 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Radiance and Gaze Fields for Visual Attention Modeling in 3D Environments
Mar 10, 2025



We introduce Neural Radiance and Gaze Fields (NeRGs) as a novel approach for representing visual attention patterns in 3D scenes. Our system renders a 2D view of a 3D scene with a pre-trained Neural Radiance Field (NeRF) and visualizes the gaze field for arbitrary observer positions, which may be decoupled from the render camera perspective. We achieve this by augmenting a standard NeRF with an additional neural network that models the gaze probability distribution. The output of a NeRG is a rendered image of the scene viewed from the camera perspective and a pixel-wise salience map representing conditional probability that an observer fixates on a given surface within the 3D scene as visible in the rendered image. Much like how NeRFs perform novel view synthesis, NeRGs enable the reconstruction of gaze patterns from arbitrary perspectives within complex 3D scenes. To ensure consistent gaze reconstructions, we constrain gaze prediction on the 3D structure of the scene and model gaze occlusion due to intervening surfaces when the observer's viewpoint is decoupled from the rendering camera. For training, we leverage ground truth head pose data from skeleton tracking data or predictions from 2D salience models. We demonstrate the effectiveness of NeRGs in a real-world convenience store setting, where head pose tracking data is available.
SEMU-Net: A Segmentation-based Corrector for Fabrication Process Variations of Nanophotonics with Microscopic Images
Nov 25, 2024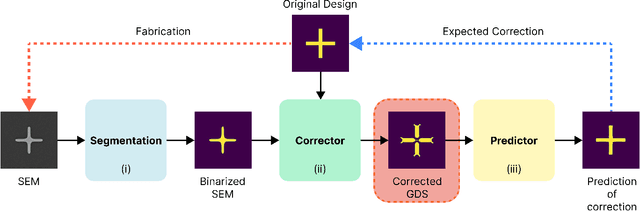
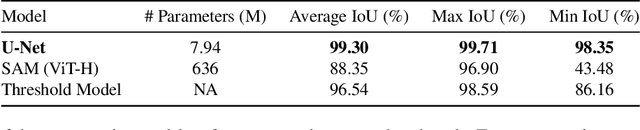
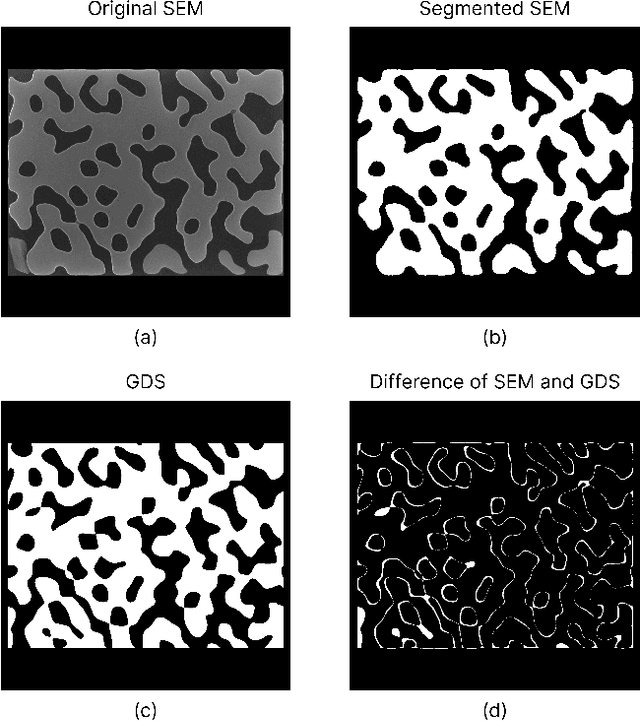
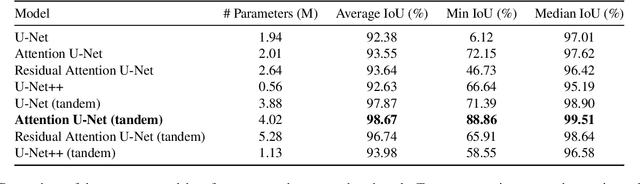
Integrated silicon photonic devices, which manipulate light to transmit and process information on a silicon-on-insulator chip, are highly sensitive to structural variations. Minor deviations during nanofabrication-the precise process of building structures at the nanometer scale-such as over- or under-etching, corner rounding, and unintended defects, can significantly impact performance. To address these challenges, we introduce SEMU-Net, a comprehensive set of methods that automatically segments scanning electron microscope images (SEM) and uses them to train two deep neural network models based on U-Net and its variants. The predictor model anticipates fabrication-induced variations, while the corrector model adjusts the design to address these issues, ensuring that the final fabricated structures closely align with the intended specifications. Experimental results show that the segmentation U-Net reaches an average IoU score of 99.30%, while the corrector attention U-Net in a tandem architecture achieves an average IoU score of 98.67%.
Decoupling Training-Free Guided Diffusion by ADMM
Nov 18, 2024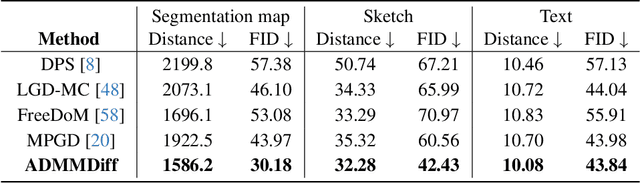
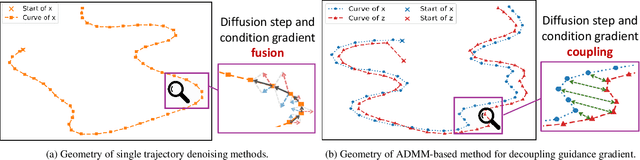


In this paper, we consider the conditional generation problem by guiding off-the-shelf unconditional diffusion models with differentiable loss functions in a plug-and-play fashion. While previous research has primarily focused on balancing the unconditional diffusion model and the guided loss through a tuned weight hyperparameter, we propose a novel framework that distinctly decouples these two components. Specifically, we introduce two variables ${x}$ and ${z}$, to represent the generated samples governed by the unconditional generation model and the guidance function, respectively. This decoupling reformulates conditional generation into two manageable subproblems, unified by the constraint ${x} = {z}$. Leveraging this setup, we develop a new algorithm based on the Alternating Direction Method of Multipliers (ADMM) to adaptively balance these components. Additionally, we establish the equivalence between the diffusion reverse step and the proximal operator of ADMM and provide a detailed convergence analysis of our algorithm under certain mild assumptions. Our experiments demonstrate that our proposed method ADMMDiff consistently generates high-quality samples while ensuring strong adherence to the conditioning criteria. It outperforms existing methods across a range of conditional generation tasks, including image generation with various guidance and controllable motion synthesis.
Automatic Pruning of Fine-tuning Datasets for Transformer-based Language Models
Jul 11, 2024Transformer-based language models have shown state-of-the-art performance on a variety of natural language understanding tasks. To achieve this performance, these models are first pre-trained on general corpus and then fine-tuned on downstream tasks. Previous work studied the effect of pruning the training set of the downstream tasks on the performance of the model on its evaluation set. In this work, we propose an automatic dataset pruning method for the training set of fine-tuning tasks. Our method is based on the model's success rate in correctly classifying each training data point. Unlike previous work which relies on user feedback to determine subset size, our method automatically extracts training subsets that are adapted for each pair of model and fine-tuning task. Our method provides multiple subsets for use in dataset pruning that navigate the trade-off between subset size and evaluation accuracy. Our largest subset, which we also refer to as the winning ticket subset, is on average $3 \times$ smaller than the original training set of the fine-tuning task. Our experiments on 5 downstream tasks and 2 language models show that, on average, fine-tuning on the winning ticket subsets results in a $0.1 \%$ increase in the evaluation performance of the model.
Design Editing for Offline Model-based Optimization
May 22, 2024



Offline model-based optimization (MBO) aims to maximize a black-box objective function using only an offline dataset of designs and scores. A prevalent approach involves training a conditional generative model on existing designs and their associated scores, followed by the generation of new designs conditioned on higher target scores. However, these newly generated designs often underperform due to the lack of high-scoring training data. To address this challenge, we introduce a novel method, Design Editing for Offline Model-based Optimization (DEMO), which consists of two phases. In the first phase, termed pseudo-target distribution generation, we apply gradient ascent on the offline dataset using a trained surrogate model, producing a synthetic dataset where the predicted scores serve as new labels. A conditional diffusion model is subsequently trained on this synthetic dataset to capture a pseudo-target distribution, which enhances the accuracy of the conditional diffusion model in generating higher-scoring designs. Nevertheless, the pseudo-target distribution is susceptible to noise stemming from inaccuracies in the surrogate model, consequently predisposing the conditional diffusion model to generate suboptimal designs. We hence propose the second phase, existing design editing, to directly incorporate the high-scoring features from the offline dataset into design generation. In this phase, top designs from the offline dataset are edited by introducing noise, which are subsequently refined using the conditional diffusion model to produce high-scoring designs. Overall, high-scoring designs begin with inheriting high-scoring features from the second phase and are further refined with a more accurate conditional diffusion model in the first phase. Empirical evaluations on 7 offline MBO tasks show that DEMO outperforms various baseline methods.
FastVideoEdit: Leveraging Consistency Models for Efficient Text-to-Video Editing
Mar 10, 2024



Diffusion models have demonstrated remarkable capabilities in text-to-image and text-to-video generation, opening up possibilities for video editing based on textual input. However, the computational cost associated with sequential sampling in diffusion models poses challenges for efficient video editing. Existing approaches relying on image generation models for video editing suffer from time-consuming one-shot fine-tuning, additional condition extraction, or DDIM inversion, making real-time applications impractical. In this work, we propose FastVideoEdit, an efficient zero-shot video editing approach inspired by Consistency Models (CMs). By leveraging the self-consistency property of CMs, we eliminate the need for time-consuming inversion or additional condition extraction, reducing editing time. Our method enables direct mapping from source video to target video with strong preservation ability utilizing a special variance schedule. This results in improved speed advantages, as fewer sampling steps can be used while maintaining comparable generation quality. Experimental results validate the state-of-the-art performance and speed advantages of FastVideoEdit across evaluation metrics encompassing editing speed, temporal consistency, and text-video alignment.
Faster Inference of Integer SWIN Transformer by Removing the GELU Activation
Feb 02, 2024SWIN transformer is a prominent vision transformer model that has state-of-the-art accuracy in image classification tasks. Despite this success, its unique architecture causes slower inference compared with similar deep neural networks. Integer quantization of the model is one of the methods used to improve its inference latency. However, state-of-the-art has not been able to fully quantize the model. In this work, we improve upon the inference latency of the state-of-the-art methods by removing the floating-point operations, which are associated with the GELU activation in Swin Transformer. While previous work proposed to replace the non-integer operations with linear approximation functions, we propose to replace GELU with ReLU activation. The advantage of ReLU over previous methods is its low memory and computation complexity. We use iterative knowledge distillation to compensate for the lost accuracy due to replacing GELU with ReLU. We quantize our GELU-less SWIN transformer and show that on an RTX 4090 NVIDIA GPU we can improve the inference latency of the quantized SWIN transformer by at least $11\%$ while maintaining an accuracy drop of under $0.5\%$ on the ImageNet evaluation dataset.
AdCorDA: Classifier Refinement via Adversarial Correction and Domain Adaptation
Jan 24, 2024This paper describes a simple yet effective technique for refining a pretrained classifier network. The proposed AdCorDA method is based on modification of the training set and making use of the duality between network weights and layer inputs. We call this input space training. The method consists of two stages - adversarial correction followed by domain adaptation. Adversarial correction uses adversarial attacks to correct incorrect training-set classifications. The incorrectly classified samples of the training set are removed and replaced with the adversarially corrected samples to form a new training set, and then, in the second stage, domain adaptation is performed back to the original training set. Extensive experimental validations show significant accuracy boosts of over 5% on the CIFAR-100 dataset. The technique can be straightforwardly applied to refinement of weight-quantized neural networks, where experiments show substantial enhancement in performance over the baseline. The adversarial correction technique also results in enhanced robustness to adversarial attacks.
Robustness to distribution shifts of compressed networks for edge devices
Jan 22, 2024
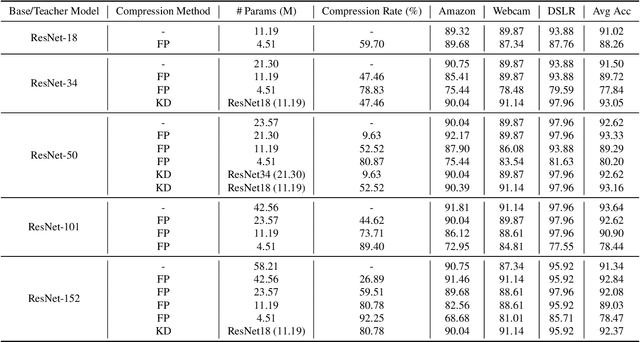

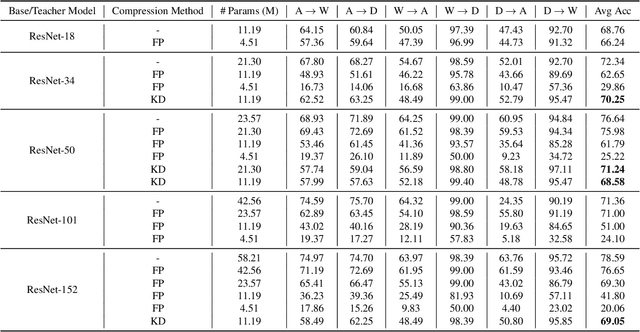
It is necessary to develop efficient DNNs deployed on edge devices with limited computation resources. However, the compressed networks often execute new tasks in the target domain, which is different from the source domain where the original network is trained. It is important to investigate the robustness of compressed networks in two types of data distribution shifts: domain shifts and adversarial perturbations. In this study, we discover that compressed models are less robust to distribution shifts than their original networks. Interestingly, larger networks are more vulnerable to losing robustness than smaller ones, even when they are compressed to a similar size as the smaller networks. Furthermore, compact networks obtained by knowledge distillation are much more robust to distribution shifts than pruned networks. Finally, post-training quantization is a reliable method for achieving significant robustness to distribution shifts, and it outperforms both pruned and distilled models in terms of robustness.
BD-KD: Balancing the Divergences for Online Knowledge Distillation
Dec 25, 2022Knowledge distillation (KD) has gained a lot of attention in the field of model compression for edge devices thanks to its effectiveness in compressing large powerful networks into smaller lower-capacity models. Online distillation, in which both the teacher and the student are learning collaboratively, has also gained much interest due to its ability to improve on the performance of the networks involved. The Kullback-Leibler (KL) divergence ensures the proper knowledge transfer between the teacher and student. However, most online KD techniques present some bottlenecks under the network capacity gap. By cooperatively and simultaneously training, the models the KL distance becomes incapable of properly minimizing the teacher's and student's distributions. Alongside accuracy, critical edge device applications are in need of well-calibrated compact networks. Confidence calibration provides a sensible way of getting trustworthy predictions. We propose BD-KD: Balancing of Divergences for online Knowledge Distillation. We show that adaptively balancing between the reverse and forward divergences shifts the focus of the training strategy to the compact student network without limiting the teacher network's learning process. We demonstrate that, by performing this balancing design at the level of the student distillation loss, we improve upon both performance accuracy and calibration of the compact student network. We conducted extensive experiments using a variety of network architectures and show improvements on multiple datasets including CIFAR-10, CIFAR-100, Tiny-ImageNet, and ImageNet. We illustrate the effectiveness of our approach through comprehensive comparisons and ablations with current state-of-the-art online and offline KD techniques.