 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Local Geometry of Generative Model Manifolds
Aug 15, 2024



Deep generative models learn continuous representations of complex data manifolds using a finite number of samples during training. For a pre-trained generative model, the common way to evaluate the quality of the manifold representation learned, is by computing global metrics like Fr\'echet Inception Distance using a large number of generated and real samples. However, generative model performance is not uniform across the learned manifold, e.g., for \textit{foundation models} like Stable Diffusion generation performance can vary significantly based on the conditioning or initial noise vector being denoised. In this paper we study the relationship between the \textit{local geometry of the learned manifold} and downstream generation. Based on the theory of continuous piecewise-linear (CPWL) generators, we use three geometric descriptors - scaling ($\psi$), rank ($\nu$), and complexity ($\delta$) - to characterize a pre-trained generative model manifold locally. We provide quantitative and qualitative evidence showing that for a given latent, the local descriptors are correlated with generation aesthetics, artifacts, uncertainty, and even memorization. Finally we demonstrate that training a \textit{reward model} on the local geometry can allow controlling the likelihood of a generated sample under the learned distribution.
Dynamic Corrective Self-Distillation for Better Fine-Tuning of Pretrained Models
Dec 12, 2023We tackle the challenging issue of aggressive fine-tuning encountered during the process of transfer learning of pre-trained language models (PLMs) with limited labeled downstream data. This problem primarily results in a decline in performance on the subsequent task. Inspired by the adaptive boosting method in traditional machine learning, we present an effective dynamic corrective self-distillation (DCS) approach to improve the fine-tuning of the PLMs. Our technique involves performing a self-distillation mechanism where, at each iteration, the student model actively adapts and corrects itself by dynamically adjusting the weights assigned to individual data points. This iterative self-correcting process significantly enhances the overall fine-tuning capability of PLMs, leading to improved performance and robustness. We conducted comprehensive evaluations using the GLUE benchmark demonstrating the efficacy of our method in enhancing the fine-tuning process for various PLMs across diverse downstream tasks.
Improved Contextual Recognition In Automatic Speech Recognition Systems By Semantic Lattice Rescoring
Oct 27, 2023Automatic Speech Recognition (ASR) has witnessed a profound research interest. Recent breakthroughs have given ASR systems different prospects such as faithfully transcribing spoken language, which is a pivotal advancement in building conversational agents. However, there is still an imminent challenge of accurately discerning context-dependent words and phrases. In this work, we propose a novel approach for enhancing contextual recognition within ASR systems via semantic lattice processing leveraging the power of deep learning models in accurately delivering spot-on transcriptions across a wide variety of vocabularies and speaking styles. Our solution consists of using Hidden Markov Models and Gaussian Mixture Models (HMM-GMM) along with Deep Neural Networks (DNN) models integrating both language and acoustic modeling for better accuracy. We infused our network with the use of a transformer-based model to properly rescore the word lattice achieving remarkable capabilities with a palpable reduction in Word Error Rate (WER). We demonstrate the effectiveness of our proposed framework on the LibriSpeech dataset with empirical analyses.
BD-KD: Balancing the Divergences for Online Knowledge Distillation
Dec 25, 2022Knowledge distillation (KD) has gained a lot of attention in the field of model compression for edge devices thanks to its effectiveness in compressing large powerful networks into smaller lower-capacity models. Online distillation, in which both the teacher and the student are learning collaboratively, has also gained much interest due to its ability to improve on the performance of the networks involved. The Kullback-Leibler (KL) divergence ensures the proper knowledge transfer between the teacher and student. However, most online KD techniques present some bottlenecks under the network capacity gap. By cooperatively and simultaneously training, the models the KL distance becomes incapable of properly minimizing the teacher's and student's distributions. Alongside accuracy, critical edge device applications are in need of well-calibrated compact networks. Confidence calibration provides a sensible way of getting trustworthy predictions. We propose BD-KD: Balancing of Divergences for online Knowledge Distillation. We show that adaptively balancing between the reverse and forward divergences shifts the focus of the training strategy to the compact student network without limiting the teacher network's learning process. We demonstrate that, by performing this balancing design at the level of the student distillation loss, we improve upon both performance accuracy and calibration of the compact student network. We conducted extensive experiments using a variety of network architectures and show improvements on multiple datasets including CIFAR-10, CIFAR-100, Tiny-ImageNet, and ImageNet. We illustrate the effectiveness of our approach through comprehensive comparisons and ablations with current state-of-the-art online and offline KD techniques.
CES-KD: Curriculum-based Expert Selection for Guided Knowledge Distillation
Sep 15, 2022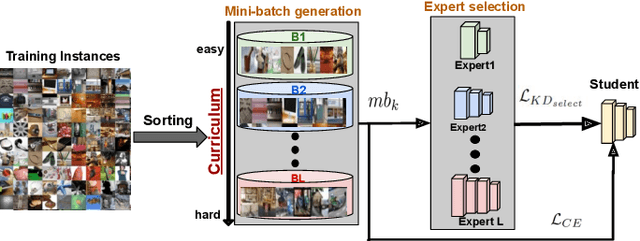
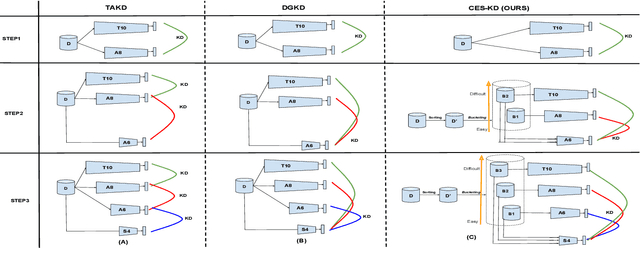
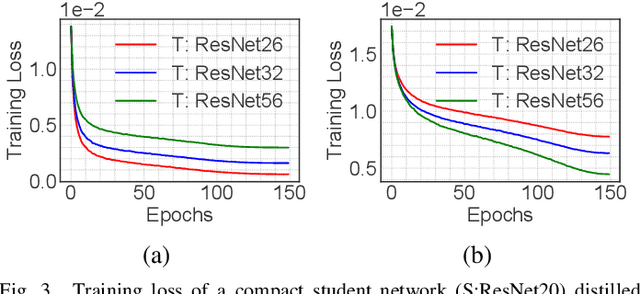
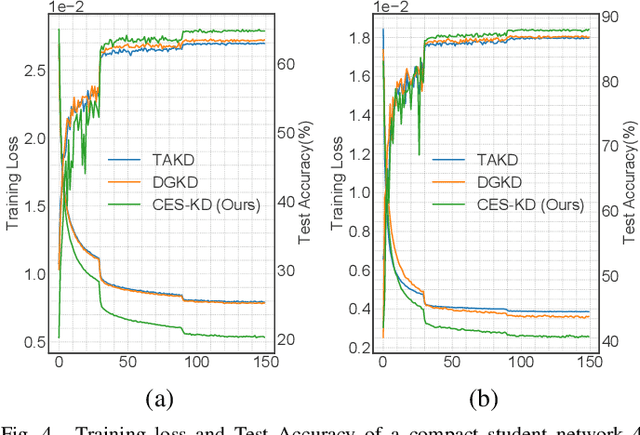
Knowledge distillation (KD) is an effective tool for compressing deep classification models for edge devices. However, the performance of KD is affected by the large capacity gap between the teacher and student networks. Recent methods have resorted to a multiple teacher assistant (TA) setting for KD, which sequentially decreases the size of the teacher model to relatively bridge the size gap between these models. This paper proposes a new technique called Curriculum Expert Selection for Knowledge Distillation (CES-KD) to efficiently enhance the learning of a compact student under the capacity gap problem. This technique is built upon the hypothesis that a student network should be guided gradually using stratified teaching curriculum as it learns easy (hard) data samples better and faster from a lower (higher) capacity teacher network. Specifically, our method is a gradual TA-based KD technique that selects a single teacher per input image based on a curriculum driven by the difficulty in classifying the image. In this work, we empirically verify our hypothesis and rigorously experiment with CIFAR-10, CIFAR-100, CINIC-10, and ImageNet datasets and show improved accuracy on VGG-like models, ResNets, and WideResNets architectures.