 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFOMO-3D: Using Vision Foundation Models for Long-Tailed 3D Object Detection
Mar 09, 2026In order to navigate complex traffic environments, self-driving vehicles must recognize many semantic classes pertaining to vulnerable road users or traffic control devices. However, many safety-critical objects (e.g., construction worker) appear infrequently in nominal traffic conditions, leading to a severe shortage of training examples from driving data alone. Recent vision foundation models, which are trained on a large corpus of data, can serve as a good source of external prior knowledge to improve generalization. We propose FOMO-3D, the first multi-modal 3D detector to leverage vision foundation models for long-tailed 3D detection. Specifically, FOMO-3D exploits rich semantic and depth priors from OWLv2 and Metric3Dv2 within a two-stage detection paradigm that first generates proposals with a LiDAR-based branch and a novel camera-based branch, and refines them with attention especially to image features from OWL. Evaluations on real-world driving data show that using rich priors from vision foundation models with careful multi-modal fusion designs leads to large gains for long-tailed 3D detection. Project website is at https://waabi.ai/fomo3d/.
Extreme Model Compression with Structured Sparsity at Low Precision
Nov 11, 2025Deep neural networks (DNNs) are used in many applications, but their large size and high computational cost make them hard to run on devices with limited resources. Two widely used techniques to address this challenge are weight quantization, which lowers the precision of all weights, and structured sparsity, which removes unimportant weights while retaining the important ones at full precision. Although both are effective individually, they are typically studied in isolation due to their compounded negative impact on model accuracy when combined. In this work, we introduce SLOPE Structured Sparsity at Low Precision), a unified framework, to effectively combine structured sparsity and low-bit quantization in a principled way. We show that naively combining sparsity and quantization severely harms performance due to the compounded impact of both techniques. To address this, we propose a training-time regularization strategy that minimizes the discrepancy between full-precision weights and their sparse, quantized counterparts by promoting angular alignment rather than direct matching. On ResNet-18, SLOPE achieves $\sim20\times$ model size reduction while retaining $\sim$99% of the original accuracy. It consistently outperforms state-of-the-art quantization and structured sparsity methods across classification, detection, and segmentation tasks on models such as ResNet-18, ViT-Small, and Mask R-CNN.
LabelFormer: Object Trajectory Refinement for Offboard Perception from LiDAR Point Clouds
Nov 02, 2023



A major bottleneck to scaling-up training of self-driving perception systems are the human annotations required for supervision. A promising alternative is to leverage "auto-labelling" offboard perception models that are trained to automatically generate annotations from raw LiDAR point clouds at a fraction of the cost. Auto-labels are most commonly generated via a two-stage approach -- first objects are detected and tracked over time, and then each object trajectory is passed to a learned refinement model to improve accuracy. Since existing refinement models are overly complex and lack advanced temporal reasoning capabilities, in this work we propose LabelFormer, a simple, efficient, and effective trajectory-level refinement approach. Our approach first encodes each frame's observations separately, then exploits self-attention to reason about the trajectory with full temporal context, and finally decodes the refined object size and per-frame poses. Evaluation on both urban and highway datasets demonstrates that LabelFormer outperforms existing works by a large margin. Finally, we show that training on a dataset augmented with auto-labels generated by our method leads to improved downstream detection performance compared to existing methods. Please visit the project website for details https://waabi.ai/labelformer
* 20 pages, 8 figures, 7 tables
GePSAn: Generative Procedure Step Anticipation in Cooking Videos
Oct 12, 2023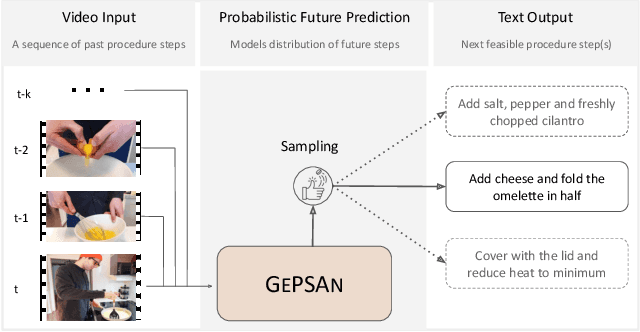
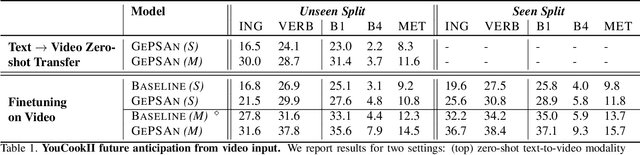
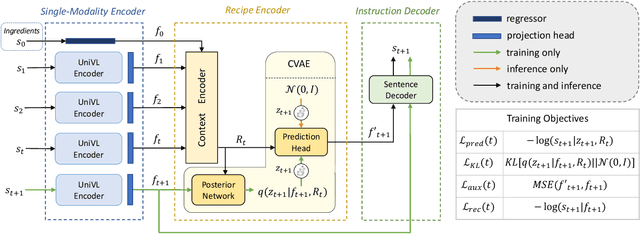
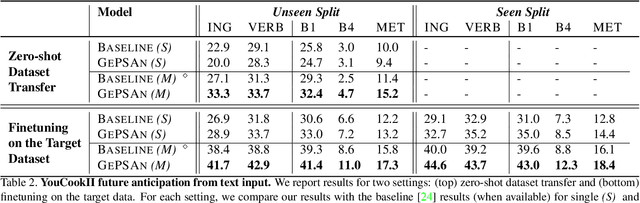
We study the problem of future step anticipation in procedural videos. Given a video of an ongoing procedural activity, we predict a plausible next procedure step described in rich natural language. While most previous work focus on the problem of data scarcity in procedural video datasets, another core challenge of future anticipation is how to account for multiple plausible future realizations in natural settings. This problem has been largely overlooked in previous work. To address this challenge, we frame future step prediction as modelling the distribution of all possible candidates for the next step. Specifically, we design a generative model that takes a series of video clips as input, and generates multiple plausible and diverse candidates (in natural language) for the next step. Following previous work, we side-step the video annotation scarcity by pretraining our model on a large text-based corpus of procedural activities, and then transfer the model to the video domain. Our experiments, both in textual and video domains, show that our model captures diversity in the next step prediction and generates multiple plausible future predictions. Moreover, our model establishes new state-of-the-art results on YouCookII, where it outperforms existing baselines on the next step anticipation. Finally, we also show that our model can successfully transfer from text to the video domain zero-shot, ie, without fine-tuning or adaptation, and produces good-quality future step predictions from video.
Self-Supervised Learning of Action Affordances as Interaction Modes
May 27, 2023When humans perform a task with an articulated object, they interact with the object only in a handful of ways, while the space of all possible interactions is nearly endless. This is because humans have prior knowledge about what interactions are likely to be successful, i.e., to open a new door we first try the handle. While learning such priors without supervision is easy for humans, it is notoriously hard for machines. In this work, we tackle unsupervised learning of priors of useful interactions with articulated objects, which we call interaction modes. In contrast to the prior art, we use no supervision or privileged information; we only assume access to the depth sensor in the simulator to learn the interaction modes. More precisely, we define a successful interaction as the one changing the visual environment substantially and learn a generative model of such interactions, that can be conditioned on the desired goal state of the object. In our experiments, we show that our model covers most of the human interaction modes, outperforms existing state-of-the-art methods for affordance learning, and can generalize to objects never seen during training. Additionally, we show promising results in the goal-conditional setup, where our model can be quickly fine-tuned to perform a given task. We show in the experiments that such affordance learning predicts interaction which covers most modes of interaction for the querying articulated object and can be fine-tuned to a goal-conditional model. For supplementary: https://actaim.github.io.
StepFormer: Self-supervised Step Discovery and Localization in Instructional Videos
Apr 26, 2023



Instructional videos are an important resource to learn procedural tasks from human demonstrations. However, the instruction steps in such videos are typically short and sparse, with most of the video being irrelevant to the procedure. This motivates the need to temporally localize the instruction steps in such videos, i.e. the task called key-step localization. Traditional methods for key-step localization require video-level human annotations and thus do not scale to large datasets. In this work, we tackle the problem with no human supervision and introduce StepFormer, a self-supervised model that discovers and localizes instruction steps in a video. StepFormer is a transformer decoder that attends to the video with learnable queries, and produces a sequence of slots capturing the key-steps in the video. We train our system on a large dataset of instructional videos, using their automatically-generated subtitles as the only source of supervision. In particular, we supervise our system with a sequence of text narrations using an order-aware loss function that filters out irrelevant phrases. We show that our model outperforms all previous unsupervised and weakly-supervised approaches on step detection and localization by a large margin on three challenging benchmarks. Moreover, our model demonstrates an emergent property to solve zero-shot multi-step localization and outperforms all relevant baselines at this task.
SAGE: Saliency-Guided Mixup with Optimal Rearrangements
Oct 31, 2022



Data augmentation is a key element for training accurate models by reducing overfitting and improving generalization. For image classification, the most popular data augmentation techniques range from simple photometric and geometrical transformations, to more complex methods that use visual saliency to craft new training examples. As augmentation methods get more complex, their ability to increase the test accuracy improves, yet, such methods become cumbersome, inefficient and lead to poor out-of-domain generalization, as we show in this paper. This motivates a new augmentation technique that allows for high accuracy gains while being simple, efficient (i.e., minimal computation overhead) and generalizable. To this end, we introduce Saliency-Guided Mixup with Optimal Rearrangements (SAGE), which creates new training examples by rearranging and mixing image pairs using visual saliency as guidance. By explicitly leveraging saliency, SAGE promotes discriminative foreground objects and produces informative new images useful for training. We demonstrate on CIFAR-10 and CIFAR-100 that SAGE achieves better or comparable performance to the state of the art while being more efficient. Additionally, evaluations in the out-of-distribution setting, and few-shot learning on mini-ImageNet, show that SAGE achieves improved generalization performance without trading off robustness.
SlotFormer: Unsupervised Visual Dynamics Simulation with Object-Centric Models
Oct 12, 2022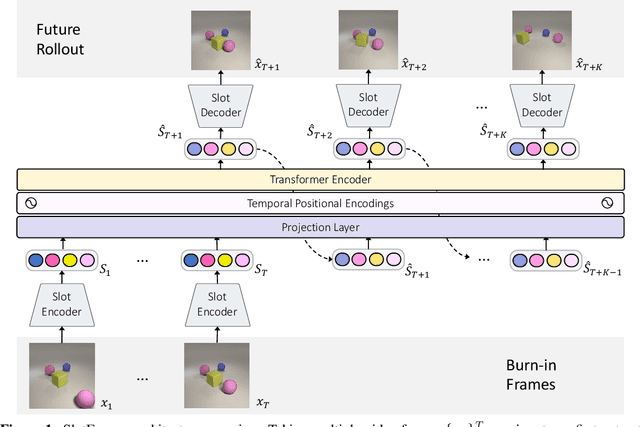
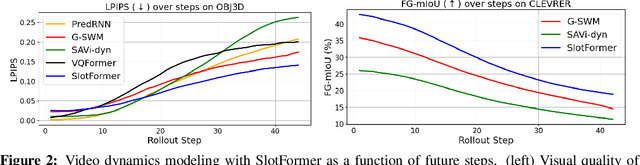
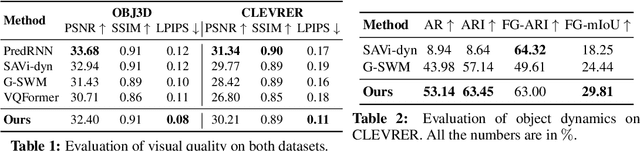
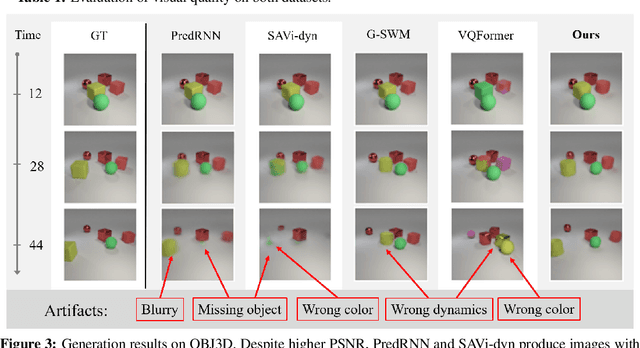
Understanding dynamics from visual observations is a challenging problem that requires disentangling individual objects from the scene and learning their interactions. While recent object-centric models can successfully decompose a scene into objects, modeling their dynamics effectively still remains a challenge. We address this problem by introducing SlotFormer -- a Transformer-based autoregressive model operating on learned object-centric representations. Given a video clip, our approach reasons over object features to model spatio-temporal relationships and predicts accurate future object states. In this paper, we successfully apply SlotFormer to perform video prediction on datasets with complex object interactions. Moreover, the unsupervised SlotFormer's dynamics model can be used to improve the performance on supervised downstream tasks, such as Visual Question Answering (VQA), and goal-conditioned planning. Compared to past works on dynamics modeling, our method achieves significantly better long-term synthesis of object dynamics, while retaining high quality visual generation. Besides, SlotFormer enables VQA models to reason about the future without object-level labels, even outperforming counterparts that use ground-truth annotations. Finally, we show its ability to serve as a world model for model-based planning, which is competitive with methods designed specifically for such tasks.
Graph2Vid: Flow graph to Video Grounding forWeakly-supervised Multi-Step Localization
Oct 10, 2022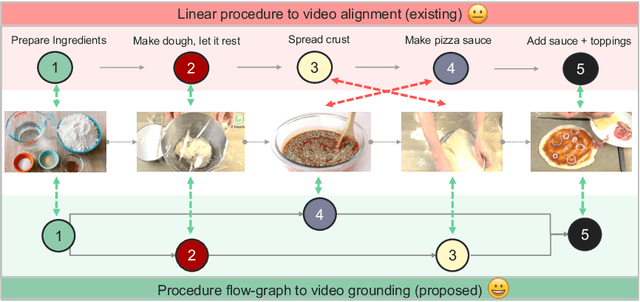
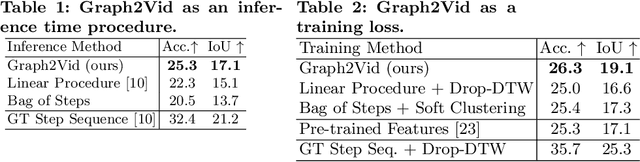

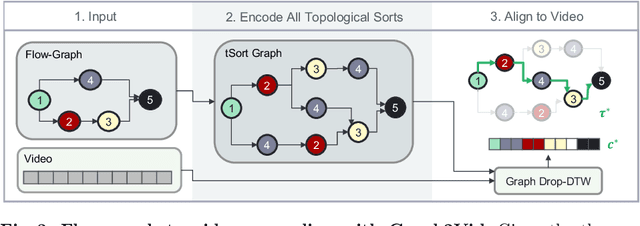
In this work, we consider the problem of weakly-supervised multi-step localization in instructional videos. An established approach to this problem is to rely on a given list of steps. However, in reality, there is often more than one way to execute a procedure successfully, by following the set of steps in slightly varying orders. Thus, for successful localization in a given video, recent works require the actual order of procedure steps in the video, to be provided by human annotators at both training and test times. Instead, here, we only rely on generic procedural text that is not tied to a specific video. We represent the various ways to complete the procedure by transforming the list of instructions into a procedure flow graph which captures the partial order of steps. Using the flow graphs reduces both training and test time annotation requirements. To this end, we introduce the new problem of flow graph to video grounding. In this setup, we seek the optimal step ordering consistent with the procedure flow graph and a given video. To solve this problem, we propose a new algorithm - Graph2Vid - that infers the actual ordering of steps in the video and simultaneously localizes them. To show the advantage of our proposed formulation, we extend the CrossTask dataset with procedure flow graph information. Our experiments show that Graph2Vid is both more efficient than the baselines and yields strong step localization results, without the need for step order annotation.
* ECCV'22, oral
P3IV: Probabilistic Procedure Planning from Instructional Videos with Weak Supervision
May 04, 2022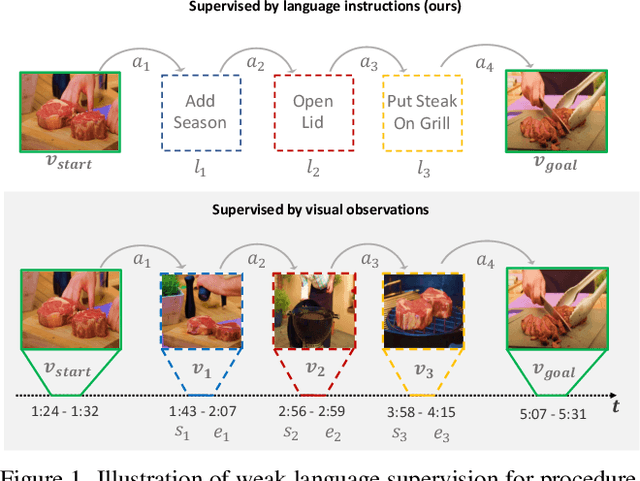
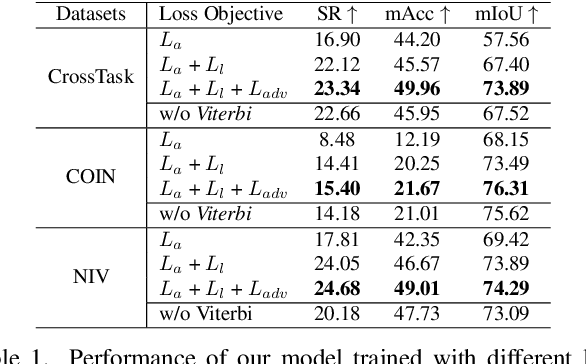
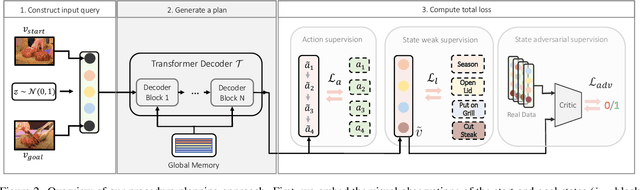
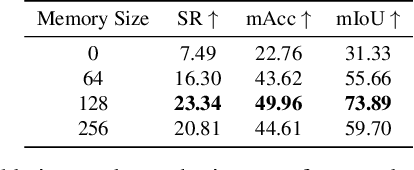
In this paper, we study the problem of procedure planning in instructional videos. Here, an agent must produce a plausible sequence of actions that can transform the environment from a given start to a desired goal state. When learning procedure planning from instructional videos, most recent work leverages intermediate visual observations as supervision, which requires expensive annotation efforts to localize precisely all the instructional steps in training videos. In contrast, we remove the need for expensive temporal video annotations and propose a weakly supervised approach by learning from natural language instructions. Our model is based on a transformer equipped with a memory module, which maps the start and goal observations to a sequence of plausible actions. Furthermore, we augment our model with a probabilistic generative module to capture the uncertainty inherent to procedure planning, an aspect largely overlooked by previous work. We evaluate our model on three datasets and show our weaklysupervised approach outperforms previous fully supervised state-of-the-art models on multiple metrics.