 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: Projection-based Reward Integration for Scene-Aware Real-to-Sim-to-Real Transfer with Few Demonstrations
Apr 29, 2025Learning from few demonstrations to develop policies robust to variations in robot initial positions and object poses is a problem of significant practical interest in robotics. Compared to imitation learning, which often struggles to generalize from limited samples, reinforcement learning (RL) can autonomously explore to obtain robust behaviors. Training RL agents through direct interaction with the real world is often impractical and unsafe, while building simulation environments requires extensive manual effort, such as designing scenes and crafting task-specific reward functions. To address these challenges, we propose an integrated real-to-sim-to-real pipeline that constructs simulation environments based on expert demonstrations by identifying scene objects from images and retrieving their corresponding 3D models from existing libraries. We introduce a projection-based reward model for RL policy training that is supervised by a vision-language model (VLM) using human-guided object projection relationships as prompts, with the policy further fine-tuned using expert demonstrations. In general, our work focuses on the construction of simulation environments and RL-based policy training, ultimately enabling the deployment of reliable robotic control policies in real-world scenarios.
REGNet V2: End-to-End REgion-based Grasp Detection Network for Grippers of Different Sizes in Point Clouds
Oct 12, 2024



Grasping has been a crucial but challenging problem in robotics for many years. One of the most important challenges is how to make grasping generalizable and robust to novel objects as well as grippers in unstructured environments. We present \regnet, a robotic grasping system that can adapt to different parallel jaws to grasp diversified objects. To support different grippers, \regnet embeds the gripper parameters into point clouds, based on which it predicts suitable grasp configurations. It includes three components: Score Network (SN), Grasp Region Network (GRN), and Refine Network (RN). In the first stage, SN is used to filter suitable points for grasping by grasp confidence scores. In the second stage, based on the selected points, GRN generates a set of grasp proposals. Finally, RN refines the grasp proposals for more accurate and robust predictions. We devise an analytic policy to choose the optimal grasp to be executed from the predicted grasp set. To train \regnet, we construct a large-scale grasp dataset containing collision-free grasp configurations using different parallel-jaw grippers. The experimental results demonstrate that \regnet with the analytic policy achieves the highest success rate of $74.98\%$ in real-world clutter scenes with $20$ objects, significantly outperforming several state-of-the-art methods, including GPD, PointNetGPD, and S4G. The code and dataset are available at https://github.com/zhaobinglei/REGNet-V2.
DexDiff: Towards Extrinsic Dexterity Manipulation of Ungraspable Objects in Unrestricted Environments
Sep 09, 2024

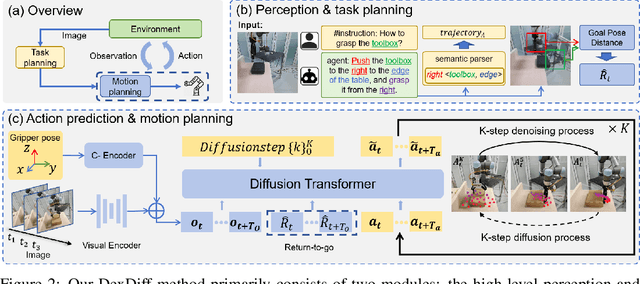

Grasping large and flat objects (e.g. a book or a pan) is often regarded as an ungraspable task, which poses significant challenges due to the unreachable grasping poses. Previous works leverage Extrinsic Dexterity like walls or table edges to grasp such objects. However, they are limited to task-specific policies and lack task planning to find pre-grasp conditions. This makes it difficult to adapt to various environments and extrinsic dexterity constraints. Therefore, we present DexDiff, a robust robotic manipulation method for long-horizon planning with extrinsic dexterity. Specifically, we utilize a vision-language model (VLM) to perceive the environmental state and generate high-level task plans, followed by a goal-conditioned action diffusion (GCAD) model to predict the sequence of low-level actions. This model learns the low-level policy from offline data with the cumulative reward guided by high-level planning as the goal condition, which allows for improved prediction of robot actions. Experimental results demonstrate that our method not only effectively performs ungraspable tasks but also generalizes to previously unseen objects. It outperforms baselines by a 47% higher success rate in simulation and facilitates efficient deployment and manipulation in real-world scenarios.
Prioritized Planning for Target-Oriented Manipulation via Hierarchical Stacking Relationship Prediction
Mar 14, 2023In scenarios involving the grasping of multiple targets, the learning of stacking relationships between objects is fundamental for robots to execute safely and efficiently. However, current methods lack subdivision for the hierarchy of stacking relationship types. In scenes where objects are mostly stacked in an orderly manner, they are incapable of performing human-like and high-efficient grasping decisions. This paper proposes a perception-planning method to distinguish different stacking types between objects and generate prioritized manipulation order decisions based on given target designations. We utilize a Hierarchical Stacking Relationship Network (HSRN) to discriminate the hierarchy of stacking and generate a refined Stacking Relationship Tree (SRT) for relationship description. Considering that objects with high stacking stability can be grasped together if necessary, we introduce an elaborate decision-making planner based on the Partially Observable Markov Decision Process (POMDP), which leverages observations and generates the least grasp-consuming decision chain with robustness and is suitable for simultaneously specifying multiple targets. To verify our work, we set the scene to the dining table and augment the REGRAD dataset with a set of common tableware models for network training. Experiments show that our method effectively generates grasping decisions that conform to human requirements, and improves the implementation efficiency compared with existing methods on the basis of guaranteeing the success rate.