 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Scaling Behaviors of Evolutionary Algorithms on GPUs: When Does Parallelism Pay Off?
Jan 27, 2026Evolutionary algorithms (EAs) are increasingly implemented on graphics processing units (GPUs) to leverage parallel processing capabilities for enhanced efficiency. However, existing studies largely emphasize the raw speedup obtained by porting individual algorithms from CPUs to GPUs. Consequently, these studies offer limited insight into when and why GPU parallelism fundamentally benefits EAs. To address this gap, we investigate how GPU parallelism alters the behavior of EAs beyond simple acceleration metrics. We conduct a systematic empirical study of 16 representative EAs on 30 benchmark problems. Specifically, we compare CPU and GPU executions across a wide range of problem dimensionalities and population sizes. Our results reveal that the impact of GPU acceleration is highly heterogeneous and depends strongly on algorithmic structure. We further demonstrate that conventional fixed-budget evaluation based on the number of function evaluations (FEs) is inadequate for GPU execution. In contrast, fixed-time evaluation uncovers performance characteristics that are unobservable under small or practically constrained FE budgets, particularly for adaptive and exploration-oriented algorithms. Moreover, we identify distinct scaling regimes in which GPU parallelism is beneficial, saturates, or degrades as problem dimensionality and population size increase. Crucially, we show that large populations enabled by GPUs not only improve hardware utilization but also reveal algorithm-specific convergence and diversity dynamics that are difficult to observe under CPU-constrained settings. Consequently, our findings indicate that GPU parallelism is not strictly an implementation detail, but a pivotal factor that influences how EAs should be evaluated, compared, and designed for modern computing platforms.
Learning to Decode in Parallel: Self-Coordinating Neural Network for Real-Time Quantum Error Correction
Jan 14, 2026Fast, reliable decoders are pivotal components for enabling fault-tolerant quantum computation (FTQC). Neural network decoders like AlphaQubit have demonstrated potential, achieving higher accuracy than traditional human-designed decoding algorithms. However, existing implementations of neural network decoders lack the parallelism required to decode the syndrome stream generated by a superconducting logical qubit in real time. Moreover, integrating AlphaQubit with sliding window-based parallel decoding schemes presents non-trivial challenges: AlphaQubit is trained solely to output a single bit corresponding to the global logical correction for an entire memory experiment, rather than local physical corrections that can be easily integrated. We address this issue by training a recurrent, transformer-based neural network specifically tailored for parallel window decoding. While it still outputs a single bit, we derive training labels from a consistent set of local corrections and train on various types of decoding windows simultaneously. This approach enables the network to self-coordinate across neighboring windows, facilitating high-accuracy parallel decoding of arbitrarily long memory experiments. As a result, we overcome the throughput bottleneck that previously precluded the use of AlphaQubit-type decoders in FTQC. Our work presents the first scalable, neural-network-based parallel decoding framework that simultaneously achieves SOTA accuracy and the stringent throughput required for real-time quantum error correction. Using an end-to-end experimental workflow, we benchmark our decoder on the Zuchongzhi 3.2 superconducting quantum processor on surface codes with distances up to 7, demonstrating its superior accuracy. Moreover, we demonstrate that, using our approach, a single TPU v6e is capable of decoding surface codes with distances up to 25 within 1us per decoding round.
Heteroscedastic Bayesian Optimization-Based Dynamic PID Tuning for Accurate and Robust UAV Trajectory Tracking
Dec 30, 2025Unmanned Aerial Vehicles (UAVs) play an important role in various applications, where precise trajectory tracking is crucial. However, conventional control algorithms for trajectory tracking often exhibit limited performance due to the underactuated, nonlinear, and highly coupled dynamics of quadrotor systems. To address these challenges, we propose HBO-PID, a novel control algorithm that integrates the Heteroscedastic Bayesian Optimization (HBO) framework with the classical PID controller to achieve accurate and robust trajectory tracking. By explicitly modeling input-dependent noise variance, the proposed method can better adapt to dynamic and complex environments, and therefore improve the accuracy and robustness of trajectory tracking. To accelerate the convergence of optimization, we adopt a two-stage optimization strategy that allow us to more efficiently find the optimal controller parameters. Through experiments in both simulation and real-world scenarios, we demonstrate that the proposed method significantly outperforms state-of-the-art (SOTA) methods. Compared to SOTA methods, it improves the position accuracy by 24.7% to 42.9%, and the angular accuracy by 40.9% to 78.4%.
* Accepted by IROS 2025 (2025 IEEE/RSJ International Conference on Intelligent Robots and Systems)
Multi-agent In-context Coordination via Decentralized Memory Retrieval
Nov 13, 2025



Large transformer models, trained on diverse datasets, have demonstrated impressive few-shot performance on previously unseen tasks without requiring parameter updates. This capability has also been explored in Reinforcement Learning (RL), where agents interact with the environment to retrieve context and maximize cumulative rewards, showcasing strong adaptability in complex settings. However, in cooperative Multi-Agent Reinforcement Learning (MARL), where agents must coordinate toward a shared goal, decentralized policy deployment can lead to mismatches in task alignment and reward assignment, limiting the efficiency of policy adaptation. To address this challenge, we introduce Multi-agent In-context Coordination via Decentralized Memory Retrieval (MAICC), a novel approach designed to enhance coordination by fast adaptation. Our method involves training a centralized embedding model to capture fine-grained trajectory representations, followed by decentralized models that approximate the centralized one to obtain team-level task information. Based on the learned embeddings, relevant trajectories are retrieved as context, which, combined with the agents' current sub-trajectories, inform decision-making. During decentralized execution, we introduce a novel memory mechanism that effectively balances test-time online data with offline memory. Based on the constructed memory, we propose a hybrid utility score that incorporates both individual- and team-level returns, ensuring credit assignment across agents. Extensive experiments on cooperative MARL benchmarks, including Level-Based Foraging (LBF) and SMAC (v1/v2), show that MAICC enables faster adaptation to unseen tasks compared to existing methods. Code is available at https://github.com/LAMDA-RL/MAICC.
MetaboT: AI-based agent for natural language-based interaction with metabolomics knowledge graphs
Oct 02, 2025Mass spectrometry metabolomics generates vast amounts of data requiring advanced methods for interpretation. Knowledge graphs address these challenges by structuring mass spectrometry data, metabolite information, and their relationships into a connected network (Gaudry et al. 2024). However, effective use of a knowledge graph demands an in-depth understanding of its ontology and its query language syntax. To overcome this, we designed MetaboT, an AI system utilizing large language models (LLMs) to translate user questions into SPARQL semantic query language for operating on knowledge graphs (Steve Harris 2013). We demonstrate its effectiveness using the Experimental Natural Products Knowledge Graph (ENPKG), a large-scale public knowledge graph for plant natural products (Gaudry et al. 2024).MetaboT employs specialized AI agents for handling user queries and interacting with the knowledge graph by breaking down complex tasks into discrete components, each managed by a specialised agent (Fig. 1a). The multi-agent system is constructed using the LangChain and LangGraph libraries, which facilitate the integration of LLMs with external tools and information sources (LangChain, n.d.). The query generation process follows a structured workflow. First, the Entry Agent determines if the question is new or a follow-up to previous interactions. New questions are forwarded to the Validator Agent, which verifies if the question is related to the knowledge graph. Then, the valid question is sent to the Supervisor Agent, which identifies if the question requires chemical conversions or standardized identifiers. In this case it delegates the question to the Knowledge Graph Agent, which can use tools to extract necessary details, such as URIs or taxonomies of chemical names, from the user query. Finally, an agent responsible for crafting the SPARQL queries equipped with the ontology of the knowledge graph uses the provided identifiers to generate the query. Then, the system executes the generated query against the metabolomics knowledge graph and returns structured results to the user (Fig. 1b). To assess the performance of MetaboT we have curated 50 metabolomics-related questions and their expected answers. In addition to submitting these questions to MetaboT, we evaluated a baseline by submitting them to a standard LLM (GPT-4o) with a prompt that incorporated the knowledge graph ontology but did not provide specific entity IDs. This baseline achieved only 8.16% accuracy, compared to MetaboT's 83.67%, underscoring the necessity of our multi-agent system for accurately retrieving entities and generating correct SPARQL queries. MetaboT demonstrates promising performance as a conversational question-answering assistant, enabling researchers to retrieve structured metabolomics data through natural language queries. By automating the generation and execution of SPARQL queries, it removes technical barriers that have traditionally hindered access to knowledge graphs. Importantly, MetaboT leverages the capabilities of LLMs while maintaining experimentally grounded query generation, ensuring that outputs remain aligned with domain-specific standards and data structures. This approach facilitates data-driven discoveries by bridging the gap between complex semantic technologies and user-friendly interaction. MetaboT is accessible at [https://metabot.holobiomicslab.eu/], and its source code is available at [https://github.com/HolobiomicsLab/MetaboT].
Measuring and Controlling the Spectral Bias for Self-Supervised Image Denoising
Oct 01, 2025Current self-supervised denoising methods for paired noisy images typically involve mapping one noisy image through the network to the other noisy image. However, after measuring the spectral bias of such methods using our proposed Image Pair Frequency-Band Similarity, it suffers from two practical limitations. Firstly, the high-frequency structural details in images are not preserved well enough. Secondly, during the process of fitting high frequencies, the network learns high-frequency noise from the mapped noisy images. To address these challenges, we introduce a Spectral Controlling network (SCNet) to optimize self-supervised denoising of paired noisy images. First, we propose a selection strategy to choose frequency band components for noisy images, to accelerate the convergence speed of training. Next, we present a parameter optimization method that restricts the learning ability of convolutional kernels to high-frequency noise using the Lipschitz constant, without changing the network structure. Finally, we introduce the Spectral Separation and low-rank Reconstruction module (SSR module), which separates noise and high-frequency details through frequency domain separation and low-rank space reconstruction, to retain the high-frequency structural details of images. Experiments performed on synthetic and real-world datasets verify the effectiveness of SCNet.
Back to Ear: Perceptually Driven High Fidelity Music Reconstruction
Sep 18, 2025Variational Autoencoders (VAEs) are essential for large-scale audio tasks like diffusion-based generation. However, existing open-source models often neglect auditory perceptual aspects during training, leading to weaknesses in phase accuracy and stereophonic spatial representation. To address these challenges, we propose {\epsilon}ar-VAE, an open-source music signal reconstruction model that rethinks and optimizes the VAE training paradigm. Our contributions are threefold: (i) A K-weighting perceptual filter applied prior to loss calculation to align the objective with auditory perception. (ii) Two novel phase losses: a Correlation Loss for stereo coherence, and a Phase Loss using its derivatives--Instantaneous Frequency and Group Delay--for precision. (iii) A new spectral supervision paradigm where magnitude is supervised by all four Mid/Side/Left/Right components, while phase is supervised only by the LR components. Experiments show {\epsilon}ar-VAE at 44.1kHz substantially outperforms leading open-source models across diverse metrics, showing particular strength in reconstructing high-frequency harmonics and the spatial characteristics.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
A Unified RCS Modeling of Typical Targets for 3GPP ISAC Channel Standardization and Experimental Analysis
May 27, 2025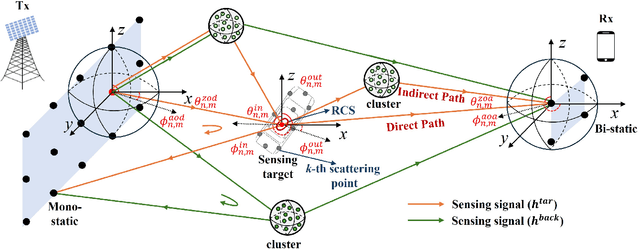
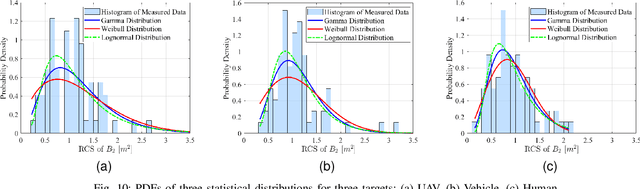
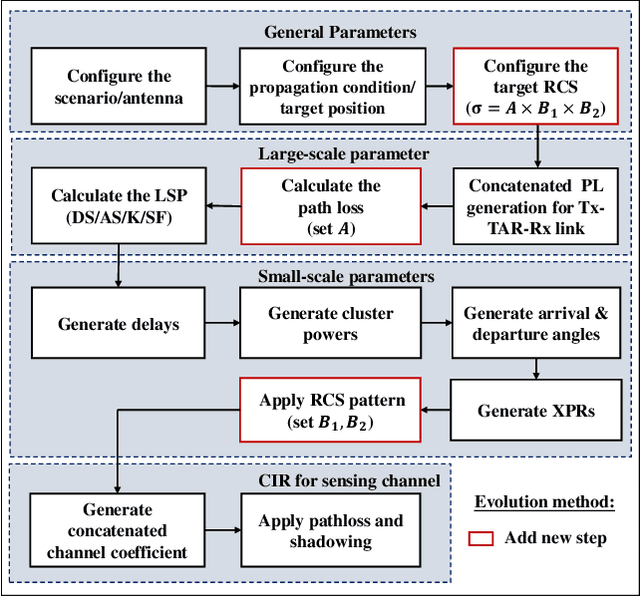
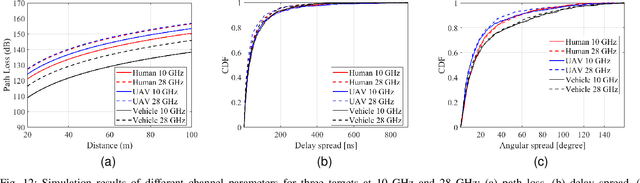
Accurate radar cross section (RCS) modeling is crucial for characterizing target scattering and improving the precision of Integrated Sensing and Communication (ISAC) channel modeling. Existing RCS models are typically designed for specific target types, leading to increased complexity and lack of generalization. This makes it difficult to standardize RCS models for 3GPP ISAC channels, which need to account for multiple typical target types simultaneously. Furthermore, 3GPP models must support both system-level and link-level simulations, requiring the integration of large-scale and small-scale scattering characteristics. To address these challenges, this paper proposes a unified RCS modeling framework that consolidates these two aspects. The model decomposes RCS into three components: (1) a large-scale power factor representing overall scattering strength, (2) a small-scale angular-dependent component describing directional scattering, and (3) a random component accounting for variations across target instances. We validate the model through mono-static RCS measurements for UAV, human, and vehicle targets across five frequency bands. The results demonstrate that the proposed model can effectively capture RCS variations for different target types. Finally, the model is incorporated into an ISAC channel simulation platform to assess the impact of target RCS characteristics on path loss, delay spread, and angular spread, providing valuable insights for future ISAC system design.