 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISTA: Vision-Grounded and Physics-Validated Adaptation of UMI data for VLA Training
Jun 04, 2026Universal Manipulation Interface (UMI) enables scalable real-world robot data collection without hardware-specific teleoperation, yet leveraging UMI data to train large-scale Vision-Language-Action (VLA) models remains fundamentally challenging. We identify two critical mismatches: wrist-mounted fisheye views, with severe radial distortion and local gripper-centric perspectives, are out-of-distribution for pretrained VLMs; and human-collected trajectories frequently violate kinematic limits, incur collisions, or exceed controller bandwidth, teaching VLA policies physically infeasible actions. To address the challenges, we present VISTA, a framework that bridges this dual gap through three synergistic components. (i)~UMI-VQA, the first large-scale VQA dataset tailored to wrist-mounted fisheye observations, aligns VLM representations to the distorted visual regime via auxiliary vision-language supervision. (ii)~A systematic physical-validation pipeline performs a data-completeness pre-check and scores each valid trajectory for trajectory continuity, self-collision risk, and execution fidelity before it enters training. (iii)~A two-stage co-training recipe jointly learns vision-language grounding on UMI-VQA and action prediction on validated trajectories. Our experiments empirically show that incorporating UMI-VQA consistently improves downstream policy performance, and that physical-validation scores are strongly predictive of deployment success. On diverse simulation and real-world manipulation tasks, VISTA significantly outperforms strong baselines including $π_{0.5}$, LingBot-VLA, and Wall-X. We release the physical-validation pipeline, UMI-VQA, validated trajectory data, and the pre-trained model for the community.
Contextual Rollout Bandits for Reinforcement Learning with Verifiable Rewards
Feb 09, 2026Reinforcement Learning with Verifiable Rewards (RLVR) is an effective paradigm for improving the reasoning capabilities of large language models. However, existing RLVR methods utilize rollouts in an indiscriminate and short-horizon manner: responses of heterogeneous quality within each prompt are treated uniformly, and historical rollouts are discarded after a single use. This leads to noisy supervision, poor sample efficiency, and suboptimal policy updates. We address these issues by formulating rollout scheduling in RLVR as a contextual bandit problem and proposing a unified neural scheduling framework that adaptively selects high-value rollouts throughout training. Each rollout is treated as an arm whose reward is defined by the induced performance gain between consecutive optimization steps. The resulting scheduler supports both noise-aware intra-group selection and adaptive global reuse of historical rollouts within a single principled framework. We provide theoretical justification by deriving sublinear regret bounds and showing that enlarging the rollout buffer improves the achievable performance upper bound. Experiments on six mathematical reasoning benchmarks demonstrate consistent gains in performance and training efficiency across multiple RLVR optimization methods.
NanoNet: Parameter-Efficient Learning with Label-Scarce Supervision for Lightweight Text Mining Model
Feb 05, 2026The lightweight semi-supervised learning (LSL) strategy provides an effective approach of conserving labeled samples and minimizing model inference costs. Prior research has effectively applied knowledge transfer learning and co-training regularization from large to small models in LSL. However, such training strategies are computationally intensive and prone to local optima, thereby increasing the difficulty of finding the optimal solution. This has prompted us to investigate the feasibility of integrating three low-cost scenarios for text mining tasks: limited labeled supervision, lightweight fine-tuning, and rapid-inference small models. We propose NanoNet, a novel framework for lightweight text mining that implements parameter-efficient learning with limited supervision. It employs online knowledge distillation to generate multiple small models and enhances their performance through mutual learning regularization. The entire process leverages parameter-efficient learning, reducing training costs and minimizing supervision requirements, ultimately yielding a lightweight model for downstream inference.
Scoring, Reasoning, and Selecting the Best! Ensembling Large Language Models via a Peer-Review Process
Dec 29, 2025We propose LLM-PeerReview, an unsupervised LLM Ensemble method that selects the most ideal response from multiple LLM-generated candidates for each query, harnessing the collective wisdom of multiple models with diverse strengths. LLM-PeerReview is built on a novel, peer-review-inspired framework that offers a clear and interpretable mechanism, while remaining fully unsupervised for flexible adaptability and generalization. Specifically, it operates in three stages: For scoring, we use the emerging LLM-as-a-Judge technique to evaluate each response by reusing multiple LLMs at hand; For reasoning, we can apply a principled graphical model-based truth inference algorithm or a straightforward averaging strategy to aggregate multiple scores to produce a final score for each response; Finally, the highest-scoring response is selected as the best ensemble output. LLM-PeerReview is conceptually simple and empirically powerful. The two variants of the proposed approach obtain strong results across four datasets, including outperforming the recent advanced model Smoothie-Global by 6.9% and 7.3% points, respectively.
LLMBoost: Make Large Language Models Stronger with Boosting
Dec 26, 2025Ensemble learning of LLMs has emerged as a promising alternative to enhance performance, but existing approaches typically treat models as black boxes, combining the inputs or final outputs while overlooking the rich internal representations and interactions across models.In this work, we introduce LLMBoost, a novel ensemble fine-tuning framework that breaks this barrier by explicitly leveraging intermediate states of LLMs. Inspired by the boosting paradigm, LLMBoost incorporates three key innovations. First, a cross-model attention mechanism enables successor models to access and fuse hidden states from predecessors, facilitating hierarchical error correction and knowledge transfer. Second, a chain training paradigm progressively fine-tunes connected models with an error-suppression objective, ensuring that each model rectifies the mispredictions of its predecessor with minimal additional computation. Third, a near-parallel inference paradigm design pipelines hidden states across models layer by layer, achieving inference efficiency approaching single-model decoding. We further establish the theoretical foundations of LLMBoost, proving that sequential integration guarantees monotonic improvements under bounded correction assumptions. Extensive experiments on commonsense reasoning and arithmetic reasoning tasks demonstrate that LLMBoost consistently boosts accuracy while reducing inference latency.
DA-SSL: self-supervised domain adaptor to leverage foundational models in turbt histopathology slides
Dec 15, 2025Recent deep learning frameworks in histopathology, particularly multiple instance learning (MIL) combined with pathology foundational models (PFMs), have shown strong performance. However, PFMs exhibit limitations on certain cancer or specimen types due to domain shifts - these cancer types were rarely used for pretraining or specimens contain tissue-based artifacts rarely seen within the pretraining population. Such is the case for transurethral resection of bladder tumor (TURBT), which are essential for diagnosing muscle-invasive bladder cancer (MIBC), but contain fragmented tissue chips and electrocautery artifacts and were not widely used in publicly available PFMs. To address this, we propose a simple yet effective domain-adaptive self-supervised adaptor (DA-SSL) that realigns pretrained PFM features to the TURBT domain without fine-tuning the foundational model itself. We pilot this framework for predicting treatment response in TURBT, where histomorphological features are currently underutilized and identifying patients who will benefit from neoadjuvant chemotherapy (NAC) is challenging. In our multi-center study, DA-SSL achieved an AUC of 0.77+/-0.04 in five-fold cross-validation and an external test accuracy of 0.84, sensitivity of 0.71, and specificity of 0.91 using majority voting. Our results demonstrate that lightweight domain adaptation with self-supervision can effectively enhance PFM-based MIL pipelines for clinically challenging histopathology tasks. Code is Available at https://github.com/zhanghaoyue/DA_SSL_TURBT.
Source-Free Bistable Fluidic Gripper for Size-Selective and Stiffness-Adaptive Grasping
Nov 05, 2025Conventional fluid-driven soft grippers typically depend on external sources, which limit portability and long-term autonomy. This work introduces a self-contained soft gripper with fixed size that operates solely through internal liquid redistribution among three interconnected bistable snap-through chambers. When the top sensing chamber deforms upon contact, the displaced liquid triggers snap-through expansion of the grasping chambers, enabling stable and size-selective grasping without continuous energy input. The internal hydraulic feedback further allows passive adaptation of gripping pressure to object stiffness. This source-free and compact design opens new possibilities for lightweight, stiffness-adaptive fluid-driven manipulation in soft robotics, providing a feasible approach for targeted size-specific sampling and operation in underwater and field environments.
Safety2Drive: Safety-Critical Scenario Benchmark for the Evaluation of Autonomous Driving
May 20, 2025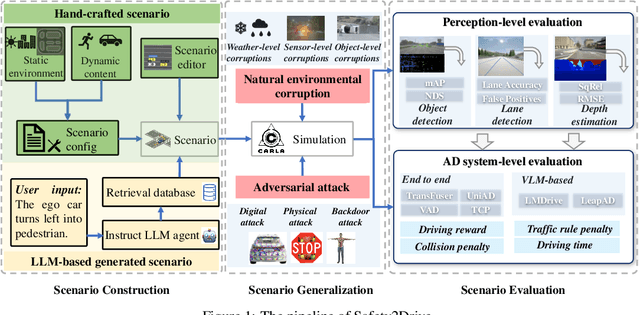

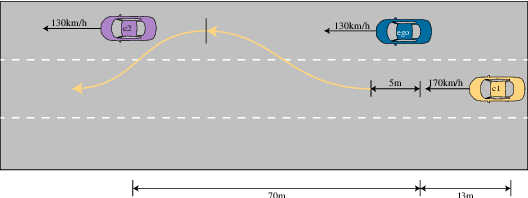
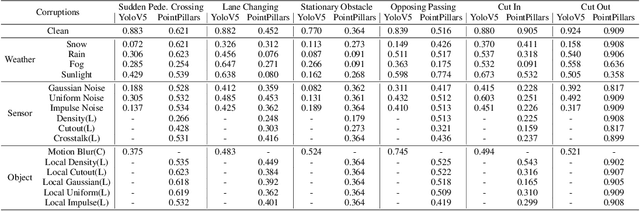
Autonomous Driving (AD) systems demand the high levels of safety assurance. Despite significant advancements in AD demonstrated on open-source benchmarks like Longest6 and Bench2Drive, existing datasets still lack regulatory-compliant scenario libraries for closed-loop testing to comprehensively evaluate the functional safety of AD. Meanwhile, real-world AD accidents are underrepresented in current driving datasets. This scarcity leads to inadequate evaluation of AD performance, posing risks to safety validation and practical deployment. To address these challenges, we propose Safety2Drive, a safety-critical scenario library designed to evaluate AD systems. Safety2Drive offers three key contributions. (1) Safety2Drive comprehensively covers the test items required by standard regulations and contains 70 AD function test items. (2) Safety2Drive supports the safety-critical scenario generalization. It has the ability to inject safety threats such as natural environment corruptions and adversarial attacks cross camera and LiDAR sensors. (3) Safety2Drive supports multi-dimensional evaluation. In addition to the evaluation of AD systems, it also supports the evaluation of various perception tasks, such as object detection and lane detection. Safety2Drive provides a paradigm from scenario construction to validation, establishing a standardized test framework for the safe deployment of AD.
Privacy-Preserving Federated Embedding Learning for Localized Retrieval-Augmented Generation
Apr 27, 2025Retrieval-Augmented Generation (RAG) has recently emerged as a promising solution for enhancing the accuracy and credibility of Large Language Models (LLMs), particularly in Question & Answer tasks. This is achieved by incorporating proprietary and private data from integrated databases. However, private RAG systems face significant challenges due to the scarcity of private domain data and critical data privacy issues. These obstacles impede the deployment of private RAG systems, as developing privacy-preserving RAG systems requires a delicate balance between data security and data availability. To address these challenges, we regard federated learning (FL) as a highly promising technology for privacy-preserving RAG services. We propose a novel framework called Federated Retrieval-Augmented Generation (FedE4RAG). This framework facilitates collaborative training of client-side RAG retrieval models. The parameters of these models are aggregated and distributed on a central-server, ensuring data privacy without direct sharing of raw data. In FedE4RAG, knowledge distillation is employed for communication between the server and client models. This technique improves the generalization of local RAG retrievers during the federated learning process. Additionally, we apply homomorphic encryption within federated learning to safeguard model parameters and mitigate concerns related to data leakage. Extensive experiments conducted on the real-world dataset have validated the effectiveness of FedE4RAG. The results demonstrate that our proposed framework can markedly enhance the performance of private RAG systems while maintaining robust data privacy protection.
Towards Benchmarking and Assessing the Safety and Robustness of Autonomous Driving on Safety-critical Scenarios
Mar 31, 2025



Autonomous driving has made significant progress in both academia and industry, including performance improvements in perception task and the development of end-to-end autonomous driving systems. However, the safety and robustness assessment of autonomous driving has not received sufficient attention. Current evaluations of autonomous driving are typically conducted in natural driving scenarios. However, many accidents often occur in edge cases, also known as safety-critical scenarios. These safety-critical scenarios are difficult to collect, and there is currently no clear definition of what constitutes a safety-critical scenario. In this work, we explore the safety and robustness of autonomous driving in safety-critical scenarios. First, we provide a definition of safety-critical scenarios, including static traffic scenarios such as adversarial attack scenarios and natural distribution shifts, as well as dynamic traffic scenarios such as accident scenarios. Then, we develop an autonomous driving safety testing platform to comprehensively evaluate autonomous driving systems, encompassing not only the assessment of perception modules but also system-level evaluations. Our work systematically constructs a safety verification process for autonomous driving, providing technical support for the industry to establish standardized test framework and reduce risks in real-world road deployment.