 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamics-aware Adversarial Attack of 3D Sparse Convolution Network
Paper and Code
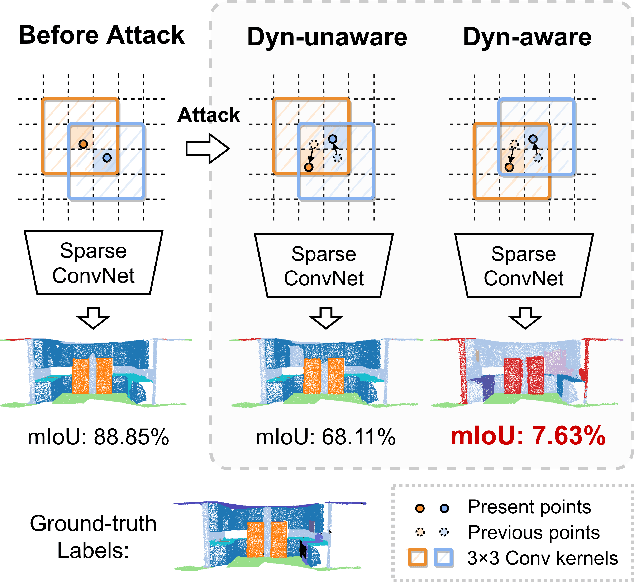

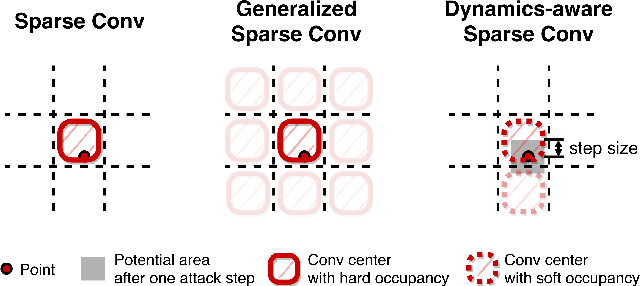
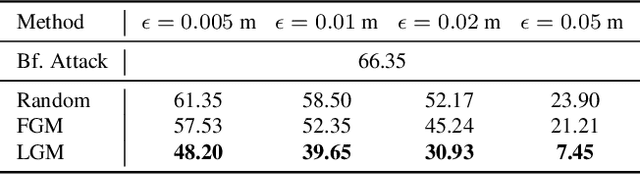
In this paper, we investigate the dynamics-aware adversarial attack problem in deep neural networks. Most existing adversarial attack algorithms are designed under a basic assumption -- the network architecture is fixed throughout the attack process. However, this assumption does not hold for many recently proposed networks, e.g. 3D sparse convolution network, which contains input-dependent execution to improve computational efficiency. It results in a serious issue of lagged gradient, making the learned attack at the current step ineffective due to the architecture changes afterward. To address this issue, we propose a Leaded Gradient Method (LGM) and show the significant effects of the lagged gradient. More specifically, we re-formulate the gradients to be aware of the potential dynamic changes of network architectures, so that the learned attack better "leads" the next step than the dynamics-unaware methods when network architecture changes dynamically. Extensive experiments on various datasets show that our LGM achieves impressive performance on semantic segmentation and classification. Compared with the dynamic-unaware methods, LGM achieves about 20% lower mIoU averagely on the ScanNet and S3DIS datasets. LGM also outperforms the recent point cloud attacks.