 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBurstGP: Enhancing Raw Burst Image Super Resolution with Generative Priors
Apr 26, 2026Burst image super resolution (BISR) aims to construct a single high-resolution (HR) image by aggregating information from multiple low-resolution (LR) frames, relying on temporal redundancy and spatial coherence across the burst. While conventional methods achieve impressive results, they often struggle with complex textures and oversmoothing. Diffusion models, particularly those pretrained on high-quality data, have shown remarkable capability in generating realistic details for image and video super-resolution. However, their potential remains largely under-explored in BISR, where existing approaches typically rely on task-specific diffusion models trained from scratch and operate on single-frame reconstructions. In this work, we propose BurstGP, a novel diffusion-based solution for BISR, which leverages generative priors of recent foundation models to overcome these issues. In particular, we build a multiframe-aware diffusion model on top of a conventional BISR approach, which boosts image quality with minimal loss to fidelity. Further, we introduce (i) a novel degradation-aware conditioning mechanism, which controls synthesis of fine details based on the estimated degradation in the input, and (ii) a robust sRGB-to-lRGB inverter, enabling us to utilize generative multiframe (video) sRGB priors, while operating with raw input and lRGB output images. Empirically, we demonstrate that BurstGP outperforms the existing state of the art, both quantitatively (especially with respect to perceptual metrics, including MUSIQ and LPIPS) and qualitatively. In particular, our proposed method excels at recovering richer textures and finer structural details, highlighting the potential of video priors for BISR over traditional methods.
Augmenting Perceptual Super-Resolution via Image Quality Predictors
Apr 25, 2025



Super-resolution (SR), a classical inverse problem in computer vision, is inherently ill-posed, inducing a distribution of plausible solutions for every input. However, the desired result is not simply the expectation of this distribution, which is the blurry image obtained by minimizing pixelwise error, but rather the sample with the highest image quality. A variety of techniques, from perceptual metrics to adversarial losses, are employed to this end. In this work, we explore an alternative: utilizing powerful non-reference image quality assessment (NR-IQA) models in the SR context. We begin with a comprehensive analysis of NR-IQA metrics on human-derived SR data, identifying both the accuracy (human alignment) and complementarity of different metrics. Then, we explore two methods of applying NR-IQA models to SR learning: (i) altering data sampling, by building on an existing multi-ground-truth SR framework, and (ii) directly optimizing a differentiable quality score. Our results demonstrate a more human-centric perception-distortion tradeoff, focusing less on non-perceptual pixel-wise distortion, instead improving the balance between perceptual fidelity and human-tuned NR-IQA measures.
GePSAn: Generative Procedure Step Anticipation in Cooking Videos
Oct 12, 2023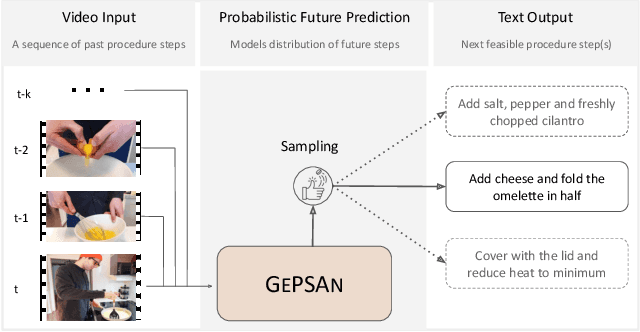
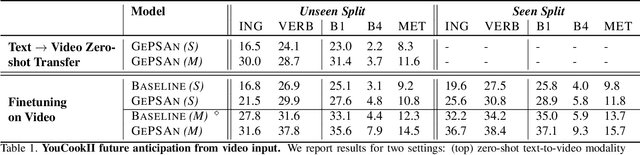
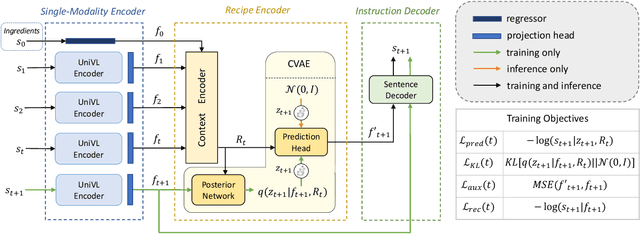
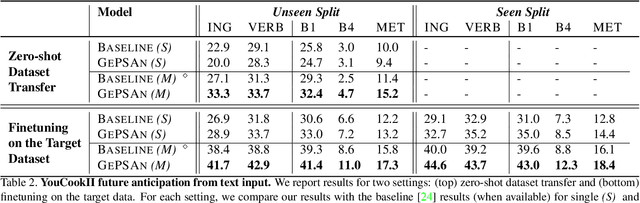
We study the problem of future step anticipation in procedural videos. Given a video of an ongoing procedural activity, we predict a plausible next procedure step described in rich natural language. While most previous work focus on the problem of data scarcity in procedural video datasets, another core challenge of future anticipation is how to account for multiple plausible future realizations in natural settings. This problem has been largely overlooked in previous work. To address this challenge, we frame future step prediction as modelling the distribution of all possible candidates for the next step. Specifically, we design a generative model that takes a series of video clips as input, and generates multiple plausible and diverse candidates (in natural language) for the next step. Following previous work, we side-step the video annotation scarcity by pretraining our model on a large text-based corpus of procedural activities, and then transfer the model to the video domain. Our experiments, both in textual and video domains, show that our model captures diversity in the next step prediction and generates multiple plausible future predictions. Moreover, our model establishes new state-of-the-art results on YouCookII, where it outperforms existing baselines on the next step anticipation. Finally, we also show that our model can successfully transfer from text to the video domain zero-shot, ie, without fine-tuning or adaptation, and produces good-quality future step predictions from video.
Few-shot Learning with Noisy Labels
Apr 12, 2022
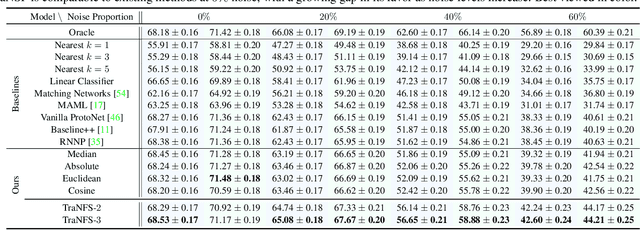
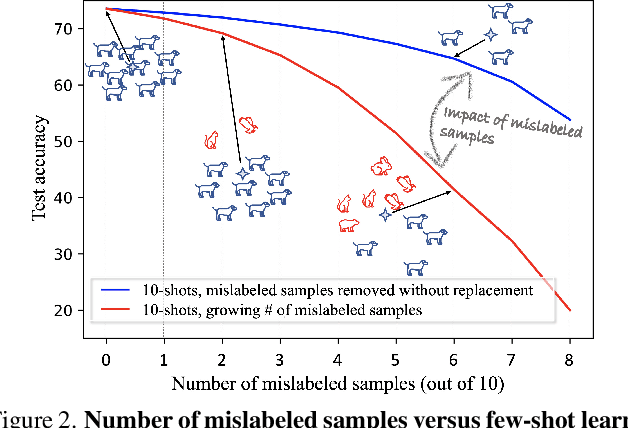

Few-shot learning (FSL) methods typically assume clean support sets with accurately labeled samples when training on novel classes. This assumption can often be unrealistic: support sets, no matter how small, can still include mislabeled samples. Robustness to label noise is therefore essential for FSL methods to be practical, but this problem surprisingly remains largely unexplored. To address mislabeled samples in FSL settings, we make several technical contributions. (1) We offer simple, yet effective, feature aggregation methods, improving the prototypes used by ProtoNet, a popular FSL technique. (2) We describe a novel Transformer model for Noisy Few-Shot Learning (TraNFS). TraNFS leverages a transformer's attention mechanism to weigh mislabeled versus correct samples. (3) Finally, we extensively test these methods on noisy versions of MiniImageNet and TieredImageNet. Our results show that TraNFS is on-par with leading FSL methods on clean support sets, yet outperforms them, by far, in the presence of label noise.
Consistency driven Sequential Transformers Attention Model for Partially Observable Scenes
Apr 01, 2022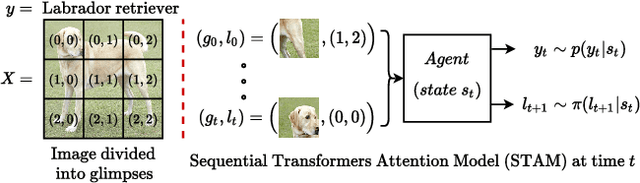
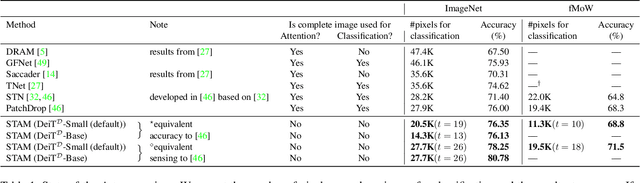
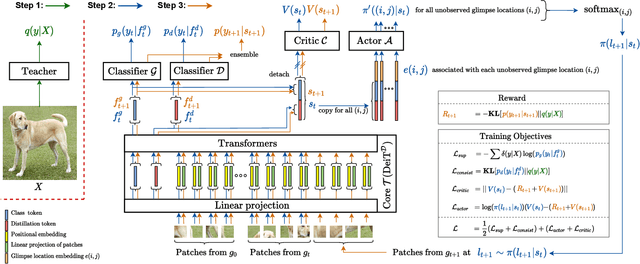
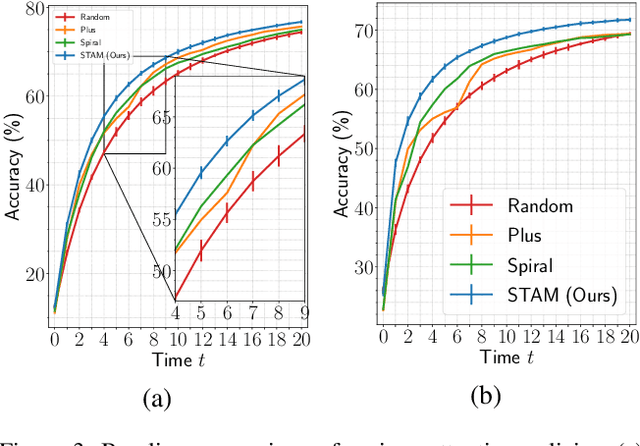
Most hard attention models initially observe a complete scene to locate and sense informative glimpses, and predict class-label of a scene based on glimpses. However, in many applications (e.g., aerial imaging), observing an entire scene is not always feasible due to the limited time and resources available for acquisition. In this paper, we develop a Sequential Transformers Attention Model (STAM) that only partially observes a complete image and predicts informative glimpse locations solely based on past glimpses. We design our agent using DeiT-distilled and train it with a one-step actor-critic algorithm. Furthermore, to improve classification performance, we introduce a novel training objective, which enforces consistency between the class distribution predicted by a teacher model from a complete image and the class distribution predicted by our agent using glimpses. When the agent senses only 4% of the total image area, the inclusion of the proposed consistency loss in our training objective yields 3% and 8% higher accuracy on ImageNet and fMoW datasets, respectively. Moreover, our agent outperforms previous state-of-the-art by observing nearly 27% and 42% fewer pixels in glimpses on ImageNet and fMoW.
A Probabilistic Hard Attention Model For Sequentially Observed Scenes
Nov 15, 2021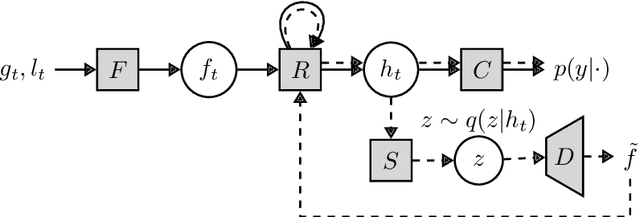
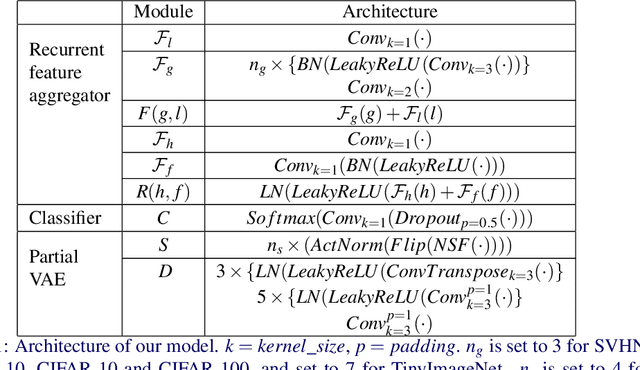
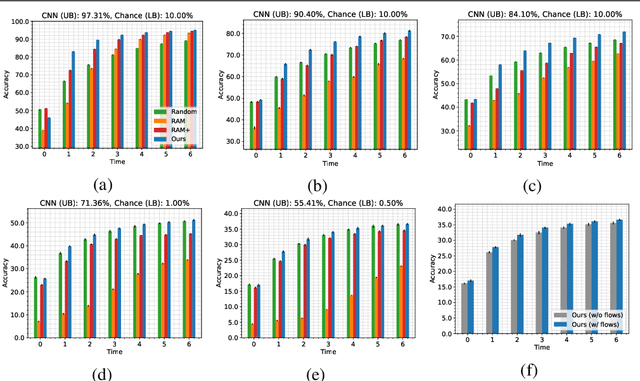
A visual hard attention model actively selects and observes a sequence of subregions in an image to make a prediction. The majority of hard attention models determine the attention-worthy regions by first analyzing a complete image. However, it may be the case that the entire image is not available initially but instead sensed gradually through a series of partial observations. In this paper, we design an efficient hard attention model for classifying such sequentially observed scenes. The presented model never observes an image completely. To select informative regions under partial observability, the model uses Bayesian Optimal Experiment Design. First, it synthesizes the features of the unobserved regions based on the already observed regions. Then, it uses the predicted features to estimate the expected information gain (EIG) attained, should various regions be attended. Finally, the model attends to the actual content on the location where the EIG mentioned above is maximum. The model uses a) a recurrent feature aggregator to maintain a recurrent state, b) a linear classifier to predict the class label, c) a Partial variational autoencoder to predict the features of unobserved regions. We use normalizing flows in Partial VAE to handle multi-modality in the feature-synthesis problem. We train our model using a differentiable objective and test it on five datasets. Our model gains 2-10% higher accuracy than the baseline models when both have seen only a couple of glimpses.
Visual Attention in Imaginative Agents
Apr 01, 2021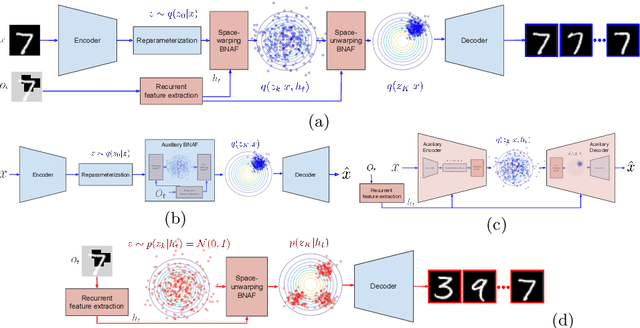

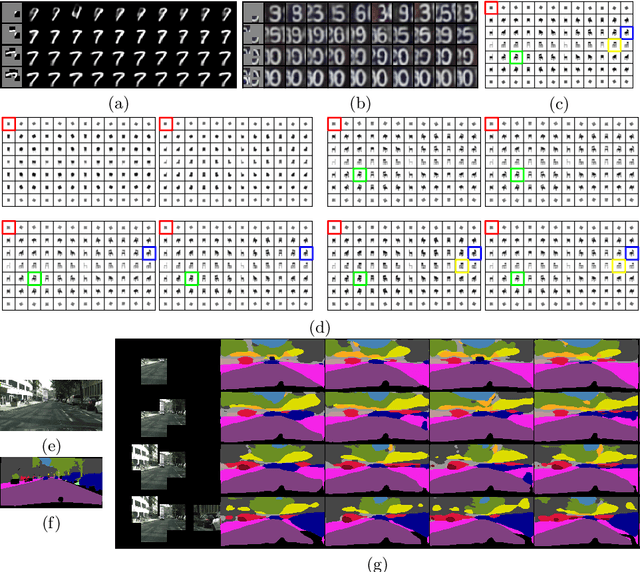
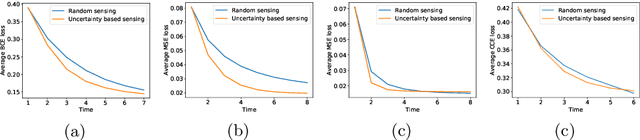
We present a recurrent agent who perceives surroundings through a series of discrete fixations. At each timestep, the agent imagines a variety of plausible scenes consistent with the fixation history. The next fixation is planned using uncertainty in the content of the imagined scenes. As time progresses, the agent becomes more certain about the content of the surrounding, and the variety in the imagined scenes reduces. The agent is built using a variational autoencoder and normalizing flows, and trained in an unsupervised manner on a proxy task of scene-reconstruction. The latent representations of the imagined scenes are found to be useful for performing pixel-level and scene-level tasks by higher-order modules. The agent is tested on various 2D and 3D datasets.