 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Select: Query-Aware Adaptive Dimension Selection for Dense Retrieval
Feb 03, 2026Dense retrieval represents queries and docu-002 ments as high-dimensional embeddings, but003 these representations can be redundant at the004 query level: for a given information need, only005 a subset of dimensions is consistently help-006 ful for ranking. Prior work addresses this via007 pseudo-relevance feedback (PRF) based dimen-008 sion importance estimation, which can produce009 query-aware masks without labeled data but010 often relies on noisy pseudo signals and heuris-011 tic test-time procedures. In contrast, super-012 vised adapter methods leverage relevance labels013 to improve embedding quality, yet they learn014 global transformations shared across queries015 and do not explicitly model query-aware di-016 mension importance. We propose a Query-017 Aware Adaptive Dimension Selection frame-018 work that learns to predict per-dimension im-019 portance directly from query embedding. We020 first construct oracle dimension importance dis-021 tributions over embedding dimensions using022 supervised relevance labels, and then train a023 predictor to map a query embedding to these024 label-distilled importance scores. At inference,025 the predictor selects a query-aware subset of026 dimensions for similarity computation based027 solely on the query embedding, without pseudo-028 relevance feedback. Experiments across multi-029 ple dense retrievers and benchmarks show that030 our learned dimension selector improves re-031 trieval effectiveness over the full-dimensional032 baseline as well as PRF-based masking and033 supervised adapter baselines.
AR-BENCH: Benchmarking Legal Reasoning with Judgment Error Detection, Classification and Correction
Jan 30, 2026Legal judgments may contain errors due to the complexity of case circumstances and the abstract nature of legal concepts, while existing appellate review mechanisms face efficiency pressures from a surge in case volumes. Although current legal AI research focuses on tasks like judgment prediction and legal document generation, the task of judgment review differs fundamentally in its objectives and paradigm: it centers on detecting, classifying, and correcting errors after a judgment is issued, constituting anomaly detection rather than prediction or generation. To address this research gap, we introduce a novel task APPELLATE REVIEW, aiming to assess models' diagnostic reasoning and reliability in legal practice. We also construct a novel dataset benchmark AR-BENCH, which comprises 8,700 finely annotated decisions and 34,617 supplementary corpora. By evaluating 14 large language models, we reveal critical limitations in existing models' ability to identify legal application errors, providing empirical evidence for future improvements.
inversedMixup: Data Augmentation via Inverting Mixed Embeddings
Jan 29, 2026Mixup generates augmented samples by linearly interpolating inputs and labels with a controllable ratio. However, since it operates in the latent embedding level, the resulting samples are not human-interpretable. In contrast, LLM-based augmentation methods produce sentences via prompts at the token level, yielding readable outputs but offering limited control over the generation process. Inspired by recent advances in LLM inversion, which reconstructs natural language from embeddings and helps bridge the gap between latent embedding space and discrete token space, we propose inversedMixup, a unified framework that combines the controllability of Mixup with the interpretability of LLM-based generation. Specifically, inversedMixup adopts a three-stage training procedure to align the output embedding space of a task-specific model with the input embedding space of an LLM. Upon successful alignment, inversedMixup can reconstruct mixed embeddings with a controllable mixing ratio into human-interpretable augmented sentences, thereby improving the augmentation performance. Additionally, inversedMixup provides the first empirical evidence of the manifold intrusion phenomenon in text Mixup and introduces a simple yet effective strategy to mitigate it. Extensive experiments demonstrate the effectiveness and generalizability of our approach in both few-shot and fully supervised scenarios.
Rethinking Label Consistency of In-Context Learning: An Implicit Transductive Label Propagation Perspective
Dec 13, 2025Large language models (LLMs) perform in-context learning (ICL) with minimal supervised examples, which benefits various natural language processing (NLP) tasks. One of the critical research focus is the selection of prompt demonstrations. Current approaches typically employ retrieval models to select the top-K most semantically similar examples as demonstrations. However, we argue that existing methods are limited since the label consistency is not guaranteed during demonstration selection. Our cognition derives from the Bayesian view of ICL and our rethinking of ICL from the transductive label propagation perspective. We treat ICL as a transductive learning method and incorporate latent concepts from Bayesian view and deduce that similar demonstrations guide the concepts of query, with consistent labels serving as estimates. Based on this understanding, we establish a label propagation framework to link label consistency with propagation error bounds. To model label consistency, we propose a data synthesis method, leveraging both semantic and label information, and use TopK sampling with Synthetic Data (TopK-SD) to acquire demonstrations with consistent labels. TopK-SD outperforms original TopK sampling on multiple benchmarks. Our work provides a new perspective for understanding the working mechanisms within ICL.
Improving Subgraph Matching by Combining Algorithms and Graph Neural Networks
Jul 27, 2025Homomorphism is a key mapping technique between graphs that preserves their structure. Given a graph and a pattern, the subgraph homomorphism problem involves finding a mapping from the pattern to the graph, ensuring that adjacent vertices in the pattern are mapped to adjacent vertices in the graph. Unlike subgraph isomorphism, which requires a one-to-one mapping, homomorphism allows multiple vertices in the pattern to map to the same vertex in the graph, making it more complex. We propose HFrame, the first graph neural network-based framework for subgraph homomorphism, which integrates traditional algorithms with machine learning techniques. We demonstrate that HFrame outperforms standard graph neural networks by being able to distinguish more graph pairs where the pattern is not homomorphic to the graph. Additionally, we provide a generalization error bound for HFrame. Through experiments on both real-world and synthetic graphs, we show that HFrame is up to 101.91 times faster than exact matching algorithms and achieves an average accuracy of 0.962.
General Table Question Answering via Answer-Formula Joint Generation
Mar 16, 2025Advanced table question answering (TableQA) methods prompt large language models (LLMs) to generate answer text, SQL query, Python code, or custom operations, which impressively improve the complex reasoning problems in the TableQA task. However, these methods lack the versatility to cope with specific question types or table structures. In contrast, the Spreadsheet Formula, the widely-used and well-defined operation language for tabular data, has not been thoroughly explored to solve TableQA. In this paper, we first attempt to use Formula as the logical form for solving complex reasoning on the tables with different structures. Specifically, we construct a large Formula-annotated TableQA dataset \texttt{FromulaQA} from existing datasets. In addition, we propose \texttt{TabAF}, a general table answering framework to solve multiple types of tasks over multiple types of tables simultaneously. Unlike existing methods, \texttt{TabAF} decodes answers and Formulas with a single LLM backbone, demonstrating great versatility and generalization. \texttt{TabAF} based on Llama3.1-70B achieves new state-of-the-art performance on the WikiTableQuestion, HiTab and TabFact.
Lost-in-the-Middle in Long-Text Generation: Synthetic Dataset, Evaluation Framework, and Mitigation
Mar 10, 2025Existing long-text generation methods primarily concentrate on producing lengthy texts from short inputs, neglecting the long-input and long-output tasks. Such tasks have numerous practical applications while lacking available benchmarks. Moreover, as the input grows in length, existing methods inevitably encounter the "lost-in-the-middle" phenomenon. In this paper, we first introduce a Long Input and Output Benchmark (LongInOutBench), including a synthetic dataset and a comprehensive evaluation framework, addressing the challenge of the missing benchmark. We then develop the Retrieval-Augmented Long-Text Writer (RAL-Writer), which retrieves and restates important yet overlooked content, mitigating the "lost-in-the-middle" issue by constructing explicit prompts. We finally employ the proposed LongInOutBench to evaluate our RAL-Writer against comparable baselines, and the results demonstrate the effectiveness of our approach. Our code has been released at https://github.com/OnlyAR/RAL-Writer.
A Graph-based Verification Framework for Fact-Checking
Mar 10, 2025Fact-checking plays a crucial role in combating misinformation. Existing methods using large language models (LLMs) for claim decomposition face two key limitations: (1) insufficient decomposition, introducing unnecessary complexity to the verification process, and (2) ambiguity of mentions, leading to incorrect verification results. To address these challenges, we suggest introducing a claim graph consisting of triplets to address the insufficient decomposition problem and reduce mention ambiguity through graph structure. Based on this core idea, we propose a graph-based framework, GraphFC, for fact-checking. The framework features three key components: graph construction, which builds both claim and evidence graphs; graph-guided planning, which prioritizes the triplet verification order; and graph-guided checking, which verifies the triples one by one between claim and evidence graphs. Extensive experiments show that GraphFC enables fine-grained decomposition while resolving referential ambiguities through relational constraints, achieving state-of-the-art performance across three datasets.
Implicit Word Reordering with Knowledge Distillation for Cross-Lingual Dependency Parsing
Feb 24, 2025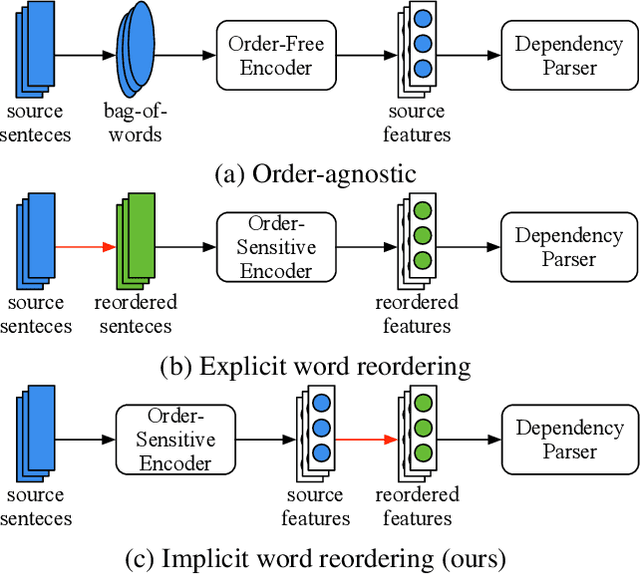

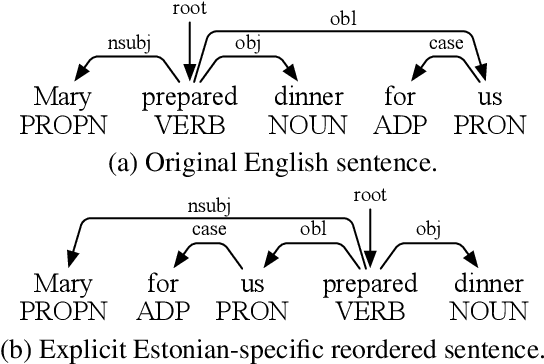

Word order difference between source and target languages is a major obstacle to cross-lingual transfer, especially in the dependency parsing task. Current works are mostly based on order-agnostic models or word reordering to mitigate this problem. However, such methods either do not leverage grammatical information naturally contained in word order or are computationally expensive as the permutation space grows exponentially with the sentence length. Moreover, the reordered source sentence with an unnatural word order may be a form of noising that harms the model learning. To this end, we propose an Implicit Word Reordering framework with Knowledge Distillation (IWR-KD). This framework is inspired by that deep networks are good at learning feature linearization corresponding to meaningful data transformation, e.g. word reordering. To realize this idea, we introduce a knowledge distillation framework composed of a word-reordering teacher model and a dependency parsing student model. We verify our proposed method on Universal Dependency Treebanks across 31 different languages and show it outperforms a series of competitors, together with experimental analysis to illustrate how our method works towards training a robust parser.
XRAG: eXamining the Core -- Benchmarking Foundational Components in Advanced Retrieval-Augmented Generation
Dec 24, 2024Retrieval-augmented generation (RAG) synergizes the retrieval of pertinent data with the generative capabilities of Large Language Models (LLMs), ensuring that the generated output is not only contextually relevant but also accurate and current. We introduce XRAG, an open-source, modular codebase that facilitates exhaustive evaluation of the performance of foundational components of advanced RAG modules. These components are systematically categorized into four core phases: pre-retrieval, retrieval, post-retrieval, and generation. We systematically analyse them across reconfigured datasets, providing a comprehensive benchmark for their effectiveness. As the complexity of RAG systems continues to escalate, we underscore the critical need to identify potential failure points in RAG systems. We formulate a suite of experimental methodologies and diagnostic testing protocols to dissect the failure points inherent in RAG engineering. Subsequently, we proffer bespoke solutions aimed at bolstering the overall performance of these modules. Our work thoroughly evaluates the performance of advanced core components in RAG systems, providing insights into optimizations for prevalent failure points.