 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoonshine: An Autonomous Mathematical Research Agent Centered on Conjecture Generation
Jun 09, 2026Moonshine is an autonomous agent whose central objective is to generate mathematical conjectures. Its core capability is to extract structure from classical problems, distill new concepts, and formulate conjectures of mathematical significance. Rather than treating the solution of a single proposition as its endpoint, Moonshine builds an extensible theoretical framework through conjecture generation, bridge building, and obstacle identification. This article uses Moonshine's exploration of the Jacobian conjecture as an example. It shows how the central logic of whether local nondegeneracy can force global injectivity is transferred to one-hidden-layer affine-ridge sigmoid networks. This leads to the formulation of the \emph{Neural Jacobian Conjecture} (NJC): if such a network has strictly positive Jacobian determinant on the whole space, then it must be globally injective. By invoking GPT-5.5-pro and DeepSeek-V4-pro separately, Moonshine obtained independent complete proofs for the case \(N=n+1\). In addition, with the assistance of ChatGPT through interactive use of its web interface with GPT-5.5-pro, a geometric-topological proof was developed. These results provide preliminary evidence for the plausibility of the conjecture. The general higher-width case \(N\ge n+2\), however, remains unresolved and is left for further investigation. This work illustrates Moonshine's ability to autonomously generate meaningful mathematical problems and make rigorous progress on them.
Can LLM generate interesting mathematical research problems?
Mar 19, 2026This paper is the second one in a series of work on the mathematical creativity of LLM. In the first paper, the authors proposed three criteria for evaluating the mathematical creativity of LLM and constructed a benchmark dataset to measure it. This paper further explores the mathematical creativity of LLM, with a focus on investigating whether LLM can generate valuable and cutting-edge mathematical research problems. We develop an agent to generate unknown problems and produced 665 research problems in differential geometry. Through human verification, we find that many of these mathematical problems are unknown to experts and possess unique research value.
DeepMath-Creative: A Benchmark for Evaluating Mathematical Creativity of Large Language Models
May 13, 2025

To advance the mathematical proficiency of large language models (LLMs), the DeepMath team has launched an open-source initiative aimed at developing an open mathematical LLM and systematically evaluating its mathematical creativity. This paper represents the initial contribution of this initiative. While recent developments in mathematical LLMs have predominantly emphasized reasoning skills, as evidenced by benchmarks on elementary to undergraduate-level mathematical tasks, the creative capabilities of these models have received comparatively little attention, and evaluation datasets remain scarce. To address this gap, we propose an evaluation criteria for mathematical creativity and introduce DeepMath-Creative, a novel, high-quality benchmark comprising constructive problems across algebra, geometry, analysis, and other domains. We conduct a systematic evaluation of mainstream LLMs' creative problem-solving abilities using this dataset. Experimental results show that even under lenient scoring criteria -- emphasizing core solution components and disregarding minor inaccuracies, such as small logical gaps, incomplete justifications, or redundant explanations -- the best-performing model, O3 Mini, achieves merely 70% accuracy, primarily on basic undergraduate-level constructive tasks. Performance declines sharply on more complex problems, with models failing to provide substantive strategies for open problems. These findings suggest that, although current LLMs display a degree of constructive proficiency on familiar and lower-difficulty problems, such performance is likely attributable to the recombination of memorized patterns rather than authentic creative insight or novel synthesis.
NeoQA: Evidence-based Question Answering with Generated News Events
May 09, 2025

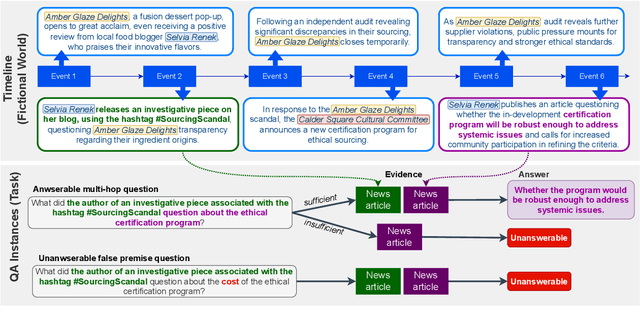

Evaluating Retrieval-Augmented Generation (RAG) in large language models (LLMs) is challenging because benchmarks can quickly become stale. Questions initially requiring retrieval may become answerable from pretraining knowledge as newer models incorporate more recent information during pretraining, making it difficult to distinguish evidence-based reasoning from recall. We introduce NeoQA (News Events for Out-of-training Question Answering), a benchmark designed to address this issue. To construct NeoQA, we generated timelines and knowledge bases of fictional news events and entities along with news articles and Q\&A pairs to prevent LLMs from leveraging pretraining knowledge, ensuring that no prior evidence exists in their training data. We propose our dataset as a new platform for evaluating evidence-based question answering, as it requires LLMs to generate responses exclusively from retrieved evidence and only when sufficient evidence is available. NeoQA enables controlled evaluation across various evidence scenarios, including cases with missing or misleading details. Our findings indicate that LLMs struggle to distinguish subtle mismatches between questions and evidence, and suffer from short-cut reasoning when key information required to answer a question is missing from the evidence, underscoring key limitations in evidence-based reasoning.
Fuzzy Cluster-Aware Contrastive Clustering for Time Series
Mar 28, 2025

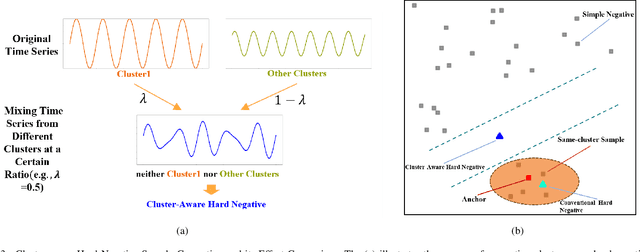

The rapid growth of unlabeled time series data, driven by the Internet of Things (IoT), poses significant challenges in uncovering underlying patterns. Traditional unsupervised clustering methods often fail to capture the complex nature of time series data. Recent deep learning-based clustering approaches, while effective, struggle with insufficient representation learning and the integration of clustering objectives. To address these issues, we propose a fuzzy cluster-aware contrastive clustering framework (FCACC) that jointly optimizes representation learning and clustering. Our approach introduces a novel three-view data augmentation strategy to enhance feature extraction by leveraging various characteristics of time series data. Additionally, we propose a cluster-aware hard negative sample generation mechanism that dynamically constructs high-quality negative samples using clustering structure information, thereby improving the model's discriminative ability. By leveraging fuzzy clustering, FCACC dynamically generates cluster structures to guide the contrastive learning process, resulting in more accurate clustering. Extensive experiments on 40 benchmark datasets show that FCACC outperforms the selected baseline methods (eight in total), providing an effective solution for unsupervised time series learning.
Hypothesis Disparity Regularized Mutual Information Maximization
Dec 15, 2020
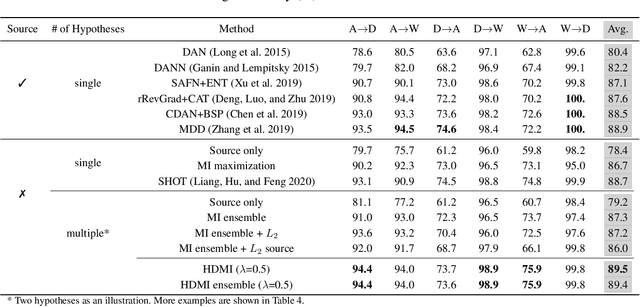
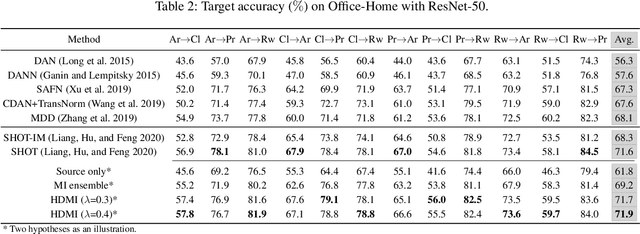
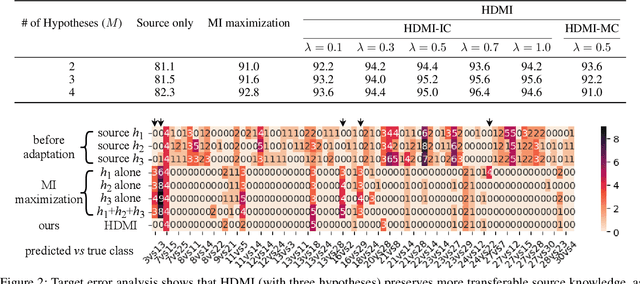
We propose a hypothesis disparity regularized mutual information maximization~(HDMI) approach to tackle unsupervised hypothesis transfer -- as an effort towards unifying hypothesis transfer learning (HTL) and unsupervised domain adaptation (UDA) -- where the knowledge from a source domain is transferred solely through hypotheses and adapted to the target domain in an unsupervised manner. In contrast to the prevalent HTL and UDA approaches that typically use a single hypothesis, HDMI employs multiple hypotheses to leverage the underlying distributions of the source and target hypotheses. To better utilize the crucial relationship among different hypotheses -- as opposed to unconstrained optimization of each hypothesis independently -- while adapting to the unlabeled target domain through mutual information maximization, HDMI incorporates a hypothesis disparity regularization that coordinates the target hypotheses jointly learn better target representations while preserving more transferable source knowledge with better-calibrated prediction uncertainty. HDMI achieves state-of-the-art adaptation performance on benchmark datasets for UDA in the context of HTL, without the need to access the source data during the adaptation.
Implicit Class-Conditioned Domain Alignment for Unsupervised Domain Adaptation
Jun 09, 2020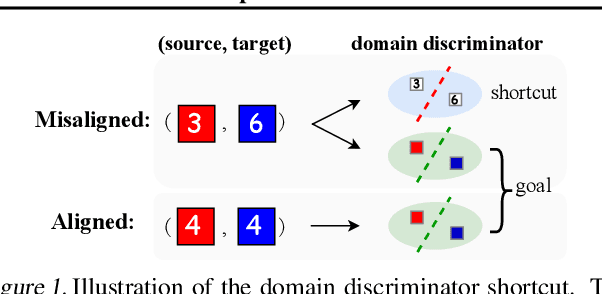
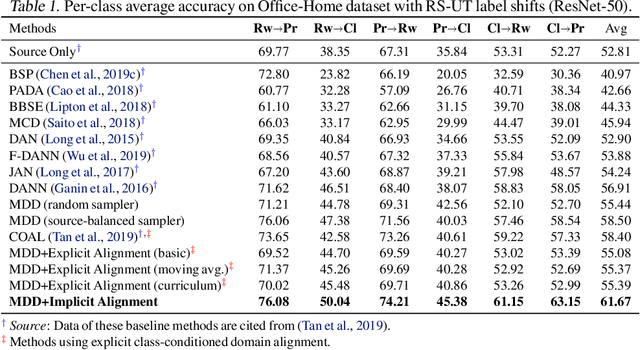


We present an approach for unsupervised domain adaptation---with a strong focus on practical considerations of within-domain class imbalance and between-domain class distribution shift---from a class-conditioned domain alignment perspective. Current methods for class-conditioned domain alignment aim to explicitly minimize a loss function based on pseudo-label estimations of the target domain. However, these methods suffer from pseudo-label bias in the form of error accumulation. We propose a method that removes the need for explicit optimization of model parameters from pseudo-labels directly. Instead, we present a sampling-based implicit alignment approach, where the sample selection procedure is implicitly guided by the pseudo-labels. Theoretical analysis reveals the existence of a domain-discriminator shortcut in misaligned classes, which is addressed by the proposed implicit alignment approach to facilitate domain-adversarial learning. Empirical results and ablation studies confirm the effectiveness of the proposed approach, especially in the presence of within-domain class imbalance and between-domain class distribution shift.
Continuous Domain Adaptation with Variational Domain-Agnostic Feature Replay
Mar 09, 2020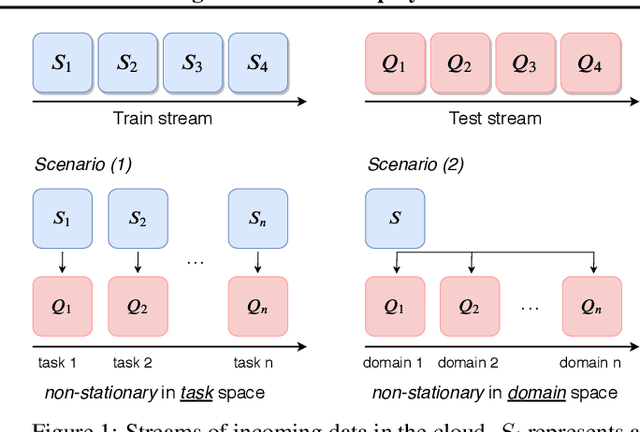
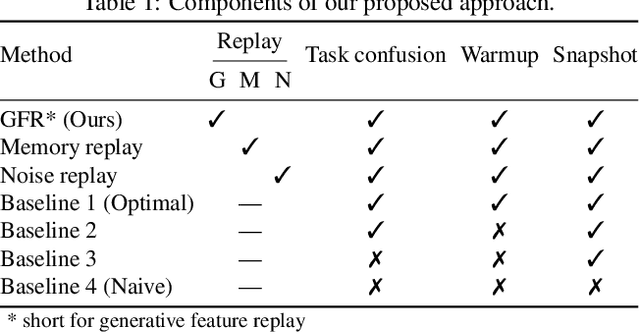
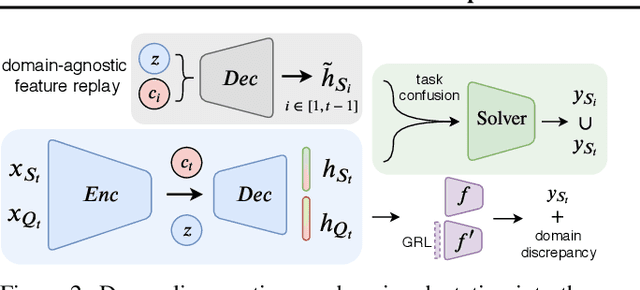
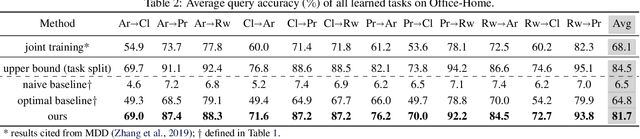
Learning in non-stationary environments is one of the biggest challenges in machine learning. Non-stationarity can be caused by either task drift, i.e., the drift in the conditional distribution of labels given the input data, or the domain drift, i.e., the drift in the marginal distribution of the input data. This paper aims to tackle this challenge in the context of continuous domain adaptation, where the model is required to learn new tasks adapted to new domains in a non-stationary environment while maintaining previously learned knowledge. To deal with both drifts, we propose variational domain-agnostic feature replay, an approach that is composed of three components: an inference module that filters the input data into domain-agnostic representations, a generative module that facilitates knowledge transfer, and a solver module that applies the filtered and transferable knowledge to solve the queries. We address the two fundamental scenarios in continuous domain adaptation, demonstrating the effectiveness of our proposed approach for practical usage.
On the Importance of Attention in Meta-Learning for Few-Shot Text Classification
Jun 03, 2018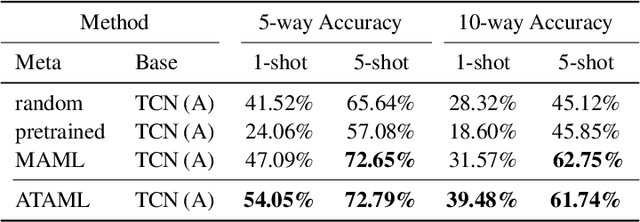
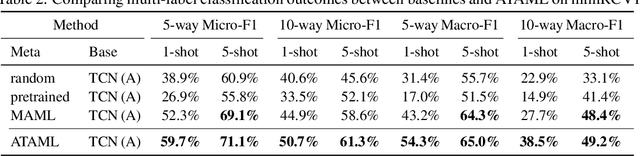
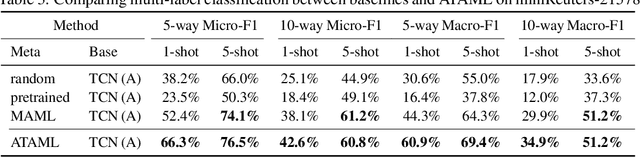
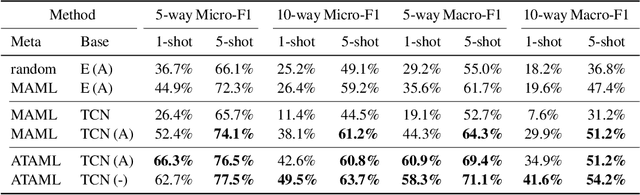
Current deep learning based text classification methods are limited by their ability to achieve fast learning and generalization when the data is scarce. We address this problem by integrating a meta-learning procedure that uses the knowledge learned across many tasks as an inductive bias towards better natural language understanding. Based on the Model-Agnostic Meta-Learning framework (MAML), we introduce the Attentive Task-Agnostic Meta-Learning (ATAML) algorithm for text classification. The essential difference between MAML and ATAML is in the separation of task-agnostic representation learning and task-specific attentive adaptation. The proposed ATAML is designed to encourage task-agnostic representation learning by way of task-agnostic parameterization and facilitate task-specific adaptation via attention mechanisms. We provide evidence to show that the attention mechanism in ATAML has a synergistic effect on learning performance. In comparisons with models trained from random initialization, pretrained models and meta trained MAML, our proposed ATAML method generalizes better on single-label and multi-label classification tasks in miniRCV1 and miniReuters-21578 datasets.
TrajectoryNet: An Embedded GPS Trajectory Representation for Point-based Classification Using Recurrent Neural Networks
Aug 30, 2017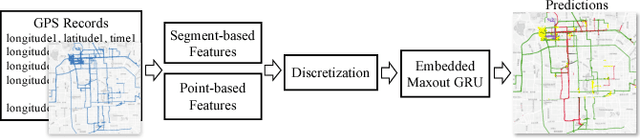


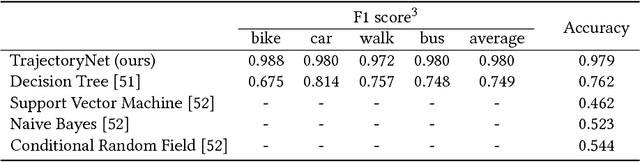
Understanding and discovering knowledge from GPS (Global Positioning System) traces of human activities is an essential topic in mobility-based urban computing. We propose TrajectoryNet-a neural network architecture for point-based trajectory classification to infer real world human transportation modes from GPS traces. To overcome the challenge of capturing the underlying latent factors in the low-dimensional and heterogeneous feature space imposed by GPS data, we develop a novel representation that embeds the original feature space into another space that can be understood as a form of basis expansion. We also enrich the feature space via segment-based information and use Maxout activations to improve the predictive power of Recurrent Neural Networks (RNNs). We achieve over 98% classification accuracy when detecting four types of transportation modes, outperforming existing models without additional sensory data or location-based prior knowledge.