 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy-Guided Data-Efficient Training for Multimodal Reasoning Reward Models
Feb 02, 2026Multimodal reward models are crucial for aligning multimodal large language models with human preferences. Recent works have incorporated reasoning capabilities into these models, achieving promising results. However, training these models suffers from two critical challenges: (1) the inherent noise in preference datasets, which degrades model performance, and (2) the inefficiency of conventional training methods, which ignore the differences in sample difficulty. In this paper, we identify a strong correlation between response entropy and accuracy, indicating that entropy can serve as a reliable and unsupervised proxy for annotation noise and sample difficulty. Based on this insight, we propose a novel Entropy-Guided Training (EGT) approach for multimodal reasoning reward models, which combines two strategies: (1) entropy-guided data curation to mitigate the impact of unreliable samples, and (2) an entropy-guided training strategy that progressively introduces more complex examples. Extensive experiments across three benchmarks show that the EGT-trained model consistently outperforms state-of-the-art multimodal reward models.
MMGenBench: Evaluating the Limits of LMMs from the Text-to-Image Generation Perspective
Nov 21, 2024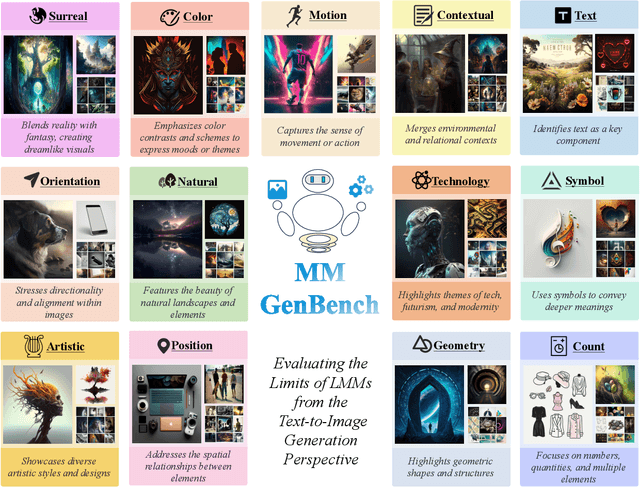
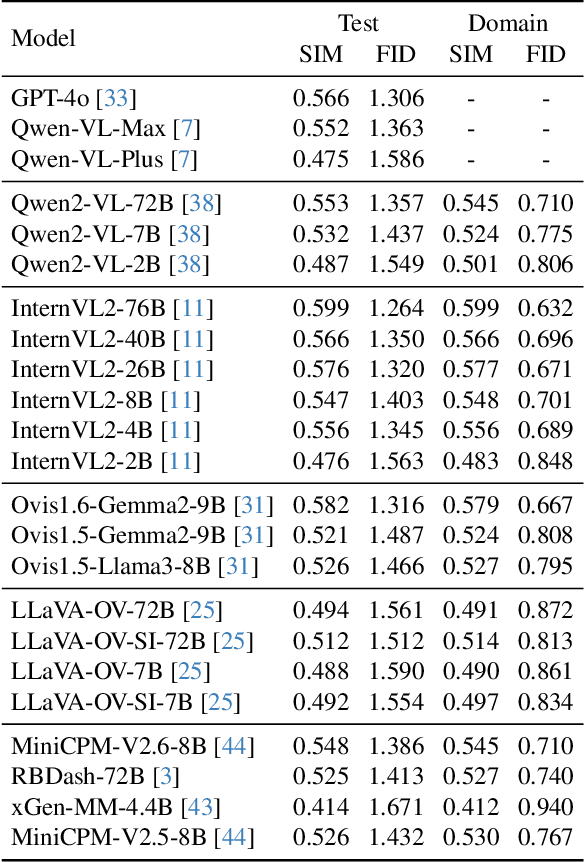
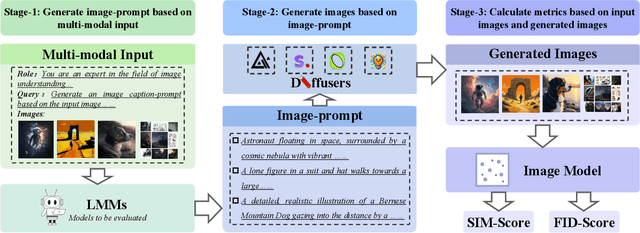
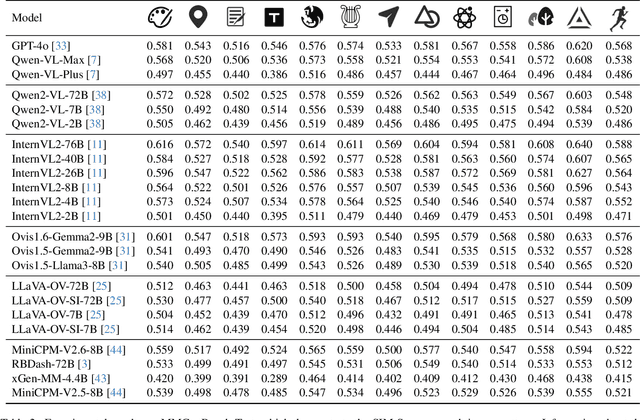
Large Multimodal Models (LMMs) have demonstrated remarkable capabilities. While existing benchmarks for evaluating LMMs mainly focus on image comprehension, few works evaluate them from the image generation perspective. To address this issue, we propose a straightforward automated evaluation pipeline. Specifically, this pipeline requires LMMs to generate an image-prompt from a given input image. Subsequently, it employs text-to-image generative models to create a new image based on these generated prompts. Finally, we evaluate the performance of LMMs by comparing the original image with the generated one. Furthermore, we introduce MMGenBench-Test, a comprehensive benchmark developed to evaluate LMMs across 13 distinct image patterns, and MMGenBench-Domain, targeting the performance evaluation of LMMs within the generative image domain. A thorough evaluation involving over 50 popular LMMs demonstrates the effectiveness and reliability in both the pipeline and benchmark. Our observations indicate that numerous LMMs excelling in existing benchmarks fail to adequately complete the basic tasks, related to image understanding and description. This finding highlights the substantial potential for performance improvement in current LMMs and suggests avenues for future model optimization. Concurrently, our pipeline facilitates the efficient assessment of LMMs performance across diverse domains by using solely image inputs.
Finding Similar Exercises in Retrieval Manner
Mar 15, 2023When students make a mistake in an exercise, they can consolidate it by ``similar exercises'' which have the same concepts, purposes and methods. Commonly, for a certain subject and study stage, the size of the exercise bank is in the range of millions to even tens of millions, how to find similar exercises for a given exercise becomes a crucial technical problem. Generally, we can assign a variety of explicit labels to the exercise, and then query through the labels, but the label annotation is time-consuming, laborious and costly, with limited precision and granularity, so it is not feasible. In practice, we define ``similar exercises'' as a retrieval process of finding a set of similar exercises based on recall, ranking and re-rank procedures, called the \textbf{FSE} problem (Finding similar exercises). Furthermore, comprehensive representation of the semantic information of exercises was obtained through representation learning. In addition to the reasonable architecture, we also explore what kind of tasks are more conducive to the learning of exercise semantic information from pre-training and supervised learning. It is difficult to annotate similar exercises and the annotation consistency among experts is low. Therefore this paper also provides solutions to solve the problem of low-quality annotated data. Compared with other methods, this paper has obvious advantages in both architecture rationality and algorithm precision, which now serves the daily teaching of hundreds of schools.
* 37th Conference on AAAI 2023 Artificial Intelligence for Education(AI4Edu)
An Empirical Study of Finding Similar Exercises
Nov 16, 2021



Education artificial intelligence aims to profit tasks in the education domain such as intelligent test paper generation and consolidation exercises where the main technique behind is how to match the exercises, known as the finding similar exercises(FSE) problem. Most of these approaches emphasized their model abilities to represent the exercise, unfortunately there are still many challenges such as the scarcity of data, insufficient understanding of exercises and high label noises. We release a Chinese education pre-trained language model BERT$_{Edu}$ for the label-scarce dataset and introduce the exercise normalization to overcome the diversity of mathematical formulas and terms in exercise. We discover new auxiliary tasks in an innovative way depends on problem-solving ideas and propose a very effective MoE enhanced multi-task model for FSE task to attain better understanding of exercises. In addition, confidence learning was utilized to prune train-set and overcome high noises in labeling data. Experiments show that these methods proposed in this paper are very effective.
* 35th Conference on Neural Information Processing Systems (NeurIPS 2021) Workshop on Math AI for Education(MATHAI4ED)
BoostingBERT:Integrating Multi-Class Boosting into BERT for NLP Tasks
Sep 13, 2020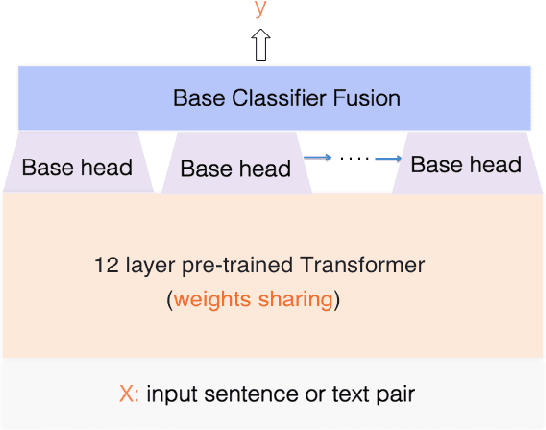



As a pre-trained Transformer model, BERT (Bidirectional Encoder Representations from Transformers) has achieved ground-breaking performance on multiple NLP tasks. On the other hand, Boosting is a popular ensemble learning technique which combines many base classifiers and has been demonstrated to yield better generalization performance in many machine learning tasks. Some works have indicated that ensemble of BERT can further improve the application performance. However, current ensemble approaches focus on bagging or stacking and there has not been much effort on exploring the boosting. In this work, we proposed a novel Boosting BERT model to integrate multi-class boosting into the BERT. Our proposed model uses the pre-trained Transformer as the base classifier to choose harder training sets to fine-tune and gains the benefits of both the pre-training language knowledge and boosting ensemble in NLP tasks. We evaluate the proposed model on the GLUE dataset and 3 popular Chinese NLU benchmarks. Experimental results demonstrate that our proposed model significantly outperforms BERT on all datasets and proves its effectiveness in many NLP tasks. Replacing the BERT base with RoBERTa as base classifier, BoostingBERT achieves new state-of-the-art results in several NLP Tasks. We also use knowledge distillation within the "teacher-student" framework to reduce the computational overhead and model storage of BoostingBERT while keeping its performance for practical application.
GateNet: Gating-Enhanced Deep Network for Click-Through Rate Prediction
Jul 06, 2020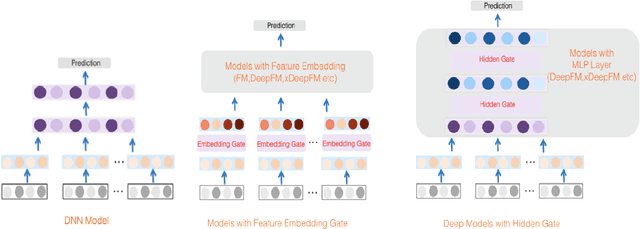
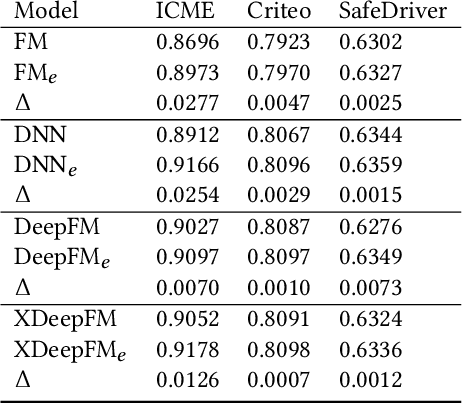
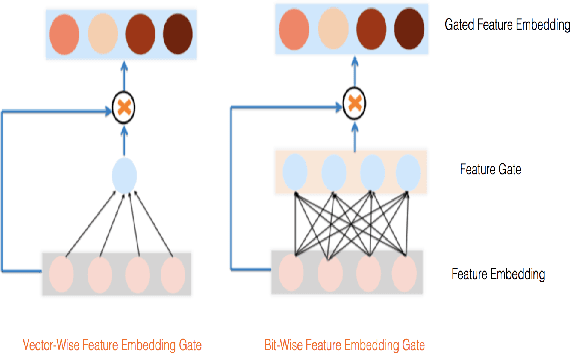
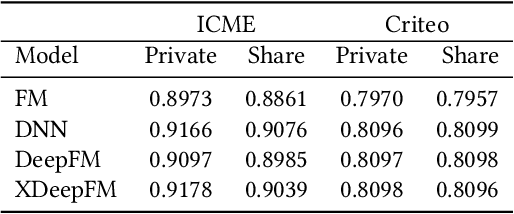
Advertising and feed ranking are essential to many Internet companies such as Facebook. Among many real-world advertising and feed ranking systems, click through rate (CTR) prediction plays a central role. In recent years, many neural network based CTR models have been proposed and achieved success such as Factorization-Machine Supported Neural Networks, DeepFM and xDeepFM. Many of them contain two commonly used components: embedding layer and MLP hidden layers. On the other side, gating mechanism is also widely applied in many research fields such as computer vision(CV) and natural language processing(NLP). Some research has proved that gating mechanism improves the trainability of non-convex deep neural networks. Inspired by these observations, we propose a novel model named GateNet which introduces either the feature embedding gate or the hidden gate to the embedding layer or hidden layers of DNN CTR models, respectively. The feature embedding gate provides a learnable feature gating module to select salient latent information from the feature-level. The hidden gate helps the model to implicitly capture the high-order interaction more effectively. Extensive experiments conducted on three real-world datasets demonstrate its effectiveness to boost the performance of various state-of-the-art models such as FM, DeepFM and xDeepFM on all datasets.
FiBiNET: Combining Feature Importance and Bilinear feature Interaction for Click-Through Rate Prediction
May 23, 2019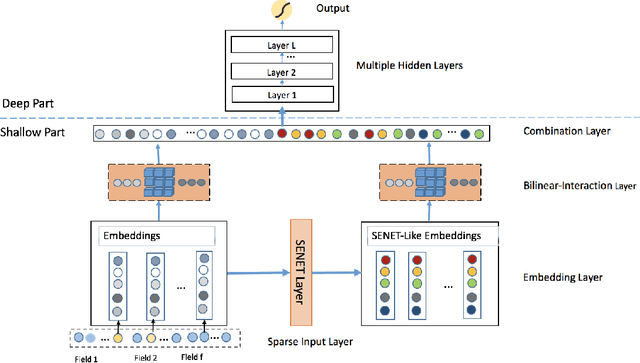

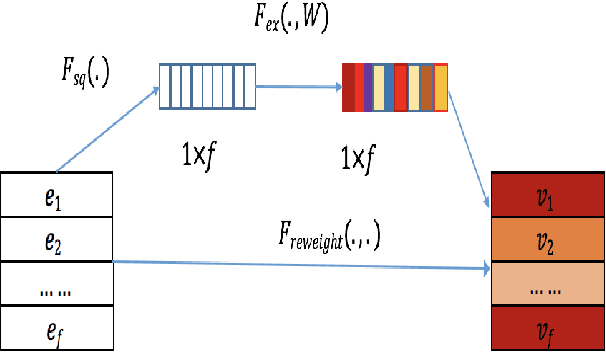

Advertising and feed ranking are essential to many Internet companies such as Facebook and Sina Weibo. Among many real-world advertising and feed ranking systems, click through rate (CTR) prediction plays a central role. There are many proposed models in this field such as logistic regression, tree based models, factorization machine based models and deep learning based CTR models. However, many current works calculate the feature interactions in a simple way such as Hadamard product and inner product and they care less about the importance of features. In this paper, a new model named FiBiNET as an abbreviation for Feature Importance and Bilinear feature Interaction NETwork is proposed to dynamically learn the feature importance and fine-grained feature interactions. On the one hand, the FiBiNET can dynamically learn the importance of features via the Squeeze-Excitation network (SENET) mechanism; on the other hand, it is able to effectively learn the feature interactions via bilinear function. We conduct extensive experiments on two real-world datasets and show that our shallow model outperforms other shallow models such as factorization machine(FM) and field-aware factorization machine(FFM). In order to improve performance further, we combine a classical deep neural network(DNN) component with the shallow model to be a deep model. The deep FiBiNET consistently outperforms the other state-of-the-art deep models such as DeepFM and extreme deep factorization machine(XdeepFM).
FAT-DeepFFM: Field Attentive Deep Field-aware Factorization Machine
May 15, 2019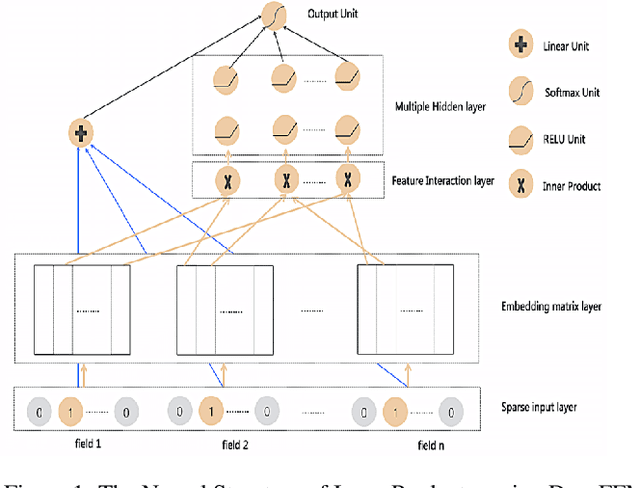



Click through rate (CTR) estimation is a fundamental task in personalized advertising and recommender systems. Recent years have witnessed the success of both the deep learning based model and attention mechanism in various tasks in computer vision (CV) and natural language processing (NLP). How to combine the attention mechanism with deep CTR model is a promising direction because it may ensemble the advantages of both sides. Although some CTR model such as Attentional Factorization Machine (AFM) has been proposed to model the weight of second order interaction features, we posit the evaluation of feature importance before explicit feature interaction procedure is also important for CTR prediction tasks because the model can learn to selectively highlight the informative features and suppress less useful ones if the task has many input features. In this paper, we propose a new neural CTR model named Field Attentive Deep Field-aware Factorization Machine (FAT-DeepFFM) by combining the Deep Field-aware Factorization Machine (DeepFFM) with Compose-Excitation network (CENet) field attention mechanism which is proposed by us as an enhanced version of Squeeze-Excitation network (SENet) to highlight the feature importance. We conduct extensive experiments on two real-world datasets and the experiment results show that FAT-DeepFFM achieves the best performance and obtains different improvements over the state-of-the-art methods. We also compare two kinds of attention mechanisms (attention before explicit feature interaction vs. attention after explicit feature interaction) and demonstrate that the former one outperforms the latter one significantly.