 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLyapunov Stable Graph Neural Flow
Mar 13, 2026Graph Neural Networks (GNNs) are highly vulnerable to adversarial perturbations in both topology and features, making the learning of robust representations a critical challenge. In this work, we bridge GNNs with control theory to introduce a novel defense framework grounded in integer- and fractional-order Lyapunov stability. Unlike conventional strategies that rely on resource-heavy adversarial training or data purification, our approach fundamentally constrains the underlying feature-update dynamics of the GNN. We propose an adaptive, learnable Lyapunov function paired with a novel projection mechanism that maps the network's state into a stable space, thereby offering theoretically provable stability guarantees. Notably, this mechanism is orthogonal to existing defenses, allowing for seamless integration with techniques like adversarial training to achieve cumulative robustness. Extensive experiments demonstrate that our Lyapunov-stable graph neural flows substantially outperform base neural flows and state-of-the-art baselines across standard benchmarks and various adversarial attack scenarios.
Towards Benchmarking and Assessing the Safety and Robustness of Autonomous Driving on Safety-critical Scenarios
Mar 31, 2025



Autonomous driving has made significant progress in both academia and industry, including performance improvements in perception task and the development of end-to-end autonomous driving systems. However, the safety and robustness assessment of autonomous driving has not received sufficient attention. Current evaluations of autonomous driving are typically conducted in natural driving scenarios. However, many accidents often occur in edge cases, also known as safety-critical scenarios. These safety-critical scenarios are difficult to collect, and there is currently no clear definition of what constitutes a safety-critical scenario. In this work, we explore the safety and robustness of autonomous driving in safety-critical scenarios. First, we provide a definition of safety-critical scenarios, including static traffic scenarios such as adversarial attack scenarios and natural distribution shifts, as well as dynamic traffic scenarios such as accident scenarios. Then, we develop an autonomous driving safety testing platform to comprehensively evaluate autonomous driving systems, encompassing not only the assessment of perception modules but also system-level evaluations. Our work systematically constructs a safety verification process for autonomous driving, providing technical support for the industry to establish standardized test framework and reduce risks in real-world road deployment.
Automatic Spectral Calibration of Hyperspectral Images:Method, Dataset and Benchmark
Dec 19, 2024



Hyperspectral image (HSI) densely samples the world in both the space and frequency domain and therefore is more distinctive than RGB images. Usually, HSI needs to be calibrated to minimize the impact of various illumination conditions. The traditional way to calibrate HSI utilizes a physical reference, which involves manual operations, occlusions, and/or limits camera mobility. These limitations inspire this paper to automatically calibrate HSIs using a learning-based method. Towards this goal, a large-scale HSI calibration dataset is created, which has 765 high-quality HSI pairs covering diversified natural scenes and illuminations. The dataset is further expanded to 7650 pairs by combining with 10 different physically measured illuminations. A spectral illumination transformer (SIT) together with an illumination attention module is proposed. Extensive benchmarks demonstrate the SoTA performance of the proposed SIT. The benchmarks also indicate that low-light conditions are more challenging than normal conditions. The dataset and codes are available online:https://github.com/duranze/Automatic-spectral-calibration-of-HSI
Frequency-Aware Deepfake Detection: Improving Generalizability through Frequency Space Learning
Mar 12, 2024



This research addresses the challenge of developing a universal deepfake detector that can effectively identify unseen deepfake images despite limited training data. Existing frequency-based paradigms have relied on frequency-level artifacts introduced during the up-sampling in GAN pipelines to detect forgeries. However, the rapid advancements in synthesis technology have led to specific artifacts for each generation model. Consequently, these detectors have exhibited a lack of proficiency in learning the frequency domain and tend to overfit to the artifacts present in the training data, leading to suboptimal performance on unseen sources. To address this issue, we introduce a novel frequency-aware approach called FreqNet, centered around frequency domain learning, specifically designed to enhance the generalizability of deepfake detectors. Our method forces the detector to continuously focus on high-frequency information, exploiting high-frequency representation of features across spatial and channel dimensions. Additionally, we incorporate a straightforward frequency domain learning module to learn source-agnostic features. It involves convolutional layers applied to both the phase spectrum and amplitude spectrum between the Fast Fourier Transform (FFT) and Inverse Fast Fourier Transform (iFFT). Extensive experimentation involving 17 GANs demonstrates the effectiveness of our proposed method, showcasing state-of-the-art performance (+9.8\%) while requiring fewer parameters. The code is available at {\cred \url{https://github.com/chuangchuangtan/FreqNet-DeepfakeDetection}}.
Learning Invariant Inter-pixel Correlations for Superpixel Generation
Feb 28, 2024



Deep superpixel algorithms have made remarkable strides by substituting hand-crafted features with learnable ones. Nevertheless, we observe that existing deep superpixel methods, serving as mid-level representation operations, remain sensitive to the statistical properties (e.g., color distribution, high-level semantics) embedded within the training dataset. Consequently, learnable features exhibit constrained discriminative capability, resulting in unsatisfactory pixel grouping performance, particularly in untrainable application scenarios. To address this issue, we propose the Content Disentangle Superpixel (CDS) algorithm to selectively separate the invariant inter-pixel correlations and statistical properties, i.e., style noise. Specifically, We first construct auxiliary modalities that are homologous to the original RGB image but have substantial stylistic variations. Then, driven by mutual information, we propose the local-grid correlation alignment across modalities to reduce the distribution discrepancy of adaptively selected features and learn invariant inter-pixel correlations. Afterwards, we perform global-style mutual information minimization to enforce the separation of invariant content and train data styles. The experimental results on four benchmark datasets demonstrate the superiority of our approach to existing state-of-the-art methods, regarding boundary adherence, generalization, and efficiency. Code and pre-trained model are available at https://github.com/rookiie/CDSpixel.
Structure-Preserving Physics-Informed Neural Networks With Energy or Lyapunov Structure
Jan 10, 2024
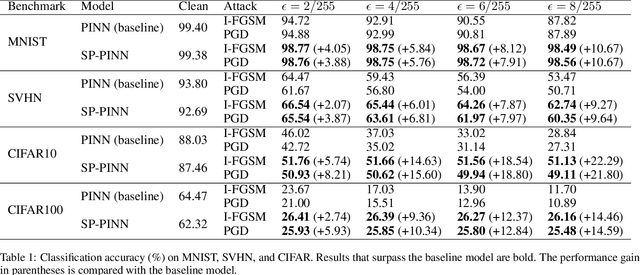

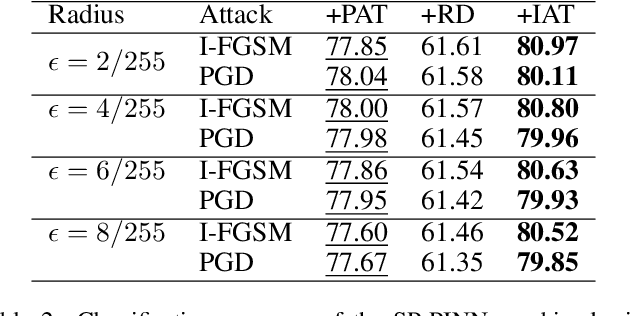
Recently, there has been growing interest in using physics-informed neural networks (PINNs) to solve differential equations. However, the preservation of structure, such as energy and stability, in a suitable manner has yet to be established. This limitation could be a potential reason why the learning process for PINNs is not always efficient and the numerical results may suggest nonphysical behavior. Besides, there is little research on their applications on downstream tasks. To address these issues, we propose structure-preserving PINNs to improve their performance and broaden their applications for downstream tasks. Firstly, by leveraging prior knowledge about the physical system, a structure-preserving loss function is designed to assist the PINN in learning the underlying structure. Secondly, a framework that utilizes structure-preserving PINN for robust image recognition is proposed. Here, preserving the Lyapunov structure of the underlying system ensures the stability of the system. Experimental results demonstrate that the proposed method improves the numerical accuracy of PINNs for partial differential equations. Furthermore, the robustness of the model against adversarial perturbations in image data is enhanced.
Rethinking the Up-Sampling Operations in CNN-based Generative Network for Generalizable Deepfake Detection
Dec 20, 2023Recently, the proliferation of highly realistic synthetic images, facilitated through a variety of GANs and Diffusions, has significantly heightened the susceptibility to misuse. While the primary focus of deepfake detection has traditionally centered on the design of detection algorithms, an investigative inquiry into the generator architectures has remained conspicuously absent in recent years. This paper contributes to this lacuna by rethinking the architectures of CNN-based generators, thereby establishing a generalized representation of synthetic artifacts. Our findings illuminate that the up-sampling operator can, beyond frequency-based artifacts, produce generalized forgery artifacts. In particular, the local interdependence among image pixels caused by upsampling operators is significantly demonstrated in synthetic images generated by GAN or diffusion. Building upon this observation, we introduce the concept of Neighboring Pixel Relationships(NPR) as a means to capture and characterize the generalized structural artifacts stemming from up-sampling operations. A comprehensive analysis is conducted on an open-world dataset, comprising samples generated by \tft{28 distinct generative models}. This analysis culminates in the establishment of a novel state-of-the-art performance, showcasing a remarkable \tft{11.6\%} improvement over existing methods. The code is available at https://github.com/chuangchuangtan/NPR-DeepfakeDetection.
Learning Robust Deep Equilibrium Models
Apr 26, 2023Deep equilibrium (DEQ) models have emerged as a promising class of implicit layer models in deep learning, which abandon traditional depth by solving for the fixed points of a single nonlinear layer. Despite their success, the stability of the fixed points for these models remains poorly understood. Recently, Lyapunov theory has been applied to Neural ODEs, another type of implicit layer model, to confer adversarial robustness. By considering DEQ models as nonlinear dynamic systems, we propose a robust DEQ model named LyaDEQ with guaranteed provable stability via Lyapunov theory. The crux of our method is ensuring the fixed points of the DEQ models are Lyapunov stable, which enables the LyaDEQ models to resist minor initial perturbations. To avoid poor adversarial defense due to Lyapunov-stable fixed points being located near each other, we add an orthogonal fully connected layer after the Lyapunov stability module to separate different fixed points. We evaluate LyaDEQ models on several widely used datasets under well-known adversarial attacks, and experimental results demonstrate significant improvement in robustness. Furthermore, we show that the LyaDEQ model can be combined with other defense methods, such as adversarial training, to achieve even better adversarial robustness.
Improving Neural ODEs via Knowledge Distillation
Mar 10, 2022
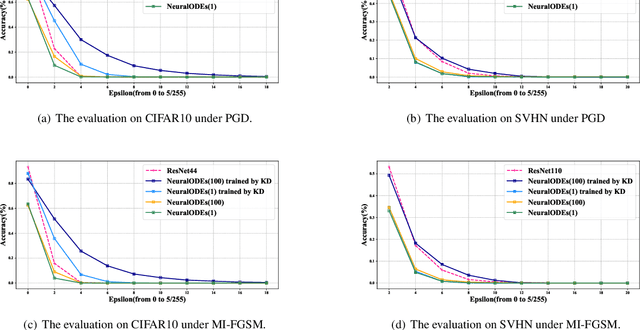
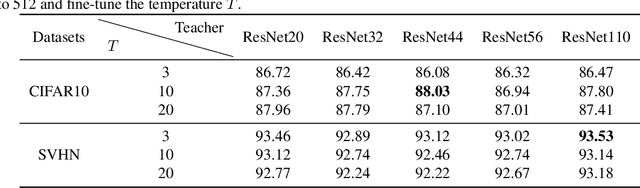

Neural Ordinary Differential Equations (Neural ODEs) construct the continuous dynamics of hidden units using ordinary differential equations specified by a neural network, demonstrating promising results on many tasks. However, Neural ODEs still do not perform well on image recognition tasks. The possible reason is that the one-hot encoding vector commonly used in Neural ODEs can not provide enough supervised information. We propose a new training based on knowledge distillation to construct more powerful and robust Neural ODEs fitting image recognition tasks. Specially, we model the training of Neural ODEs into a teacher-student learning process, in which we propose ResNets as the teacher model to provide richer supervised information. The experimental results show that the new training manner can improve the classification accuracy of Neural ODEs by 24% on CIFAR10 and 5% on SVHN. In addition, we also quantitatively discuss the effect of both knowledge distillation and time horizon in Neural ODEs on robustness against adversarial examples. The experimental analysis concludes that introducing the knowledge distillation and increasing the time horizon can improve the robustness of Neural ODEs against adversarial examples.
Towards Natural Robustness Against Adversarial Examples
Dec 04, 2020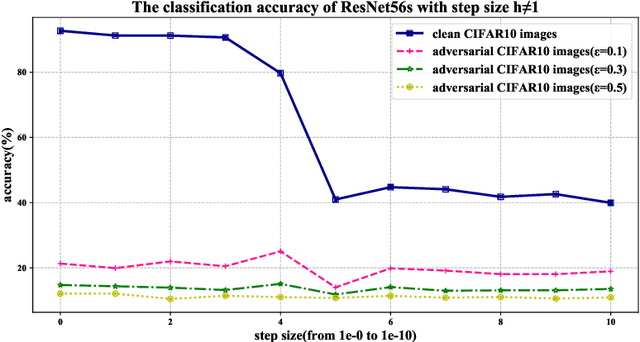
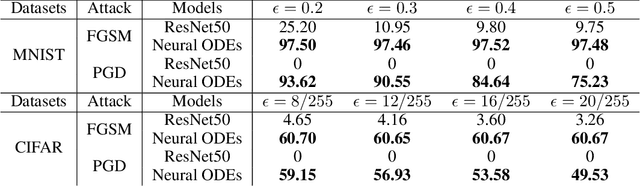
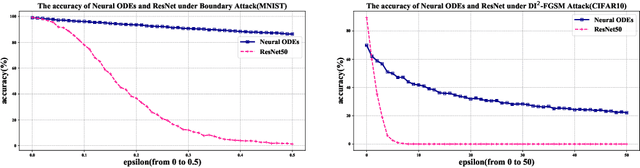

Recent studies have shown that deep neural networks are vulnerable to adversarial examples, but most of the methods proposed to defense adversarial examples cannot solve this problem fundamentally. In this paper, we theoretically prove that there is an upper bound for neural networks with identity mappings to constrain the error caused by adversarial noises. However, in actual computations, this kind of neural network no longer holds any upper bound and is therefore susceptible to adversarial examples. Following similar procedures, we explain why adversarial examples can fool other deep neural networks with skip connections. Furthermore, we demonstrate that a new family of deep neural networks called Neural ODEs (Chen et al., 2018) holds a weaker upper bound. This weaker upper bound prevents the amount of change in the result from being too large. Thus, Neural ODEs have natural robustness against adversarial examples. We evaluate the performance of Neural ODEs compared with ResNet under three white-box adversarial attacks (FGSM, PGD, DI2-FGSM) and one black-box adversarial attack (Boundary Attack). Finally, we show that the natural robustness of Neural ODEs is even better than the robustness of neural networks that are trained with adversarial training methods, such as TRADES and YOPO.