 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthy AI Suffers from Invariance Conflicts and Causality is The Solution
May 04, 2026As artificial intelligence (AI), including machine learning (ML) models and foundation models (FMs), is increasingly deployed in high-stakes domains, ensuring their trustworthiness has become a central challenge. However, the core trustworthy AI objectives, such as fairness, robustness, privacy, and explainability, are hard to achieve simultaneously, especially while preserving utility. This position paper argues that causality is necessary to understand and balance trade-offs in performance and multiple objectives of trustworthy AI. We ground our arguments in re-interpreting trustworthy AI trade-offs as incompatible invariance requirements under different changes to the data-generating process. We then illustrate that causality provides a unifying framework for understanding how trade-offs in trustworthy AI arise, and how they can be softened or resolved through selective invariance. This perspective applies to both classical ML models and large-scale FMs. Our paper discusses how causal assumptions may be applied explicitly or implicitly in modern large-scale systems. Finally, we outline open challenges and opportunities for using causality to build more trustworthy AI.
Understanding the Local Geometry of Generative Model Manifolds
Aug 15, 2024



Deep generative models learn continuous representations of complex data manifolds using a finite number of samples during training. For a pre-trained generative model, the common way to evaluate the quality of the manifold representation learned, is by computing global metrics like Fr\'echet Inception Distance using a large number of generated and real samples. However, generative model performance is not uniform across the learned manifold, e.g., for \textit{foundation models} like Stable Diffusion generation performance can vary significantly based on the conditioning or initial noise vector being denoised. In this paper we study the relationship between the \textit{local geometry of the learned manifold} and downstream generation. Based on the theory of continuous piecewise-linear (CPWL) generators, we use three geometric descriptors - scaling ($\psi$), rank ($\nu$), and complexity ($\delta$) - to characterize a pre-trained generative model manifold locally. We provide quantitative and qualitative evidence showing that for a given latent, the local descriptors are correlated with generation aesthetics, artifacts, uncertainty, and even memorization. Finally we demonstrate that training a \textit{reward model} on the local geometry can allow controlling the likelihood of a generated sample under the learned distribution.
Position: Cracking the Code of Cascading Disparity Towards Marginalized Communities
Jun 03, 2024
The rise of foundation models holds immense promise for advancing AI, but this progress may amplify existing risks and inequalities, leaving marginalized communities behind. In this position paper, we discuss that disparities towards marginalized communities - performance, representation, privacy, robustness, interpretability and safety - are not isolated concerns but rather interconnected elements of a cascading disparity phenomenon. We contrast foundation models with traditional models and highlight the potential for exacerbated disparity against marginalized communities. Moreover, we emphasize the unique threat of cascading impacts in foundation models, where interconnected disparities can trigger long-lasting negative consequences, specifically to the people on the margin. We define marginalized communities within the machine learning context and explore the multifaceted nature of disparities. We analyze the sources of these disparities, tracing them from data creation, training and deployment procedures to highlight the complex technical and socio-technical landscape. To mitigate the pressing crisis, we conclude with a set of calls to action to mitigate disparity at its source.
DeCoDEx: Confounder Detector Guidance for Improved Diffusion-based Counterfactual Explanations
May 15, 2024

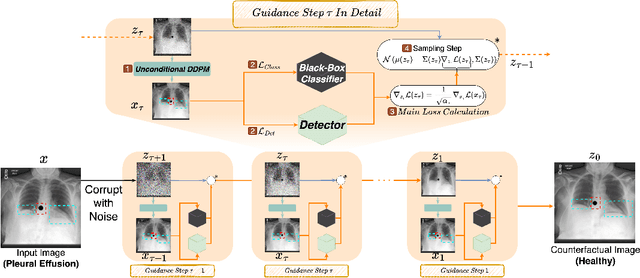

Deep learning classifiers are prone to latching onto dominant confounders present in a dataset rather than on the causal markers associated with the target class, leading to poor generalization and biased predictions. Although explainability via counterfactual image generation has been successful at exposing the problem, bias mitigation strategies that permit accurate explainability in the presence of dominant and diverse artifacts remain unsolved. In this work, we propose the DeCoDEx framework and show how an external, pre-trained binary artifact detector can be leveraged during inference to guide a diffusion-based counterfactual image generator towards accurate explainability. Experiments on the CheXpert dataset, using both synthetic artifacts and real visual artifacts (support devices), show that the proposed method successfully synthesizes the counterfactual images that change the causal pathology markers associated with Pleural Effusion while preserving or ignoring the visual artifacts. Augmentation of ERM and Group-DRO classifiers with the DeCoDEx generated images substantially improves the results across underrepresented groups that are out of distribution for each class. The code is made publicly available at https://github.com/NimaFathi/DeCoDEx.
Source-free Domain Adaptation Requires Penalized Diversity
Apr 12, 2023



While neural networks are capable of achieving human-like performance in many tasks such as image classification, the impressive performance of each model is limited to its own dataset. Source-free domain adaptation (SFDA) was introduced to address knowledge transfer between different domains in the absence of source data, thus, increasing data privacy. Diversity in representation space can be vital to a model`s adaptability in varied and difficult domains. In unsupervised SFDA, the diversity is limited to learning a single hypothesis on the source or learning multiple hypotheses with a shared feature extractor. Motivated by the improved predictive performance of ensembles, we propose a novel unsupervised SFDA algorithm that promotes representational diversity through the use of separate feature extractors with Distinct Backbone Architectures (DBA). Although diversity in feature space is increased, the unconstrained mutual information (MI) maximization may potentially introduce amplification of weak hypotheses. Thus we introduce the Weak Hypothesis Penalization (WHP) regularizer as a mitigation strategy. Our work proposes Penalized Diversity (PD) where the synergy of DBA and WHP is applied to unsupervised source-free domain adaptation for covariate shift. In addition, PD is augmented with a weighted MI maximization objective for label distribution shift. Empirical results on natural, synthetic, and medical domains demonstrate the effectiveness of PD under different distributional shifts.
Pitfalls of Conditional Batch Normalization for Contextual Multi-Modal Learning
Nov 28, 2022Humans have perfected the art of learning from multiple modalities through sensory organs. Despite their impressive predictive performance on a single modality, neural networks cannot reach human level accuracy with respect to multiple modalities. This is a particularly challenging task due to variations in the structure of respective modalities. Conditional Batch Normalization (CBN) is a popular method that was proposed to learn contextual features to aid deep learning tasks. This technique uses auxiliary data to improve representational power by learning affine transformations for convolutional neural networks. Despite the boost in performance observed by using CBN layers, our work reveals that the visual features learned by introducing auxiliary data via CBN deteriorates. We perform comprehensive experiments to evaluate the brittleness of CBN networks to various datasets, suggesting that learning from visual features alone could often be superior for generalization. We evaluate CBN models on natural images for bird classification and histology images for cancer type classification. We observe that the CBN network learns close to no visual features on the bird classification dataset and partial visual features on the histology dataset. Our extensive experiments reveal that CBN may encourage shortcut learning between the auxiliary data and labels.
FL Games: A Federated Learning Framework for Distribution Shifts
Oct 31, 2022



Federated learning aims to train predictive models for data that is distributed across clients, under the orchestration of a server. However, participating clients typically each hold data from a different distribution, which can yield to catastrophic generalization on data from a different client, which represents a new domain. In this work, we argue that in order to generalize better across non-i.i.d. clients, it is imperative to only learn correlations that are stable and invariant across domains. We propose FL GAMES, a game-theoretic framework for federated learning that learns causal features that are invariant across clients. While training to achieve the Nash equilibrium, the traditional best response strategy suffers from high-frequency oscillations. We demonstrate that FL GAMES effectively resolves this challenge and exhibits smooth performance curves. Further, FL GAMES scales well in the number of clients, requires significantly fewer communication rounds, and is agnostic to device heterogeneity. Through empirical evaluation, we demonstrate that FL GAMES achieves high out-of-distribution performance on various benchmarks.
FHIST: A Benchmark for Few-shot Classification of Histological Images
May 31, 2022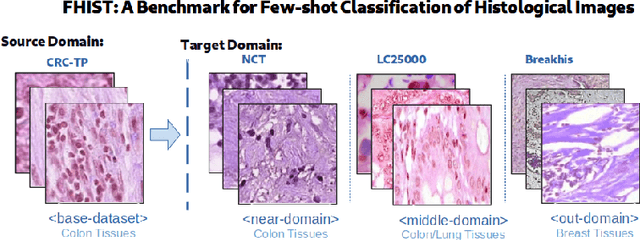
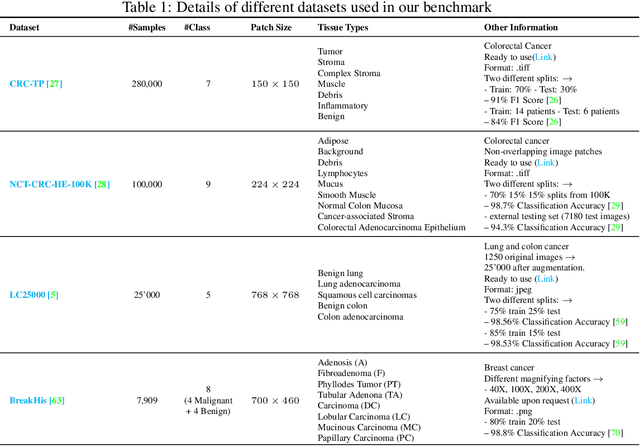
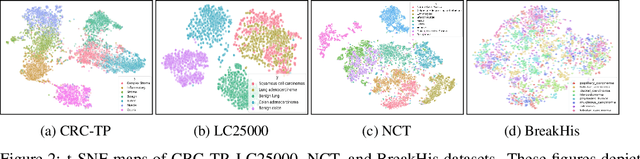
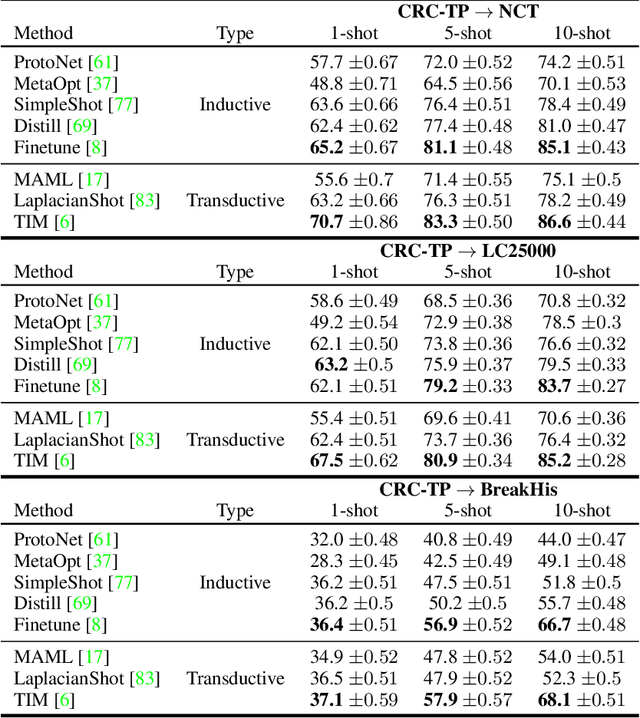
Few-shot learning has recently attracted wide interest in image classification, but almost all the current public benchmarks are focused on natural images. The few-shot paradigm is highly relevant in medical-imaging applications due to the scarcity of labeled data, as annotations are expensive and require specialized expertise. However, in medical imaging, few-shot learning research is sparse, limited to private data sets and is at its early stage. In particular, the few-shot setting is of high interest in histology due to the diversity and fine granularity of cancer related tissue classification tasks, and the variety of data-preparation techniques. This paper introduces a highly diversified public benchmark, gathered from various public datasets, for few-shot histology data classification. We build few-shot tasks and base-training data with various tissue types, different levels of domain shifts stemming from various cancer sites, and different class-granularity levels, thereby reflecting realistic scenarios. We evaluate the performances of state-of-the-art few-shot learning methods on our benchmark, and observe that simple fine-tuning and regularization methods achieve better results than the popular meta-learning and episodic-training paradigm. Furthermore, we introduce three scenarios based on the domain shifts between the source and target histology data: near-domain, middle-domain and out-domain. Our experiments display the potential of few-shot learning in histology classification, with state-of-art few shot learning methods approaching the supervised-learning baselines in the near-domain setting. In our out-domain setting, for 5-way 5-shot, the best performing method reaches 60% accuracy. We believe that our work could help in building realistic evaluations and fair comparisons of few-shot learning methods and will further encourage research in the few-shot paradigm.
Minimizing Client Drift in Federated Learning via Adaptive Bias Estimation
Apr 27, 2022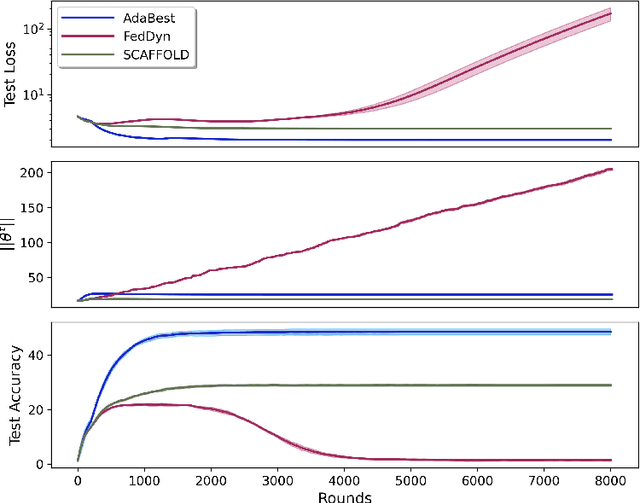

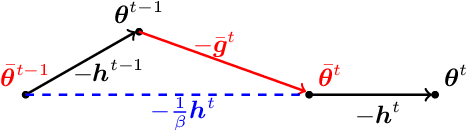
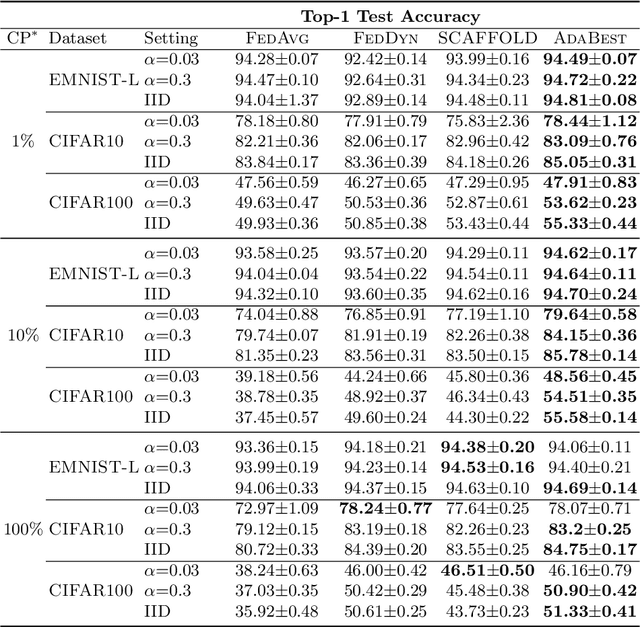
In Federated Learning a number of clients collaborate to train a model without sharing their data. Client models are optimized locally and are communicated through a central hub called server. A major challenge is to deal with heterogeneity among clients' data which causes the local optimization to drift away with respect to the global objective. In order to estimate and therefore remove this drift, variance reduction techniques have been incorporated into Federated Learning optimization recently. However, the existing solutions propagate the error of their estimations, throughout the optimization trajectory which leads to inaccurate approximations of the clients' drift and ultimately failure to remove them properly. In this paper, we address this issue by introducing an adaptive algorithm that efficiently reduces clients' drift. Compared to the previous works on adapting variance reduction to Federated Learning, our approach uses less or the same level of communication bandwidth, computation or memory. Additionally, it addresses the instability problem--prevalent in prior work, caused by increasing norm of the estimates which makes our approach a much more practical solution for large scale Federated Learning settings. Our experimental results demonstrate that the proposed algorithm converges significantly faster and achieves higher accuracy compared to the baselines in an extensive set of Federated Learning benchmarks.
CT-SGAN: Computed Tomography Synthesis GAN
Nov 04, 2021

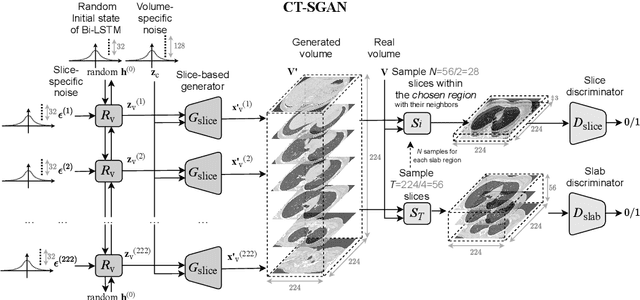
Diversity in data is critical for the successful training of deep learning models. Leveraged by a recurrent generative adversarial network, we propose the CT-SGAN model that generates large-scale 3D synthetic CT-scan volumes ($\geq 224\times224\times224$) when trained on a small dataset of chest CT-scans. CT-SGAN offers an attractive solution to two major challenges facing machine learning in medical imaging: a small number of given i.i.d. training data, and the restrictions around the sharing of patient data preventing to rapidly obtain larger and more diverse datasets. We evaluate the fidelity of the generated images qualitatively and quantitatively using various metrics including Fr\'echet Inception Distance and Inception Score. We further show that CT-SGAN can significantly improve lung nodule detection accuracy by pre-training a classifier on a vast amount of synthetic data.