 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Guided and Motion-Aware Gait Representation for Generalizable Recognition
Jan 17, 2026Gait recognition is emerging as a promising technology and an innovative field within computer vision. However, existing methods typically rely on complex architectures to directly extract features from images and apply pooling operations to obtain sequence-level representations. Such designs often lead to overfitting on static noise (e.g., clothing), while failing to effectively capture dynamic motion regions.To address the above challenges, we present a Language guided and Motion-aware gait recognition framework, named LMGait.In particular, we utilize designed gait-related language cues to capture key motion features in gait sequences.
Measuring and Controlling the Spectral Bias for Self-Supervised Image Denoising
Oct 01, 2025Current self-supervised denoising methods for paired noisy images typically involve mapping one noisy image through the network to the other noisy image. However, after measuring the spectral bias of such methods using our proposed Image Pair Frequency-Band Similarity, it suffers from two practical limitations. Firstly, the high-frequency structural details in images are not preserved well enough. Secondly, during the process of fitting high frequencies, the network learns high-frequency noise from the mapped noisy images. To address these challenges, we introduce a Spectral Controlling network (SCNet) to optimize self-supervised denoising of paired noisy images. First, we propose a selection strategy to choose frequency band components for noisy images, to accelerate the convergence speed of training. Next, we present a parameter optimization method that restricts the learning ability of convolutional kernels to high-frequency noise using the Lipschitz constant, without changing the network structure. Finally, we introduce the Spectral Separation and low-rank Reconstruction module (SSR module), which separates noise and high-frequency details through frequency domain separation and low-rank space reconstruction, to retain the high-frequency structural details of images. Experiments performed on synthetic and real-world datasets verify the effectiveness of SCNet.
Interpretable Unsupervised Joint Denoising and Enhancement for Real-World low-light Scenarios
Mar 17, 2025Real-world low-light images often suffer from complex degradations such as local overexposure, low brightness, noise, and uneven illumination. Supervised methods tend to overfit to specific scenarios, while unsupervised methods, though better at generalization, struggle to model these degradations due to the lack of reference images. To address this issue, we propose an interpretable, zero-reference joint denoising and low-light enhancement framework tailored for real-world scenarios. Our method derives a training strategy based on paired sub-images with varying illumination and noise levels, grounded in physical imaging principles and retinex theory. Additionally, we leverage the Discrete Cosine Transform (DCT) to perform frequency domain decomposition in the sRGB space, and introduce an implicit-guided hybrid representation strategy that effectively separates intricate compounded degradations. In the backbone network design, we develop retinal decomposition network guided by implicit degradation representation mechanisms. Extensive experiments demonstrate the superiority of our method. Code will be available at https://github.com/huaqlili/unsupervised-light-enhance-ICLR2025.
Prompt-SID: Learning Structural Representation Prompt via Latent Diffusion for Single-Image Denoising
Feb 10, 2025



Many studies have concentrated on constructing supervised models utilizing paired datasets for image denoising, which proves to be expensive and time-consuming. Current self-supervised and unsupervised approaches typically rely on blind-spot networks or sub-image pairs sampling, resulting in pixel information loss and destruction of detailed structural information, thereby significantly constraining the efficacy of such methods. In this paper, we introduce Prompt-SID, a prompt-learning-based single image denoising framework that emphasizes preserving of structural details. This approach is trained in a self-supervised manner using downsampled image pairs. It captures original-scale image information through structural encoding and integrates this prompt into the denoiser. To achieve this, we propose a structural representation generation model based on the latent diffusion process and design a structural attention module within the transformer-based denoiser architecture to decode the prompt. Additionally, we introduce a scale replay training mechanism, which effectively mitigates the scale gap from images of different resolutions. We conduct comprehensive experiments on synthetic, real-world, and fluorescence imaging datasets, showcasing the remarkable effectiveness of Prompt-SID.
Spatiotemporal Blind-Spot Network with Calibrated Flow Alignment for Self-Supervised Video Denoising
Dec 16, 2024Self-supervised video denoising aims to remove noise from videos without relying on ground truth data, leveraging the video itself to recover clean frames. Existing methods often rely on simplistic feature stacking or apply optical flow without thorough analysis. This results in suboptimal utilization of both inter-frame and intra-frame information, and it also neglects the potential of optical flow alignment under self-supervised conditions, leading to biased and insufficient denoising outcomes. To this end, we first explore the practicality of optical flow in the self-supervised setting and introduce a SpatioTemporal Blind-spot Network (STBN) for global frame feature utilization. In the temporal domain, we utilize bidirectional blind-spot feature propagation through the proposed blind-spot alignment block to ensure accurate temporal alignment and effectively capture long-range dependencies. In the spatial domain, we introduce the spatial receptive field expansion module, which enhances the receptive field and improves global perception capabilities. Additionally, to reduce the sensitivity of optical flow estimation to noise, we propose an unsupervised optical flow distillation mechanism that refines fine-grained inter-frame interactions during optical flow alignment. Our method demonstrates superior performance across both synthetic and real-world video denoising datasets. The source code is publicly available at https://github.com/ZKCCZ/STBN.
MMGenBench: Evaluating the Limits of LMMs from the Text-to-Image Generation Perspective
Nov 21, 2024
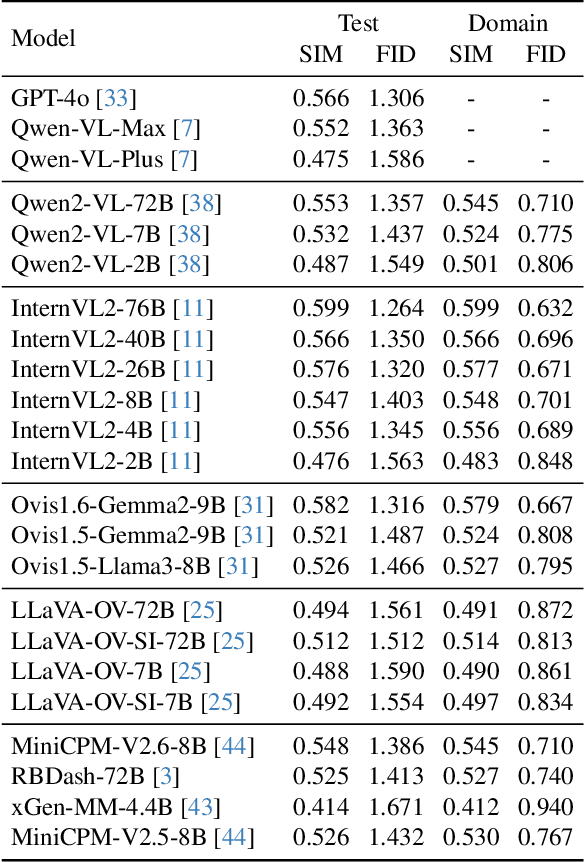
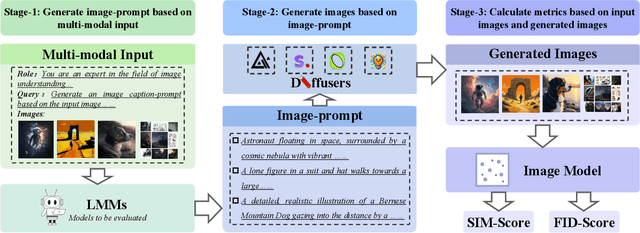
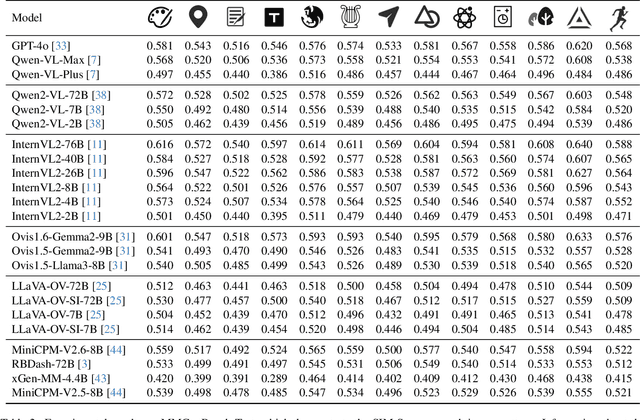
Large Multimodal Models (LMMs) have demonstrated remarkable capabilities. While existing benchmarks for evaluating LMMs mainly focus on image comprehension, few works evaluate them from the image generation perspective. To address this issue, we propose a straightforward automated evaluation pipeline. Specifically, this pipeline requires LMMs to generate an image-prompt from a given input image. Subsequently, it employs text-to-image generative models to create a new image based on these generated prompts. Finally, we evaluate the performance of LMMs by comparing the original image with the generated one. Furthermore, we introduce MMGenBench-Test, a comprehensive benchmark developed to evaluate LMMs across 13 distinct image patterns, and MMGenBench-Domain, targeting the performance evaluation of LMMs within the generative image domain. A thorough evaluation involving over 50 popular LMMs demonstrates the effectiveness and reliability in both the pipeline and benchmark. Our observations indicate that numerous LMMs excelling in existing benchmarks fail to adequately complete the basic tasks, related to image understanding and description. This finding highlights the substantial potential for performance improvement in current LMMs and suggests avenues for future model optimization. Concurrently, our pipeline facilitates the efficient assessment of LMMs performance across diverse domains by using solely image inputs.