 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActionParty: Multi-Subject Action Binding in Generative Video Games
Apr 02, 2026Recent advances in video diffusion have enabled the development of "world models" capable of simulating interactive environments. However, these models are largely restricted to single-agent settings, failing to control multiple agents simultaneously in a scene. In this work, we tackle a fundamental issue of action binding in existing video diffusion models, which struggle to associate specific actions with their corresponding subjects. For this purpose, we propose ActionParty, an action controllable multi-subject world model for generative video games. It introduces subject state tokens, i.e. latent variables that persistently capture the state of each subject in the scene. By jointly modeling state tokens and video latents with a spatial biasing mechanism, we disentangle global video frame rendering from individual action-controlled subject updates. We evaluate ActionParty on the Melting Pot benchmark, demonstrating the first video world model capable of controlling up to seven players simultaneously across 46 diverse environments. Our results show significant improvements in action-following accuracy and identity consistency, while enabling robust autoregressive tracking of subjects through complex interactions.
Acceleration-Based Control of Fixed-Wing UAVs for Guidance Applications
Feb 27, 2026Acceleration-commanded guidance laws (e.g., proportional navigation) are attractive for high-level decision making, but their direct deployment on fixed-wing UAVs is challenging because accelerations are not directly actuated and must be realized through attitude and thrust under flight-envelope constraints. This paper presents an acceleration-level outer-loop control framework that converts commanded tangential and normal accelerations into executable body-rate and normalized thrust commands compatible with mainstream autopilots (e.g., PX4/APM). For the normal channel, we derive an engineering mapping from the desired normal acceleration to roll- and pitch-rate commands that regulate the direction and magnitude of the lift vector under small-angle assumptions. For the tangential channel, we introduce an energy-based formulation inspired by total energy control and identify an empirical thrust-energy acceleration relationship directly from flight data, avoiding explicit propulsion modeling or thrust bench calibration. We further discuss priority handling between normal and tangential accelerations under saturation and non-level maneuvers. Extensive real-flight experiments on a VTOL fixed-wing platform demonstrate accurate acceleration tracking and enable practical implementation of proportional navigation using only body-rate and normalized thrust interfaces.
360Anything: Geometry-Free Lifting of Images and Videos to 360°
Jan 22, 2026Lifting perspective images and videos to 360° panoramas enables immersive 3D world generation. Existing approaches often rely on explicit geometric alignment between the perspective and the equirectangular projection (ERP) space. Yet, this requires known camera metadata, obscuring the application to in-the-wild data where such calibration is typically absent or noisy. We propose 360Anything, a geometry-free framework built upon pre-trained diffusion transformers. By treating the perspective input and the panorama target simply as token sequences, 360Anything learns the perspective-to-equirectangular mapping in a purely data-driven way, eliminating the need for camera information. Our approach achieves state-of-the-art performance on both image and video perspective-to-360° generation, outperforming prior works that use ground-truth camera information. We also trace the root cause of the seam artifacts at ERP boundaries to zero-padding in the VAE encoder, and introduce Circular Latent Encoding to facilitate seamless generation. Finally, we show competitive results in zero-shot camera FoV and orientation estimation benchmarks, demonstrating 360Anything's deep geometric understanding and broader utility in computer vision tasks. Additional results are available at https://360anything.github.io/.
Memory-based Ensemble Learning in CMR Semantic Segmentation
Feb 13, 2025Existing models typically segment either the entire 3D frame or 2D slices independently to derive clinical functional metrics from ventricular segmentation in cardiac cine sequences. While performing well overall, they struggle at the end slices. To address this, we leverage spatial continuity to extract global uncertainty from segmentation variance and use it as memory in our ensemble learning method, Streaming, for classifier weighting, balancing overall and end-slice performance. Additionally, we introduce the End Coefficient (EC) to quantify end-slice accuracy. Experiments on ACDC and M\&Ms datasets show that our framework achieves near-state-of-the-art Dice Similarity Coefficient (DSC) and outperforms all models on end-slice performance, improving patient-specific segmentation accuracy.
Mind the Time: Temporally-Controlled Multi-Event Video Generation
Dec 06, 2024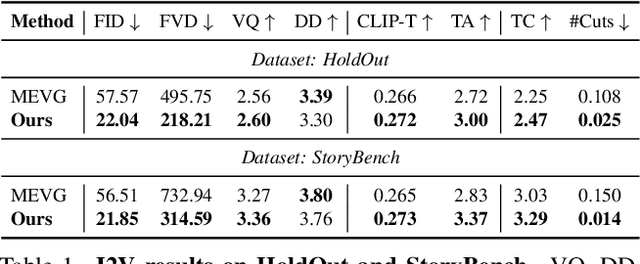

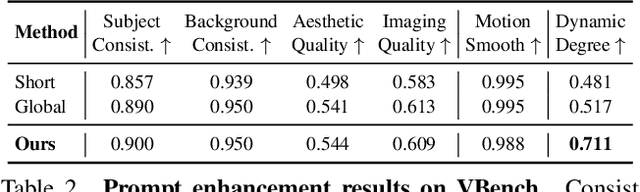
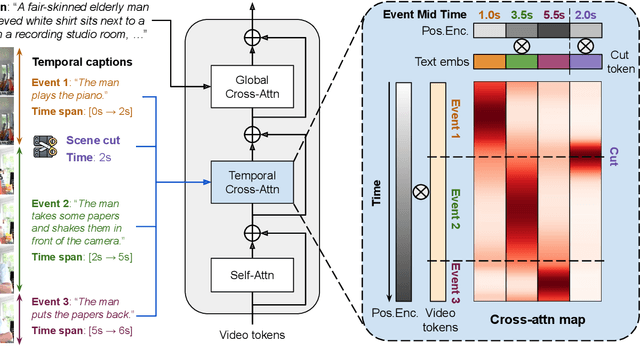
Real-world videos consist of sequences of events. Generating such sequences with precise temporal control is infeasible with existing video generators that rely on a single paragraph of text as input. When tasked with generating multiple events described using a single prompt, such methods often ignore some of the events or fail to arrange them in the correct order. To address this limitation, we present MinT, a multi-event video generator with temporal control. Our key insight is to bind each event to a specific period in the generated video, which allows the model to focus on one event at a time. To enable time-aware interactions between event captions and video tokens, we design a time-based positional encoding method, dubbed ReRoPE. This encoding helps to guide the cross-attention operation. By fine-tuning a pre-trained video diffusion transformer on temporally grounded data, our approach produces coherent videos with smoothly connected events. For the first time in the literature, our model offers control over the timing of events in generated videos. Extensive experiments demonstrate that MinT outperforms existing open-source models by a large margin.
SG-I2V: Self-Guided Trajectory Control in Image-to-Video Generation
Nov 07, 2024



Methods for image-to-video generation have achieved impressive, photo-realistic quality. However, adjusting specific elements in generated videos, such as object motion or camera movement, is often a tedious process of trial and error, e.g., involving re-generating videos with different random seeds. Recent techniques address this issue by fine-tuning a pre-trained model to follow conditioning signals, such as bounding boxes or point trajectories. Yet, this fine-tuning procedure can be computationally expensive, and it requires datasets with annotated object motion, which can be difficult to procure. In this work, we introduce SG-I2V, a framework for controllable image-to-video generation that is self-guided$\unicode{x2013}$offering zero-shot control by relying solely on the knowledge present in a pre-trained image-to-video diffusion model without the need for fine-tuning or external knowledge. Our zero-shot method outperforms unsupervised baselines while being competitive with supervised models in terms of visual quality and motion fidelity.
Neural Assets: 3D-Aware Multi-Object Scene Synthesis with Image Diffusion Models
Jun 13, 2024
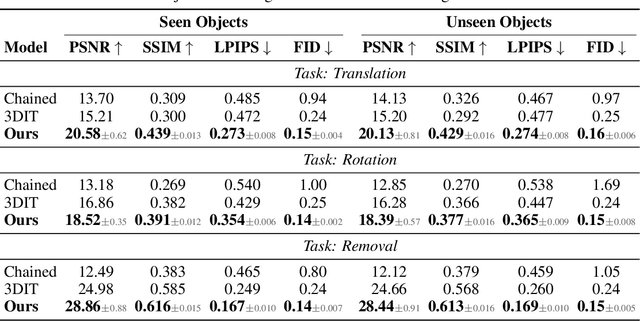

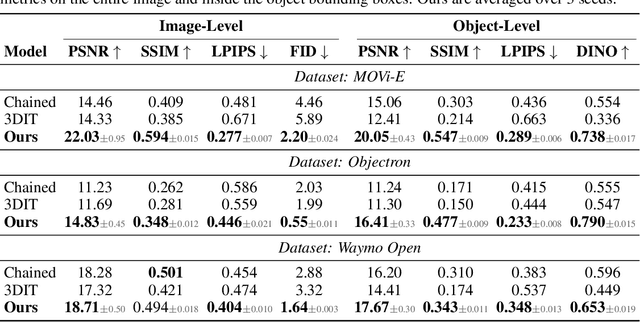
We address the problem of multi-object 3D pose control in image diffusion models. Instead of conditioning on a sequence of text tokens, we propose to use a set of per-object representations, Neural Assets, to control the 3D pose of individual objects in a scene. Neural Assets are obtained by pooling visual representations of objects from a reference image, such as a frame in a video, and are trained to reconstruct the respective objects in a different image, e.g., a later frame in the video. Importantly, we encode object visuals from the reference image while conditioning on object poses from the target frame. This enables learning disentangled appearance and pose features. Combining visual and 3D pose representations in a sequence-of-tokens format allows us to keep the text-to-image architecture of existing models, with Neural Assets in place of text tokens. By fine-tuning a pre-trained text-to-image diffusion model with this information, our approach enables fine-grained 3D pose and placement control of individual objects in a scene. We further demonstrate that Neural Assets can be transferred and recomposed across different scenes. Our model achieves state-of-the-art multi-object editing results on both synthetic 3D scene datasets, as well as two real-world video datasets (Objectron, Waymo Open).
SPAD : Spatially Aware Multiview Diffusers
Feb 07, 2024

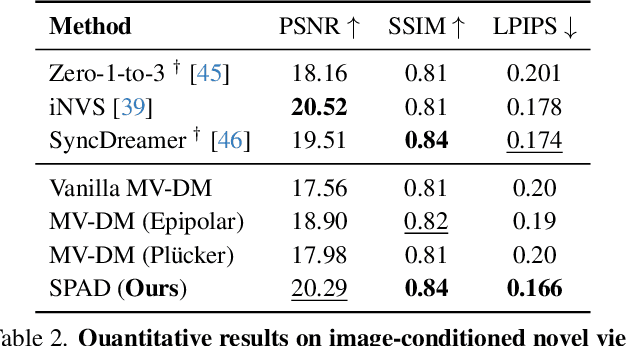

We present SPAD, a novel approach for creating consistent multi-view images from text prompts or single images. To enable multi-view generation, we repurpose a pretrained 2D diffusion model by extending its self-attention layers with cross-view interactions, and fine-tune it on a high quality subset of Objaverse. We find that a naive extension of the self-attention proposed in prior work (e.g. MVDream) leads to content copying between views. Therefore, we explicitly constrain the cross-view attention based on epipolar geometry. To further enhance 3D consistency, we utilize Plucker coordinates derived from camera rays and inject them as positional encoding. This enables SPAD to reason over spatial proximity in 3D well. In contrast to recent works that can only generate views at fixed azimuth and elevation, SPAD offers full camera control and achieves state-of-the-art results in novel view synthesis on unseen objects from the Objaverse and Google Scanned Objects datasets. Finally, we demonstrate that text-to-3D generation using SPAD prevents the multi-face Janus issue. See more details at our webpage: https://yashkant.github.io/spad
LEOD: Label-Efficient Object Detection for Event Cameras
Nov 29, 2023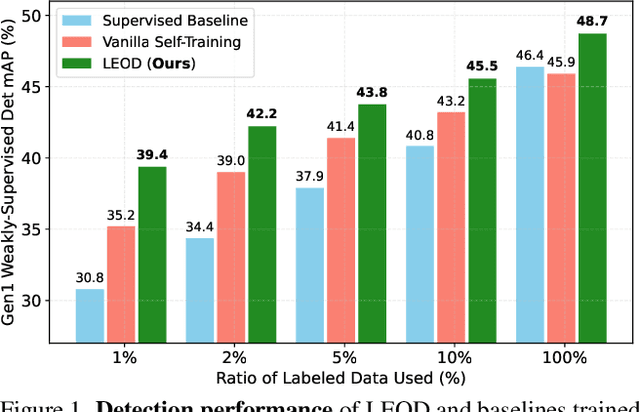
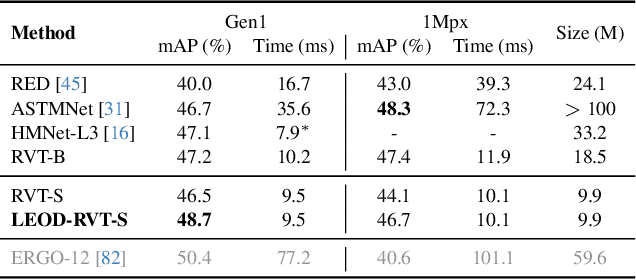
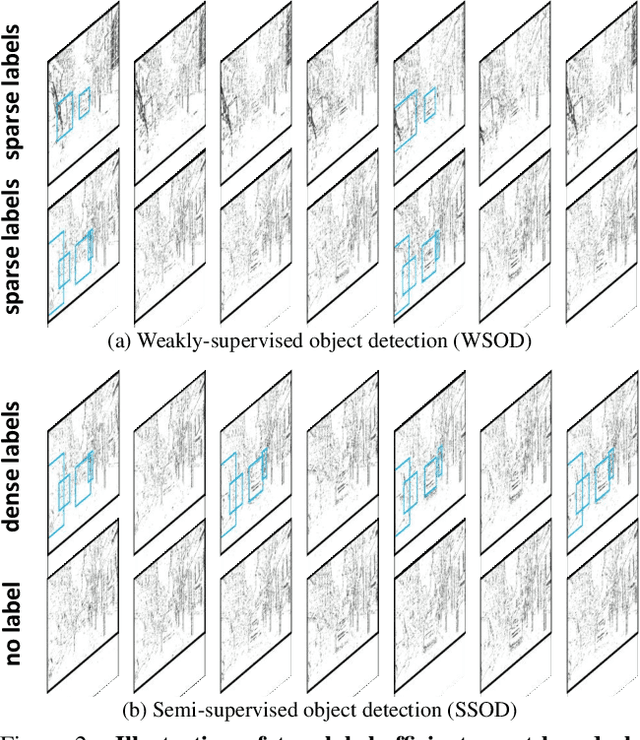
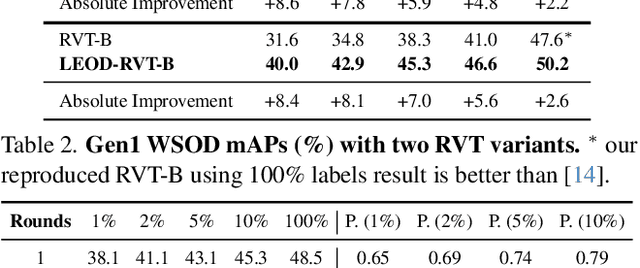
Object detection with event cameras enjoys the property of low latency and high dynamic range, making it suitable for safety-critical scenarios such as self-driving. However, labeling event streams with high temporal resolutions for supervised training is costly. We address this issue with LEOD, the first framework for label-efficient event-based detection. Our method unifies weakly- and semi-supervised object detection with a self-training mechanism. We first utilize a detector pre-trained on limited labels to produce pseudo ground truth on unlabeled events, and then re-train the detector with both real and generated labels. Leveraging the temporal consistency of events, we run bi-directional inference and apply tracking-based post-processing to enhance the quality of pseudo labels. To stabilize training, we further design a soft anchor assignment strategy to mitigate the noise in labels. We introduce new experimental protocols to evaluate the task of label-efficient event-based detection on Gen1 and 1Mpx datasets. LEOD consistently outperforms supervised baselines across various labeling ratios. For example, on Gen1, it improves mAP by 8.6% and 7.8% for RVT-S trained with 1% and 2% labels. On 1Mpx, RVT-S with 10% labels even surpasses its fully-supervised counterpart using 100% labels. LEOD maintains its effectiveness even when all labeled data are available, reaching new state-of-the-art results. Finally, we show that our method readily scales to improve larger detectors as well.
EventCLIP: Adapting CLIP for Event-based Object Recognition
Jun 10, 2023



Recent advances in 2D zero-shot and few-shot recognition often leverage large pre-trained vision-language models (VLMs) such as CLIP. Due to a shortage of suitable datasets, it is currently infeasible to train such models for event camera data. Thus, leveraging existing models across modalities is an important research challenge. In this work, we propose EventCLIP, a new method that utilizes CLIP for zero-shot and few-shot recognition on event camera data. First, we demonstrate the suitability of CLIP's image embeddings for zero-shot event classification by converting raw events to 2D grid-based representations. Second, we propose a feature adapter that aggregates temporal information over event frames and refines text embeddings to better align with the visual inputs. We evaluate our work on N-Caltech, N-Cars, and N-ImageNet datasets under the few-shot learning setting, where EventCLIP achieves state-of-the-art performance. Finally, we show that the robustness of existing event-based classifiers against data variations can be further boosted by ensembling with EventCLIP.