 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextNet: A Click-Through Rate Prediction Framework Using Contextual information to Refine Feature Embedding
Jul 26, 2021
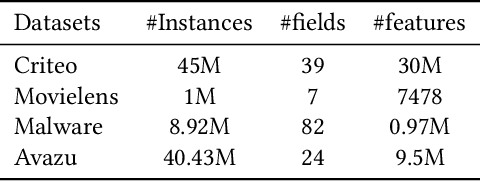
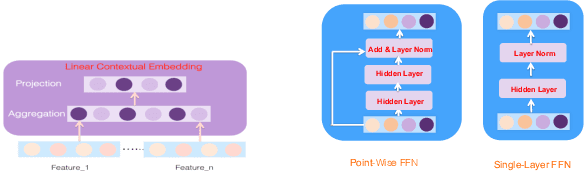
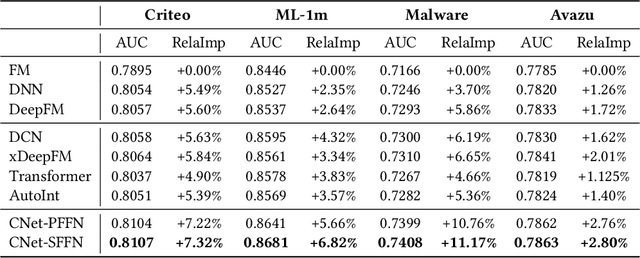
Click-through rate (CTR) estimation is a fundamental task in personalized advertising and recommender systems and it's important for ranking models to effectively capture complex high-order features.Inspired by the success of ELMO and Bert in NLP field, which dynamically refine word embedding according to the context sentence information where the word appears, we think it's also important to dynamically refine each feature's embedding layer by layer according to the context information contained in input instance in CTR estimation tasks. We can effectively capture the useful feature interactions for each feature in this way. In this paper, We propose a novel CTR Framework named ContextNet that implicitly models high-order feature interactions by dynamically refining each feature's embedding according to the input context. Specifically, ContextNet consists of two key components: contextual embedding module and ContextNet block. Contextual embedding module aggregates contextual information for each feature from input instance and ContextNet block maintains each feature's embedding layer by layer and dynamically refines its representation by merging contextual high-order interaction information into feature embedding. To make the framework specific, we also propose two models(ContextNet-PFFN and ContextNet-SFFN) under this framework by introducing linear contextual embedding network and two non-linear mapping sub-network in ContextNet block. We conduct extensive experiments on four real-world datasets and the experiment results demonstrate that our proposed ContextNet-PFFN and ContextNet-SFFN model outperform state-of-the-art models such as DeepFM and xDeepFM significantly.
Leaf-FM: A Learnable Feature Generation Factorization Machine for Click-Through Rate Prediction
Jul 26, 2021

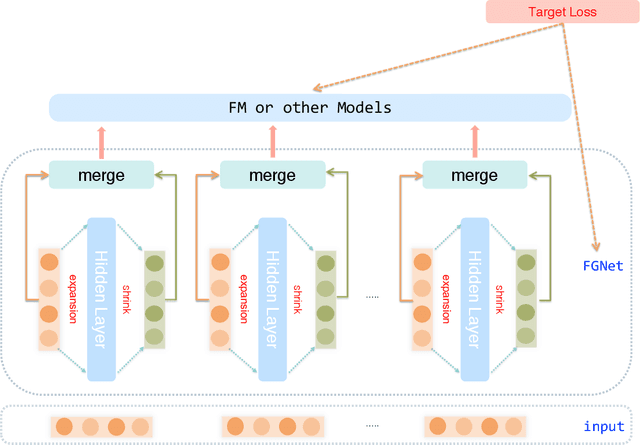
Click-through rate (CTR) prediction plays important role in personalized advertising and recommender systems. Though many models have been proposed such as FM, FFM and DeepFM in recent years, feature engineering is still a very important way to improve the model performance in many applications because using raw features can rarely lead to optimal results. For example, the continuous features are usually transformed to the power forms by adding a new feature to allow it to easily form non-linear functions of the feature. However, this kind of feature engineering heavily relies on peoples experience and it is both time consuming and labor consuming. On the other side, concise CTR model with both fast online serving speed and good model performance is critical for many real life applications. In this paper, we propose LeafFM model based on FM to generate new features from the original feature embedding by learning the transformation functions automatically. We also design three concrete Leaf-FM models according to the different strategies of combing the original and the generated features. Extensive experiments are conducted on three real-world datasets and the results show Leaf-FM model outperforms standard FMs by a large margin. Compared with FFMs, Leaf-FM can achieve significantly better performance with much less parameters. In Avazu and Malware dataset, add version Leaf-FM achieves comparable performance with some deep learning based models such as DNN and AutoInt. As an improved FM model, Leaf-FM has the same computation complexity with FM in online serving phase and it means Leaf-FM is applicable in many industry applications because of its better performance and high computation efficiency.
MaskNet: Introducing Feature-Wise Multiplication to CTR Ranking Models by Instance-Guided Mask
Feb 09, 2021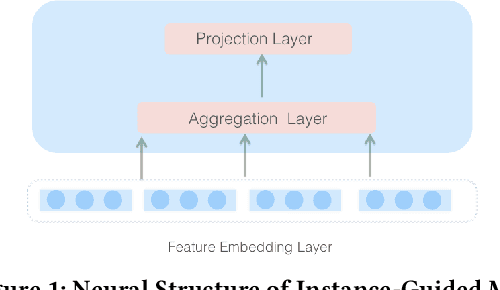

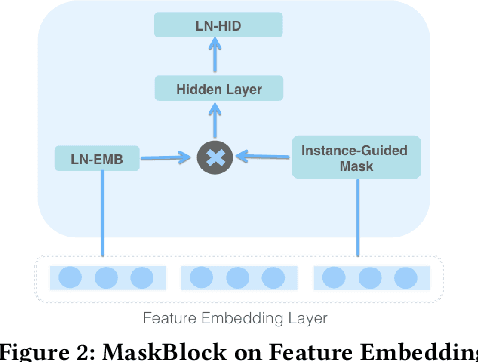
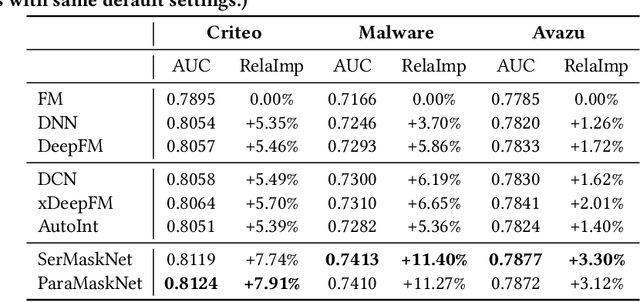
Click-Through Rate(CTR) estimation has become one of the most fundamental tasks in many real-world applications and it's important for ranking models to effectively capture complex high-order features. Shallow feed-forward network is widely used in many state-of-the-art DNN models such as FNN, DeepFM and xDeepFM to implicitly capture high-order feature interactions. However, some research has proved that addictive feature interaction, particular feed-forward neural networks, is inefficient in capturing common feature interaction. To resolve this problem, we introduce specific multiplicative operation into DNN ranking system by proposing instance-guided mask which performs element-wise product both on the feature embedding and feed-forward layers guided by input instance. We also turn the feed-forward layer in DNN model into a mixture of addictive and multiplicative feature interactions by proposing MaskBlock in this paper. MaskBlock combines the layer normalization, instance-guided mask, and feed-forward layer and it is a basic building block to be used to design new ranking model under various configurations. The model consisting of MaskBlock is called MaskNet in this paper and two new MaskNet models are proposed to show the effectiveness of MaskBlock as basic building block for composing high performance ranking systems. The experiment results on three real-world datasets demonstrate that our proposed MaskNet models outperform state-of-the-art models such as DeepFM and xDeepFM significantly, which implies MaskBlock is an effective basic building unit for composing new high performance ranking systems.
BoostingBERT:Integrating Multi-Class Boosting into BERT for NLP Tasks
Sep 13, 2020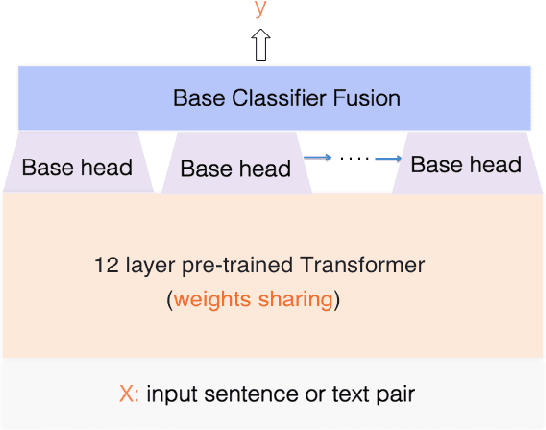



As a pre-trained Transformer model, BERT (Bidirectional Encoder Representations from Transformers) has achieved ground-breaking performance on multiple NLP tasks. On the other hand, Boosting is a popular ensemble learning technique which combines many base classifiers and has been demonstrated to yield better generalization performance in many machine learning tasks. Some works have indicated that ensemble of BERT can further improve the application performance. However, current ensemble approaches focus on bagging or stacking and there has not been much effort on exploring the boosting. In this work, we proposed a novel Boosting BERT model to integrate multi-class boosting into the BERT. Our proposed model uses the pre-trained Transformer as the base classifier to choose harder training sets to fine-tune and gains the benefits of both the pre-training language knowledge and boosting ensemble in NLP tasks. We evaluate the proposed model on the GLUE dataset and 3 popular Chinese NLU benchmarks. Experimental results demonstrate that our proposed model significantly outperforms BERT on all datasets and proves its effectiveness in many NLP tasks. Replacing the BERT base with RoBERTa as base classifier, BoostingBERT achieves new state-of-the-art results in several NLP Tasks. We also use knowledge distillation within the "teacher-student" framework to reduce the computational overhead and model storage of BoostingBERT while keeping its performance for practical application.
Correct Normalization Matters: Understanding the Effect of Normalization On Deep Neural Network Models For Click-Through Rate Prediction
Jul 07, 2020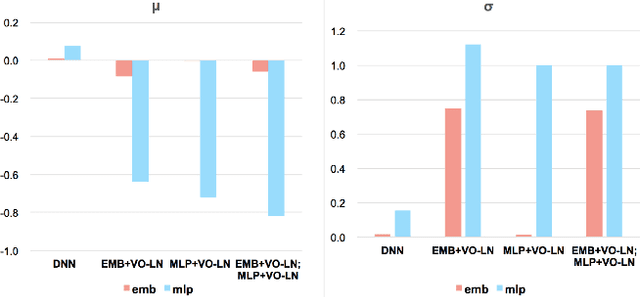

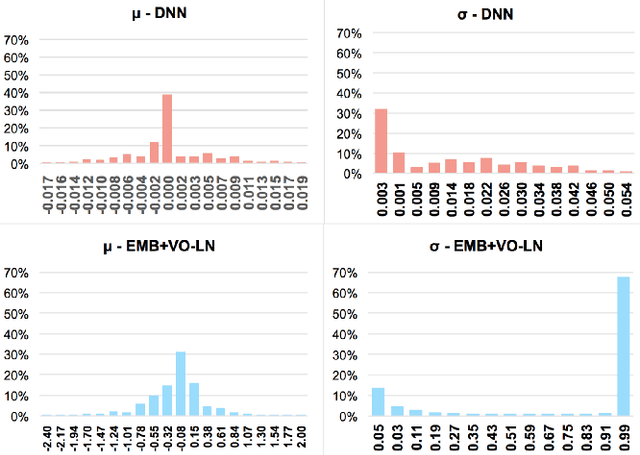

Normalization has become one of the most fundamental components in many deep neural networks for machine learning tasks while deep neural network has also been widely used in CTR estimation field. Among most of the proposed deep neural network models, few model utilize normalization approaches. Though some works such as Deep & Cross Network (DCN) and Neural Factorization Machine (NFM) use Batch Normalization in MLP part of the structure, there isn't work to thoroughly explore the effect of the normalization on the DNN ranking systems. In this paper, we conduct a systematic study on the effect of widely used normalization schemas by applying the various normalization approaches to both feature embedding and MLP part in DNN model. Extensive experiments are conduct on three real-world datasets and the experiment results demonstrate that the correct normalization significantly enhances model's performance. We also propose a new and effective normalization approaches based on LayerNorm named variance only LayerNorm(VO-LN) in this work. A normalization enhanced DNN model named NormDNN is also proposed based on the above-mentioned observation. As for the reason why normalization works for DNN models in CTR estimation, we find that the variance of normalization plays the main role and give an explanation in this work.
GateNet: Gating-Enhanced Deep Network for Click-Through Rate Prediction
Jul 06, 2020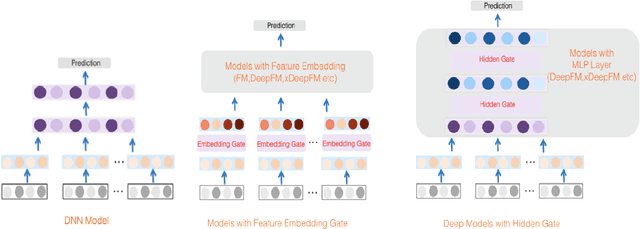
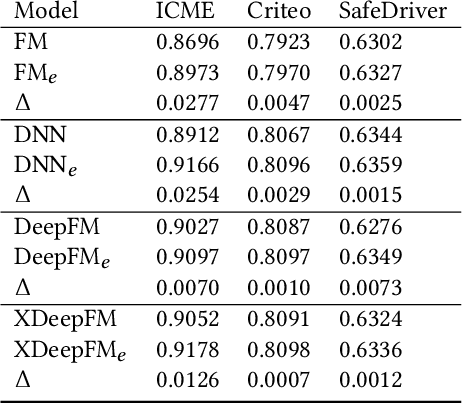
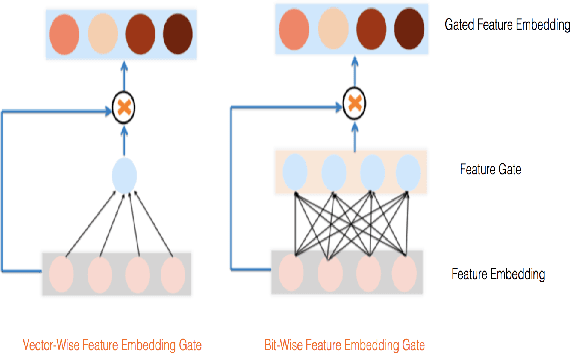
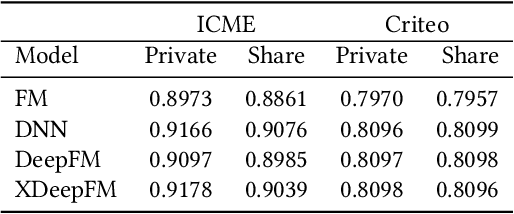
Advertising and feed ranking are essential to many Internet companies such as Facebook. Among many real-world advertising and feed ranking systems, click through rate (CTR) prediction plays a central role. In recent years, many neural network based CTR models have been proposed and achieved success such as Factorization-Machine Supported Neural Networks, DeepFM and xDeepFM. Many of them contain two commonly used components: embedding layer and MLP hidden layers. On the other side, gating mechanism is also widely applied in many research fields such as computer vision(CV) and natural language processing(NLP). Some research has proved that gating mechanism improves the trainability of non-convex deep neural networks. Inspired by these observations, we propose a novel model named GateNet which introduces either the feature embedding gate or the hidden gate to the embedding layer or hidden layers of DNN CTR models, respectively. The feature embedding gate provides a learnable feature gating module to select salient latent information from the feature-level. The hidden gate helps the model to implicitly capture the high-order interaction more effectively. Extensive experiments conducted on three real-world datasets demonstrate its effectiveness to boost the performance of various state-of-the-art models such as FM, DeepFM and xDeepFM on all datasets.