 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Action: Trajectory Autoregressive Modeling for Robotic Manipulation
Jun 11, 2025We present Chain-of-Action (CoA), a novel visuo-motor policy paradigm built upon Trajectory Autoregressive Modeling. Unlike conventional approaches that predict next step action(s) forward, CoA generates an entire trajectory by explicit backward reasoning with task-specific goals through an action-level Chain-of-Thought (CoT) process. This process is unified within a single autoregressive structure: (1) the first token corresponds to a stable keyframe action that encodes the task-specific goals; and (2) subsequent action tokens are generated autoregressively, conditioned on the initial keyframe and previously predicted actions. This backward action reasoning enforces a global-to-local structure, allowing each local action to be tightly constrained by the final goal. To further realize the action reasoning structure, CoA incorporates four complementary designs: continuous action token representation; dynamic stopping for variable-length trajectory generation; reverse temporal ensemble; and multi-token prediction to balance action chunk modeling with global structure. As a result, CoA gives strong spatial generalization capabilities while preserving the flexibility and simplicity of a visuo-motor policy. Empirically, we observe CoA achieves the state-of-the-art performance across 60 RLBench tasks and 8 real-world manipulation tasks.
Robot Operation of Home Appliances by Reading User Manuals
May 26, 2025

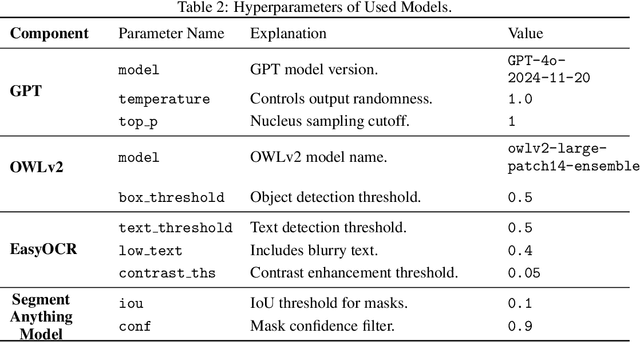

Operating home appliances, among the most common tools in every household, is a critical capability for assistive home robots. This paper presents ApBot, a robot system that operates novel household appliances by "reading" their user manuals. ApBot faces multiple challenges: (i) infer goal-conditioned partial policies from their unstructured, textual descriptions in a user manual document, (ii) ground the policies to the appliance in the physical world, and (iii) execute the policies reliably over potentially many steps, despite compounding errors. To tackle these challenges, ApBot constructs a structured, symbolic model of an appliance from its manual, with the help of a large vision-language model (VLM). It grounds the symbolic actions visually to control panel elements. Finally, ApBot closes the loop by updating the model based on visual feedback. Our experiments show that across a wide range of simulated and real-world appliances, ApBot achieves consistent and statistically significant improvements in task success rate, compared with state-of-the-art large VLMs used directly as control policies. These results suggest that a structured internal representations plays an important role in robust robot operation of home appliances, especially, complex ones.
RTV-Bench: Benchmarking MLLM Continuous Perception, Understanding and Reasoning through Real-Time Video
May 04, 2025Multimodal Large Language Models (MLLMs) increasingly excel at perception, understanding, and reasoning. However, current benchmarks inadequately evaluate their ability to perform these tasks continuously in dynamic, real-world environments. To bridge this gap, we introduce RTV-Bench, a fine-grained benchmark for MLLM real-time video analysis. RTV-Bench uses three key principles: (1) Multi-Timestamp Question Answering (MTQA), where answers evolve with scene changes; (2) Hierarchical Question Structure, combining basic and advanced queries; and (3) Multi-dimensional Evaluation, assessing the ability of continuous perception, understanding, and reasoning. RTV-Bench contains 552 diverse videos (167.2 hours) and 4,631 high-quality QA pairs. We evaluated leading MLLMs, including proprietary (GPT-4o, Gemini 2.0), open-source offline (Qwen2.5-VL, VideoLLaMA3), and open-source real-time (VITA-1.5, InternLM-XComposer2.5-OmniLive) models. Experiment results show open-source real-time models largely outperform offline ones but still trail top proprietary models. Our analysis also reveals that larger model size or higher frame sampling rates do not significantly boost RTV-Bench performance, sometimes causing slight decreases. This underscores the need for better model architectures optimized for video stream processing and long sequences to advance real-time video analysis with MLLMs. Our benchmark toolkit is available at: https://github.com/LJungang/RTV-Bench.
MInCo: Mitigating Information Conflicts in Distracted Visual Model-based Reinforcement Learning
Apr 05, 2025Existing visual model-based reinforcement learning (MBRL) algorithms with observation reconstruction often suffer from information conflicts, making it difficult to learn compact representations and hence result in less robust policies, especially in the presence of task-irrelevant visual distractions. In this paper, we first reveal that the information conflicts in current visual MBRL algorithms stem from visual representation learning and latent dynamics modeling with an information-theoretic perspective. Based on this finding, we present a new algorithm to resolve information conflicts for visual MBRL, named MInCo, which mitigates information conflicts by leveraging negative-free contrastive learning, aiding in learning invariant representation and robust policies despite noisy observations. To prevent the dominance of visual representation learning, we introduce time-varying reweighting to bias the learning towards dynamics modeling as training proceeds. We evaluate our method on several robotic control tasks with dynamic background distractions. Our experiments demonstrate that MInCo learns invariant representations against background noise and consistently outperforms current state-of-the-art visual MBRL methods. Code is available at https://github.com/ShiguangSun/minco.
FUNCTO: Function-Centric One-Shot Imitation Learning for Tool Manipulation
Feb 17, 2025



Learning tool use from a single human demonstration video offers a highly intuitive and efficient approach to robot teaching. While humans can effortlessly generalize a demonstrated tool manipulation skill to diverse tools that support the same function (e.g., pouring with a mug versus a teapot), current one-shot imitation learning (OSIL) methods struggle to achieve this. A key challenge lies in establishing functional correspondences between demonstration and test tools, considering significant geometric variations among tools with the same function (i.e., intra-function variations). To address this challenge, we propose FUNCTO (Function-Centric OSIL for Tool Manipulation), an OSIL method that establishes function-centric correspondences with a 3D functional keypoint representation, enabling robots to generalize tool manipulation skills from a single human demonstration video to novel tools with the same function despite significant intra-function variations. With this formulation, we factorize FUNCTO into three stages: (1) functional keypoint extraction, (2) function-centric correspondence establishment, and (3) functional keypoint-based action planning. We evaluate FUNCTO against exiting modular OSIL methods and end-to-end behavioral cloning methods through real-robot experiments on diverse tool manipulation tasks. The results demonstrate the superiority of FUNCTO when generalizing to novel tools with intra-function geometric variations. More details are available at https://sites.google.com/view/functo.
Towards Generalist Robot Policies: What Matters in Building Vision-Language-Action Models
Dec 18, 2024

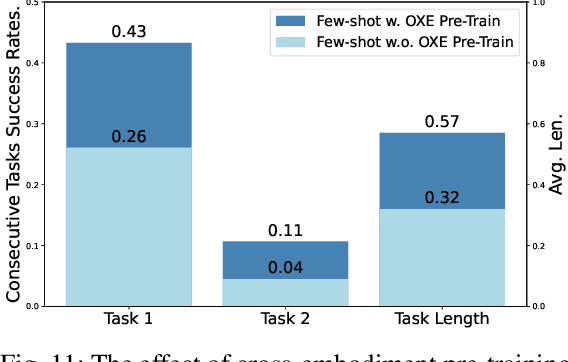

Foundation Vision Language Models (VLMs) exhibit strong capabilities in multi-modal representation learning, comprehension, and reasoning. By injecting action components into the VLMs, Vision-Language-Action Models (VLAs) can be naturally formed and also show promising performance. Existing work has demonstrated the effectiveness and generalization of VLAs in multiple scenarios and tasks. Nevertheless, the transfer from VLMs to VLAs is not trivial since existing VLAs differ in their backbones, action-prediction formulations, data distributions, and training recipes. This leads to a missing piece for a systematic understanding of the design choices of VLAs. In this work, we disclose the key factors that significantly influence the performance of VLA and focus on answering three essential design choices: which backbone to select, how to formulate the VLA architectures, and when to add cross-embodiment data. The obtained results convince us firmly to explain why we need VLA and develop a new family of VLAs, RoboVLMs, which require very few manual designs and achieve a new state-of-the-art performance in three simulation tasks and real-world experiments. Through our extensive experiments, which include over 8 VLM backbones, 4 policy architectures, and over 600 distinct designed experiments, we provide a detailed guidebook for the future design of VLAs. In addition to the study, the highly flexible RoboVLMs framework, which supports easy integrations of new VLMs and free combinations of various design choices, is made public to facilitate future research. We open-source all details, including codes, models, datasets, and toolkits, along with detailed training and evaluation recipes at: robovlms.github.io.
REGNet V2: End-to-End REgion-based Grasp Detection Network for Grippers of Different Sizes in Point Clouds
Oct 12, 2024



Grasping has been a crucial but challenging problem in robotics for many years. One of the most important challenges is how to make grasping generalizable and robust to novel objects as well as grippers in unstructured environments. We present \regnet, a robotic grasping system that can adapt to different parallel jaws to grasp diversified objects. To support different grippers, \regnet embeds the gripper parameters into point clouds, based on which it predicts suitable grasp configurations. It includes three components: Score Network (SN), Grasp Region Network (GRN), and Refine Network (RN). In the first stage, SN is used to filter suitable points for grasping by grasp confidence scores. In the second stage, based on the selected points, GRN generates a set of grasp proposals. Finally, RN refines the grasp proposals for more accurate and robust predictions. We devise an analytic policy to choose the optimal grasp to be executed from the predicted grasp set. To train \regnet, we construct a large-scale grasp dataset containing collision-free grasp configurations using different parallel-jaw grippers. The experimental results demonstrate that \regnet with the analytic policy achieves the highest success rate of $74.98\%$ in real-world clutter scenes with $20$ objects, significantly outperforming several state-of-the-art methods, including GPD, PointNetGPD, and S4G. The code and dataset are available at https://github.com/zhaobinglei/REGNet-V2.
GR-2: A Generative Video-Language-Action Model with Web-Scale Knowledge for Robot Manipulation
Oct 08, 2024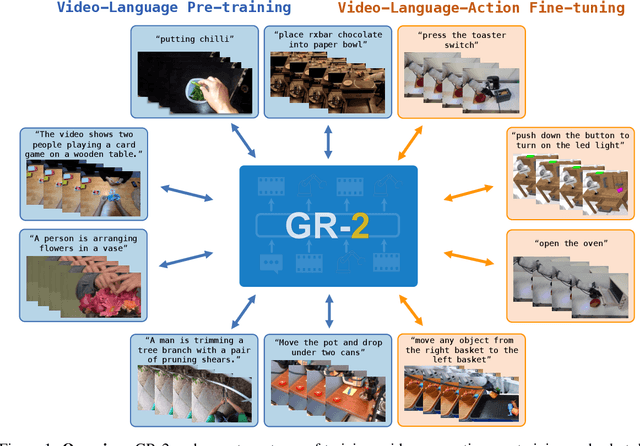
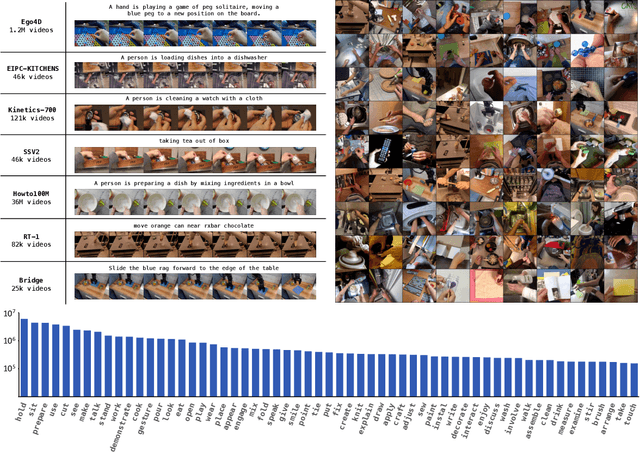


We present GR-2, a state-of-the-art generalist robot agent for versatile and generalizable robot manipulation. GR-2 is first pre-trained on a vast number of Internet videos to capture the dynamics of the world. This large-scale pre-training, involving 38 million video clips and over 50 billion tokens, equips GR-2 with the ability to generalize across a wide range of robotic tasks and environments during subsequent policy learning. Following this, GR-2 is fine-tuned for both video generation and action prediction using robot trajectories. It exhibits impressive multi-task learning capabilities, achieving an average success rate of 97.7% across more than 100 tasks. Moreover, GR-2 demonstrates exceptional generalization to new, previously unseen scenarios, including novel backgrounds, environments, objects, and tasks. Notably, GR-2 scales effectively with model size, underscoring its potential for continued growth and application. Project page: \url{https://gr2-manipulation.github.io}.
DexDiff: Towards Extrinsic Dexterity Manipulation of Ungraspable Objects in Unrestricted Environments
Sep 09, 2024

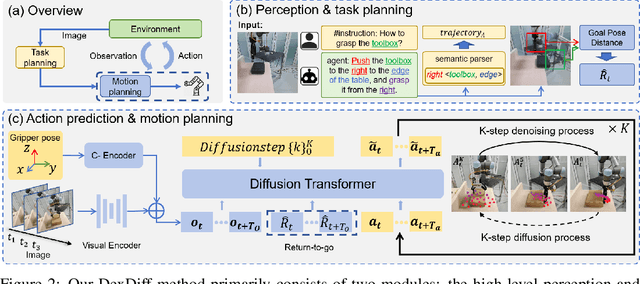

Grasping large and flat objects (e.g. a book or a pan) is often regarded as an ungraspable task, which poses significant challenges due to the unreachable grasping poses. Previous works leverage Extrinsic Dexterity like walls or table edges to grasp such objects. However, they are limited to task-specific policies and lack task planning to find pre-grasp conditions. This makes it difficult to adapt to various environments and extrinsic dexterity constraints. Therefore, we present DexDiff, a robust robotic manipulation method for long-horizon planning with extrinsic dexterity. Specifically, we utilize a vision-language model (VLM) to perceive the environmental state and generate high-level task plans, followed by a goal-conditioned action diffusion (GCAD) model to predict the sequence of low-level actions. This model learns the low-level policy from offline data with the cumulative reward guided by high-level planning as the goal condition, which allows for improved prediction of robot actions. Experimental results demonstrate that our method not only effectively performs ungraspable tasks but also generalizes to previously unseen objects. It outperforms baselines by a 47% higher success rate in simulation and facilitates efficient deployment and manipulation in real-world scenarios.
SInViG: A Self-Evolving Interactive Visual Agent for Human-Robot Interaction
Feb 20, 2024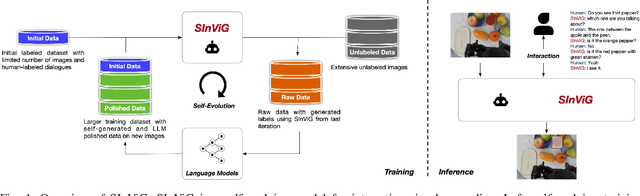


Linguistic ambiguity is ubiquitous in our daily lives. Previous works adopted interaction between robots and humans for language disambiguation. Nevertheless, when interactive robots are deployed in daily environments, there are significant challenges for natural human-robot interaction, stemming from complex and unpredictable visual inputs, open-ended interaction, and diverse user demands. In this paper, we present SInViG, which is a self-evolving interactive visual agent for human-robot interaction based on natural languages, aiming to resolve language ambiguity, if any, through multi-turn visual-language dialogues. It continuously and automatically learns from unlabeled images and large language models, without human intervention, to be more robust against visual and linguistic complexity. Benefiting from self-evolving, it sets new state-of-the-art on several interactive visual grounding benchmarks. Moreover, our human-robot interaction experiments show that the evolved models consistently acquire more and more preferences from human users. Besides, we also deployed our model on a Franka robot for interactive manipulation tasks. Results demonstrate that our model can follow diverse user instructions and interact naturally with humans in natural language, despite the complexity and disturbance of the environment.