 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoostingBERT:Integrating Multi-Class Boosting into BERT for NLP Tasks
Paper and Code
Sep 13, 2020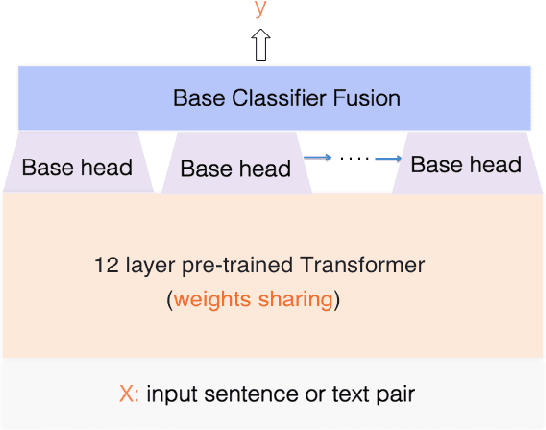



As a pre-trained Transformer model, BERT (Bidirectional Encoder Representations from Transformers) has achieved ground-breaking performance on multiple NLP tasks. On the other hand, Boosting is a popular ensemble learning technique which combines many base classifiers and has been demonstrated to yield better generalization performance in many machine learning tasks. Some works have indicated that ensemble of BERT can further improve the application performance. However, current ensemble approaches focus on bagging or stacking and there has not been much effort on exploring the boosting. In this work, we proposed a novel Boosting BERT model to integrate multi-class boosting into the BERT. Our proposed model uses the pre-trained Transformer as the base classifier to choose harder training sets to fine-tune and gains the benefits of both the pre-training language knowledge and boosting ensemble in NLP tasks. We evaluate the proposed model on the GLUE dataset and 3 popular Chinese NLU benchmarks. Experimental results demonstrate that our proposed model significantly outperforms BERT on all datasets and proves its effectiveness in many NLP tasks. Replacing the BERT base with RoBERTa as base classifier, BoostingBERT achieves new state-of-the-art results in several NLP Tasks. We also use knowledge distillation within the "teacher-student" framework to reduce the computational overhead and model storage of BoostingBERT while keeping its performance for practical application.