 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR2RDreamer: 3D-aware Data Augmentation for Spatially-generalized 2D Manipulation Policies
Jun 15, 2026Spatial generalization is critical for imitation-learned manipulation policies, but achieving it typically requires scaling demonstrations across diverse object poses, robot configurations, and camera viewpoints. Data augmentation from a few source demonstrations offers a practical alternative to costly real-world collection. Simulation-based augmentation can create controllable variation, but requires complex environment and object setup and may introduce a sim-to-real gap. Recent real-to-real methods avoid these issues by jointly editing 3D observations and action trajectories from real demonstrations, yet they still rely on strong 3D scene parsing and geometry completion, and often produce observations tailored to 3D pointcloud policies rather than RGB-based 2D policies. We propose R2RDreamer, a real-to-real demonstration augmentation framework that preserves the geometric consistency of 3D action-observation editing while moving visual completion to 2D video space. Specifically, R2RDreamer first performs lightweight 3D augmentation by editing incomplete object pointclouds and end-effector trajectories in a shared 3D frame; it then projects the edited scene into masked image-space control videos with occlusion-aware reasoning and uses a dense-control image-to-video model to complete temporally coherent RGB observations. Experiments on spatially shifted manipulation tasks with both 2D diffusion-style policies and vision-language-action policies show that R2RDreamer improves spatial generalization from limited source demonstrations, with analyses validating the contributions of 3D editing, occlusion-aware projection, and video completion.
OASIS: Observation-Action Space Alignment via SE(3) Trajectory Prediction for Robotic Manipulation
May 25, 2026Recent vision-language-action (VLA) models and world action models (WAMs) advance robotic manipulation by enriching intermediate representations with auxiliary spatial features or future visual-state prediction. However, these representations largely remain within the observation space and do not share the rigid-body geometry of the action space, forcing the action decoder to implicitly recover this geometry. We propose OASIS, a visuomotor policy that aligns the intermediate representation with the action space via $SE(3)$ end-effector trajectory prediction. OASIS couples a 3D-aware feature encoder that fuses vision-language and metric-depth features with an $SE(3)$ trajectory predictor that produces a camera-frame end-effector trajectory. Conditioned on the predictor's pose-supervised hidden states, the action decoder generates action chunks consistent with rigid-body motion. Across simulation and real-world experiments, OASIS outperforms VLA and WAM baselines in success rate and out-of-distribution generalization. Our project page is available at https://npuhandsome.github.io/OASIS_web.
AffordSim: A Scalable Data Generator and Benchmark for Affordance-Aware Robotic Manipulation
Apr 13, 2026Simulation-based data generation has become a dominant paradigm for training robotic manipulation policies, yet existing platforms do not incorporate object affordance information into trajectory generation. As a result, tasks requiring precise interaction with specific functional regions--grasping a mug by its handle, pouring from a cup's rim, or hanging a mug on a hook--cannot be automatically generated with semantically correct trajectories. We introduce AffordSim, the first simulation framework that integrates open-vocabulary 3D affordance prediction into the manipulation data generation pipeline. AffordSim uses our VoxAfford model, an open-vocabulary 3D affordance detector that enhances MLLM output tokens with multi-scale geometric features, to predict affordance maps on object point clouds, guiding grasp pose estimation toward task-relevant functional regions. Built on NVIDIA Isaac Sim with cross-embodiment support (Franka FR3, Panda, UR5e, Kinova), VLM-powered task generation, and novel domain randomization using DA3-based 3D Gaussian reconstruction from real photographs, AffordSim enables automated, scalable generation of affordance-aware manipulation data. We establish a benchmark of 50 tasks across 7 categories (grasping, placing, stacking, pushing/pulling, pouring, mug hanging, long-horizon composite) and evaluate 4 imitation learning baselines (BC, Diffusion Policy, ACT, Pi 0.5). Our results reveal that while grasping is largely solved (53-93% success), affordance-demanding tasks such as pouring into narrow containers (1-43%) and mug hanging (0-47%) remain significantly more challenging for current imitation learning methods, highlighting the need for affordance-aware data generation. Zero-shot sim-to-real experiments on a real Franka FR3 validate the transferability of the generated data.
RoboTAG: End-to-end Robot Configuration Estimation via Topological Alignment Graph
Nov 11, 2025Estimating robot pose from a monocular RGB image is a challenge in robotics and computer vision. Existing methods typically build networks on top of 2D visual backbones and depend heavily on labeled data for training, which is often scarce in real-world scenarios, causing a sim-to-real gap. Moreover, these approaches reduce the 3D-based problem to 2D domain, neglecting the 3D priors. To address these, we propose Robot Topological Alignment Graph (RoboTAG), which incorporates a 3D branch to inject 3D priors while enabling co-evolution of the 2D and 3D representations, alleviating the reliance on labels. Specifically, the RoboTAG consists of a 3D branch and a 2D branch, where nodes represent the states of the camera and robot system, and edges capture the dependencies between these variables or denote alignments between them. Closed loops are then defined in the graph, on which a consistency supervision across branches can be applied. This design allows us to utilize in-the-wild images as training data without annotations. Experimental results demonstrate that our method is effective across robot types, highlighting its potential to alleviate the data bottleneck in robotics.
Ambiguity-aware Point Cloud Segmentation by Adaptive Margin Contrastive Learning
Jul 09, 2025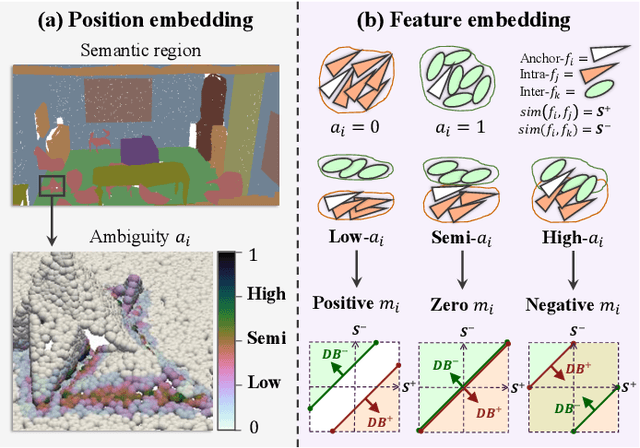
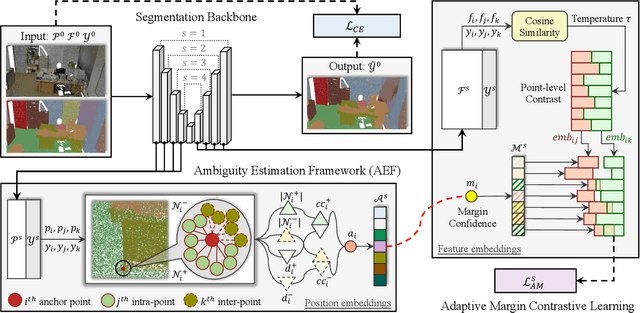
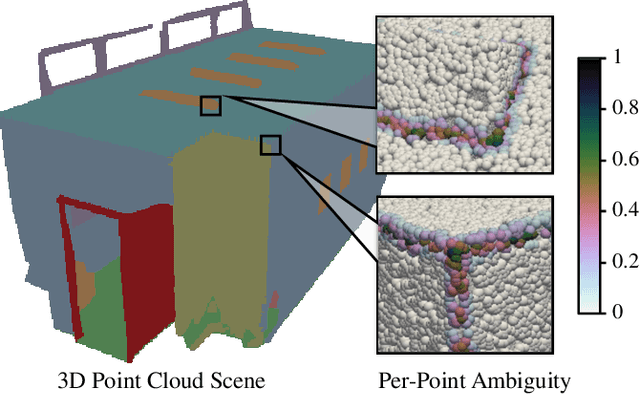
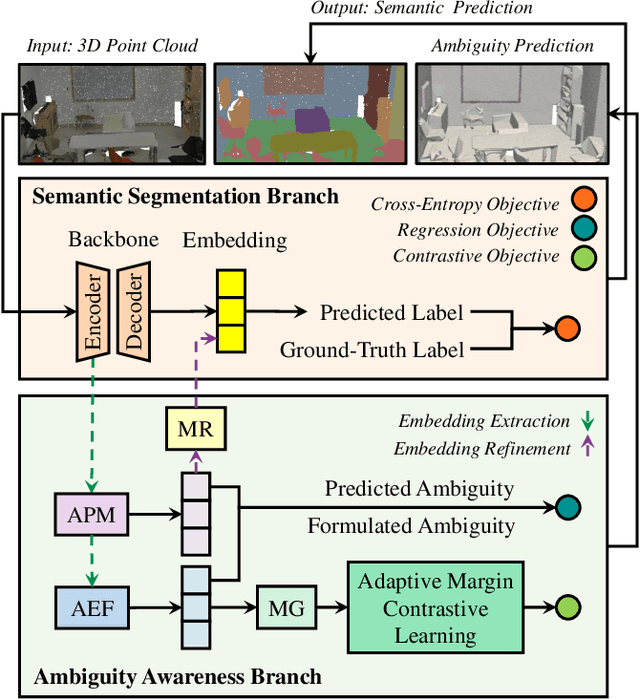
This paper proposes an adaptive margin contrastive learning method for 3D semantic segmentation on point clouds. Most existing methods use equally penalized objectives, which ignore the per-point ambiguities and less discriminated features stemming from transition regions. However, as highly ambiguous points may be indistinguishable even for humans, their manually annotated labels are less reliable, and hard constraints over these points would lead to sub-optimal models. To address this, we first design AMContrast3D, a method comprising contrastive learning into an ambiguity estimation framework, tailored to adaptive objectives for individual points based on ambiguity levels. As a result, our method promotes model training, which ensures the correctness of low-ambiguity points while allowing mistakes for high-ambiguity points. As ambiguities are formulated based on position discrepancies across labels, optimization during inference is constrained by the assumption that all unlabeled points are uniformly unambiguous, lacking ambiguity awareness. Inspired by the insight of joint training, we further propose AMContrast3D++ integrating with two branches trained in parallel, where a novel ambiguity prediction module concurrently learns point ambiguities from generated embeddings. To this end, we design a masked refinement mechanism that leverages predicted ambiguities to enable the ambiguous embeddings to be more reliable, thereby boosting segmentation performance and enhancing robustness. Experimental results on 3D indoor scene datasets, S3DIS and ScanNet, demonstrate the effectiveness of the proposed method. Code is available at https://github.com/YangChenApril/AMContrast3D.
PointVDP: Learning View-Dependent Projection by Fireworks Rays for 3D Point Cloud Segmentation
Jul 09, 2025In this paper, we propose view-dependent projection (VDP) to facilitate point cloud segmentation, designing efficient 3D-to-2D mapping that dynamically adapts to the spatial geometry from view variations. Existing projection-based methods leverage view-independent projection in complex scenes, relying on straight lines to generate direct rays or upward curves to reduce occlusions. However, their view independence provides projection rays that are limited to pre-defined parameters by human settings, restricting point awareness and failing to capture sufficient projection diversity across different view planes. Although multiple projections per view plane are commonly used to enhance spatial variety, the projected redundancy leads to excessive computational overhead and inefficiency in image processing. To address these limitations, we design a framework of VDP to generate data-driven projections from 3D point distributions, producing highly informative single-image inputs by predicting rays inspired by the adaptive behavior of fireworks. In addition, we construct color regularization to optimize the framework, which emphasizes essential features within semantic pixels and suppresses the non-semantic features within black pixels, thereby maximizing 2D space utilization in a projected image. As a result, our approach, PointVDP, develops lightweight projections in marginal computation costs. Experiments on S3DIS and ScanNet benchmarks show that our approach achieves competitive results, offering a resource-efficient solution for semantic understanding.
VReST: Enhancing Reasoning in Large Vision-Language Models through Tree Search and Self-Reward Mechanism
Jun 10, 2025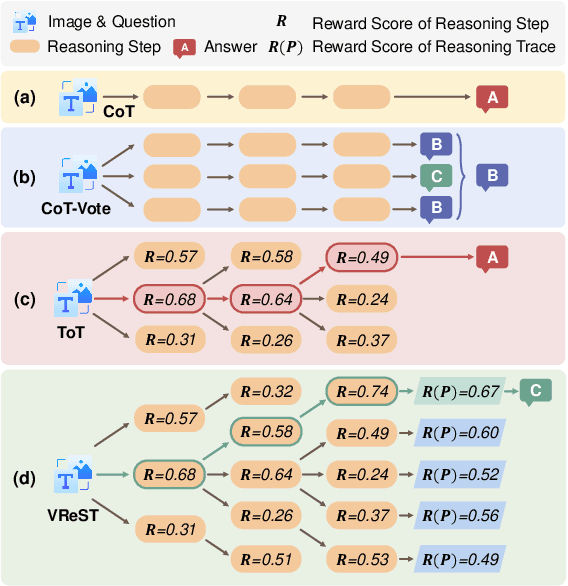
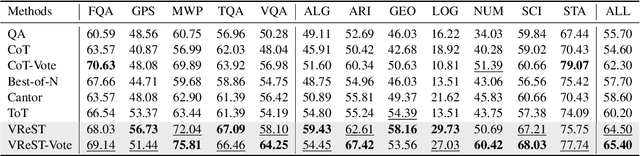
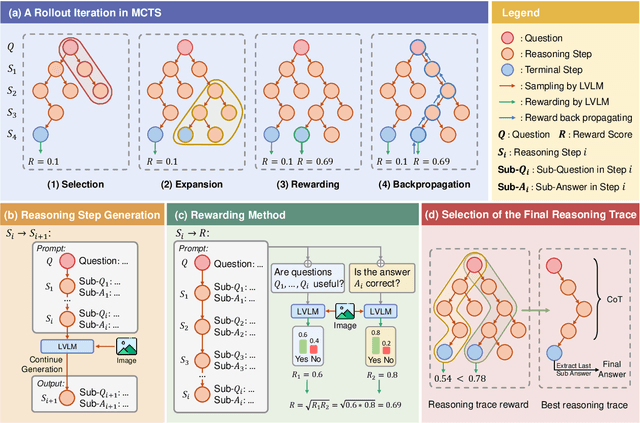
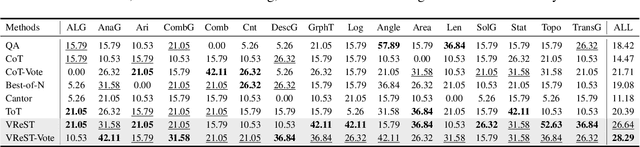
Large Vision-Language Models (LVLMs) have shown exceptional performance in multimodal tasks, but their effectiveness in complex visual reasoning is still constrained, especially when employing Chain-of-Thought prompting techniques. In this paper, we propose VReST, a novel training-free approach that enhances Reasoning in LVLMs through Monte Carlo Tree Search and Self-Reward mechanisms. VReST meticulously traverses the reasoning landscape by establishing a search tree, where each node encapsulates a reasoning step, and each path delineates a comprehensive reasoning sequence. Our innovative multimodal Self-Reward mechanism assesses the quality of reasoning steps by integrating the utility of sub-questions, answer correctness, and the relevance of vision-language clues, all without the need for additional models. VReST surpasses current prompting methods and secures state-of-the-art performance across three multimodal mathematical reasoning benchmarks. Furthermore, it substantiates the efficacy of test-time scaling laws in multimodal tasks, offering a promising direction for future research.
PRISM: Projection-based Reward Integration for Scene-Aware Real-to-Sim-to-Real Transfer with Few Demonstrations
Apr 29, 2025Learning from few demonstrations to develop policies robust to variations in robot initial positions and object poses is a problem of significant practical interest in robotics. Compared to imitation learning, which often struggles to generalize from limited samples, reinforcement learning (RL) can autonomously explore to obtain robust behaviors. Training RL agents through direct interaction with the real world is often impractical and unsafe, while building simulation environments requires extensive manual effort, such as designing scenes and crafting task-specific reward functions. To address these challenges, we propose an integrated real-to-sim-to-real pipeline that constructs simulation environments based on expert demonstrations by identifying scene objects from images and retrieving their corresponding 3D models from existing libraries. We introduce a projection-based reward model for RL policy training that is supervised by a vision-language model (VLM) using human-guided object projection relationships as prompts, with the policy further fine-tuned using expert demonstrations. In general, our work focuses on the construction of simulation environments and RL-based policy training, ultimately enabling the deployment of reliable robotic control policies in real-world scenarios.
Exploring Forgetting in Large Language Model Pre-Training
Oct 22, 2024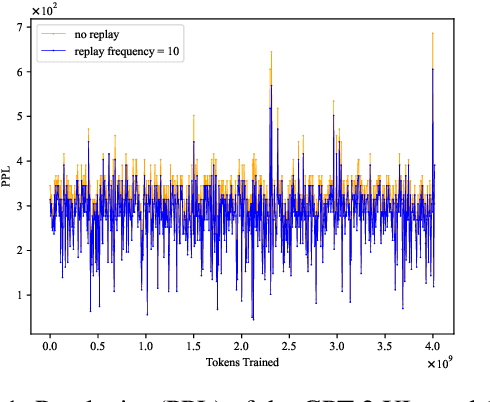
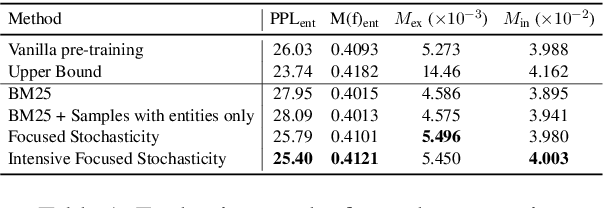
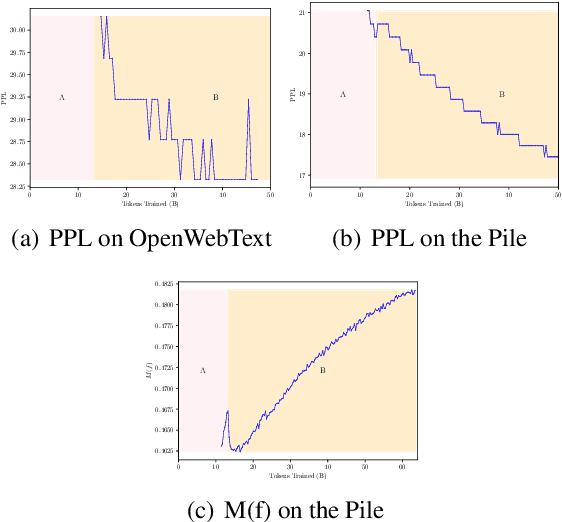
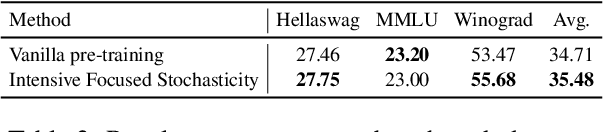
Catastrophic forgetting remains a formidable obstacle to building an omniscient model in large language models (LLMs). Despite the pioneering research on task-level forgetting in LLM fine-tuning, there is scant focus on forgetting during pre-training. We systematically explored the existence and measurement of forgetting in pre-training, questioning traditional metrics such as perplexity (PPL) and introducing new metrics to better detect entity memory retention. Based on our revised assessment of forgetting metrics, we explored low-cost, straightforward methods to mitigate forgetting during the pre-training phase. Further, we carefully analyzed the learning curves, offering insights into the dynamics of forgetting. Extensive evaluations and analyses on forgetting of pre-training could facilitate future research on LLMs.
ReconX: Reconstruct Any Scene from Sparse Views with Video Diffusion Model
Aug 29, 2024Advancements in 3D scene reconstruction have transformed 2D images from the real world into 3D models, producing realistic 3D results from hundreds of input photos. Despite great success in dense-view reconstruction scenarios, rendering a detailed scene from insufficient captured views is still an ill-posed optimization problem, often resulting in artifacts and distortions in unseen areas. In this paper, we propose ReconX, a novel 3D scene reconstruction paradigm that reframes the ambiguous reconstruction challenge as a temporal generation task. The key insight is to unleash the strong generative prior of large pre-trained video diffusion models for sparse-view reconstruction. However, 3D view consistency struggles to be accurately preserved in directly generated video frames from pre-trained models. To address this, given limited input views, the proposed ReconX first constructs a global point cloud and encodes it into a contextual space as the 3D structure condition. Guided by the condition, the video diffusion model then synthesizes video frames that are both detail-preserved and exhibit a high degree of 3D consistency, ensuring the coherence of the scene from various perspectives. Finally, we recover the 3D scene from the generated video through a confidence-aware 3D Gaussian Splatting optimization scheme. Extensive experiments on various real-world datasets show the superiority of our ReconX over state-of-the-art methods in terms of quality and generalizability.