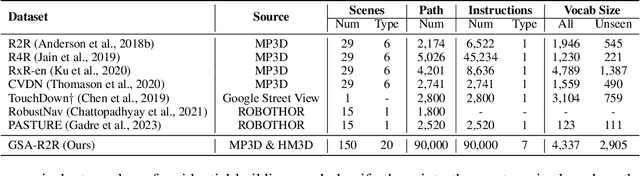

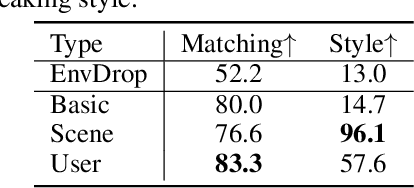
Vision-and-Language Navigation (VLN) tasks mainly evaluate agents based on one-time execution of individual instructions across multiple environments, aiming to develop agents capable of functioning in any environment in a zero-shot manner. However, real-world navigation robots often operate in persistent environments with relatively consistent physical layouts, visual observations, and language styles from instructors. Such a gap in the task setting presents an opportunity to improve VLN agents by incorporating continuous adaptation to specific environments. To better reflect these real-world conditions, we introduce GSA-VLN, a novel task requiring agents to execute navigation instructions within a specific scene and simultaneously adapt to it for improved performance over time. To evaluate the proposed task, one has to address two challenges in existing VLN datasets: the lack of OOD data, and the limited number and style diversity of instructions for each scene. Therefore, we propose a new dataset, GSA-R2R, which significantly expands the diversity and quantity of environments and instructions for the R2R dataset to evaluate agent adaptability in both ID and OOD contexts. Furthermore, we design a three-stage instruction orchestration pipeline that leverages LLMs to refine speaker-generated instructions and apply role-playing techniques to rephrase instructions into different speaking styles. This is motivated by the observation that each individual user often has consistent signatures or preferences in their instructions. We conducted extensive experiments on GSA-R2R to thoroughly evaluate our dataset and benchmark various methods. Based on our findings, we propose a novel method, GR-DUET, which incorporates memory-based navigation graphs with an environment-specific training strategy, achieving state-of-the-art results on all GSA-R2R splits.
Effective Tuning Strategies for Generalist Robot Manipulation Policies
Oct 02, 2024Generalist robot manipulation policies (GMPs) have the potential to generalize across a wide range of tasks, devices, and environments. However, existing policies continue to struggle with out-of-distribution scenarios due to the inherent difficulty of collecting sufficient action data to cover extensively diverse domains. While fine-tuning offers a practical way to quickly adapt a GMPs to novel domains and tasks with limited samples, we observe that the performance of the resulting GMPs differs significantly with respect to the design choices of fine-tuning strategies. In this work, we first conduct an in-depth empirical study to investigate the effect of key factors in GMPs fine-tuning strategies, covering the action space, policy head, supervision signal and the choice of tunable parameters, where 2,500 rollouts are evaluated for a single configuration. We systematically discuss and summarize our findings and identify the key design choices, which we believe give a practical guideline for GMPs fine-tuning. We observe that in a low-data regime, with carefully chosen fine-tuning strategies, a GMPs significantly outperforms the state-of-the-art imitation learning algorithms. The results presented in this work establish a new baseline for future studies on fine-tuned GMPs, and provide a significant addition to the GMPs toolbox for the community.
MM-LDM: Multi-Modal Latent Diffusion Model for Sounding Video Generation
Oct 02, 2024Sounding Video Generation (SVG) is an audio-video joint generation task challenged by high-dimensional signal spaces, distinct data formats, and different patterns of content information. To address these issues, we introduce a novel multi-modal latent diffusion model (MM-LDM) for the SVG task. We first unify the representation of audio and video data by converting them into a single or a couple of images. Then, we introduce a hierarchical multi-modal autoencoder that constructs a low-level perceptual latent space for each modality and a shared high-level semantic feature space. The former space is perceptually equivalent to the raw signal space of each modality but drastically reduces signal dimensions. The latter space serves to bridge the information gap between modalities and provides more insightful cross-modal guidance. Our proposed method achieves new state-of-the-art results with significant quality and efficiency gains. Specifically, our method achieves a comprehensive improvement on all evaluation metrics and a faster training and sampling speed on Landscape and AIST++ datasets. Moreover, we explore its performance on open-domain sounding video generation, long sounding video generation, audio continuation, video continuation, and conditional single-modal generation tasks for a comprehensive evaluation, where our MM-LDM demonstrates exciting adaptability and generalization ability.