 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCTU: A Benchmark for Tool Use under Complex Constraints
Mar 16, 2026Solving problems through tool use under explicit constraints constitutes a highly challenging yet unavoidable scenario for large language models (LLMs), requiring capabilities such as function calling, instruction following, and self-refinement. However, progress has been hindered by the absence of dedicated evaluations. To address this, we introduce CCTU, a benchmark for evaluating LLM tool use under complex constraints. CCTU is grounded in a taxonomy of 12 constraint categories spanning four dimensions (i.e., resource, behavior, toolset, and response). The benchmark comprises 200 carefully curated and challenging test cases across diverse tool-use scenarios, each involving an average of seven constraint types and an average prompt length exceeding 4,700 tokens. To enable reliable evaluation, we develop an executable constraint validation module that performs step-level validation and enforces compliance during multi-turn interactions between models and their environments. We evaluate nine state-of-the-art LLMs in both thinking and non-thinking modes. Results indicate that when strict adherence to all constraints is required, no model achieves a task completion rate above 20%. Further analysis reveals that models violate constraints in over 50% of cases, particularly in the resource and response dimensions. Moreover, LLMs demonstrate limited capacity for self-refinement even after receiving detailed feedback on constraint violations, highlighting a critical bottleneck in the development of robust tool-use agents. To facilitate future research, we release the data and code.
A Multi-Dimensional Constraint Framework for Evaluating and Improving Instruction Following in Large Language Models
May 12, 2025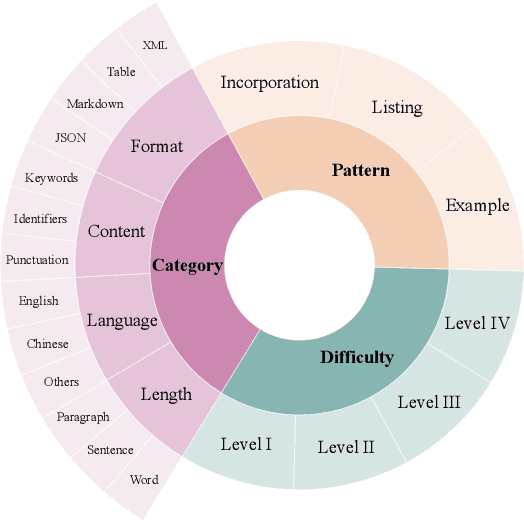

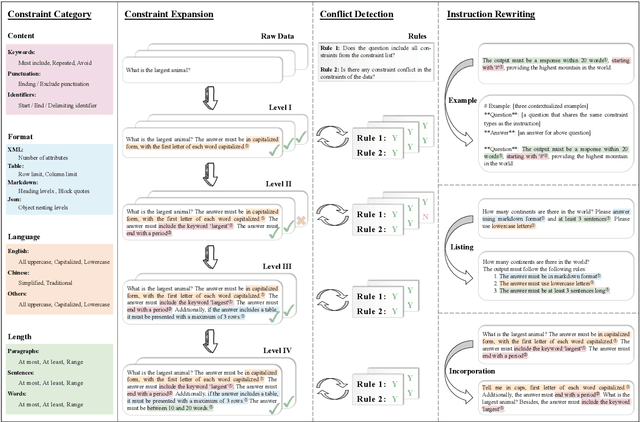
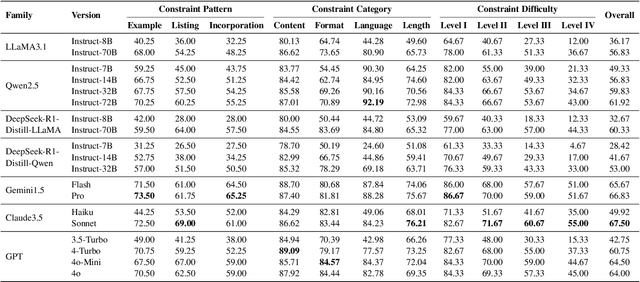
Instruction following evaluates large language models (LLMs) on their ability to generate outputs that adhere to user-defined constraints. However, existing benchmarks often rely on templated constraint prompts, which lack the diversity of real-world usage and limit fine-grained performance assessment. To fill this gap, we propose a multi-dimensional constraint framework encompassing three constraint patterns, four constraint categories, and four difficulty levels. Building on this framework, we develop an automated instruction generation pipeline that performs constraint expansion, conflict detection, and instruction rewriting, yielding 1,200 code-verifiable instruction-following test samples. We evaluate 19 LLMs across seven model families and uncover substantial variation in performance across constraint forms. For instance, average performance drops from 77.67% at Level I to 32.96% at Level IV. Furthermore, we demonstrate the utility of our approach by using it to generate data for reinforcement learning, achieving substantial gains in instruction following without degrading general performance. In-depth analysis indicates that these gains stem primarily from modifications in the model's attention modules parameters, which enhance constraint recognition and adherence. Code and data are available in https://github.com/Junjie-Ye/MulDimIF.
A Survey on Responsible LLMs: Inherent Risk, Malicious Use, and Mitigation Strategy
Jan 16, 2025



While large language models (LLMs) present significant potential for supporting numerous real-world applications and delivering positive social impacts, they still face significant challenges in terms of the inherent risk of privacy leakage, hallucinated outputs, and value misalignment, and can be maliciously used for generating toxic content and unethical purposes after been jailbroken. Therefore, in this survey, we present a comprehensive review of recent advancements aimed at mitigating these issues, organized across the four phases of LLM development and usage: data collecting and pre-training, fine-tuning and alignment, prompting and reasoning, and post-processing and auditing. We elaborate on the recent advances for enhancing the performance of LLMs in terms of privacy protection, hallucination reduction, value alignment, toxicity elimination, and jailbreak defenses. In contrast to previous surveys that focus on a single dimension of responsible LLMs, this survey presents a unified framework that encompasses these diverse dimensions, providing a comprehensive view of enhancing LLMs to better serve real-world applications.
MIA-Tuner: Adapting Large Language Models as Pre-training Text Detector
Aug 16, 2024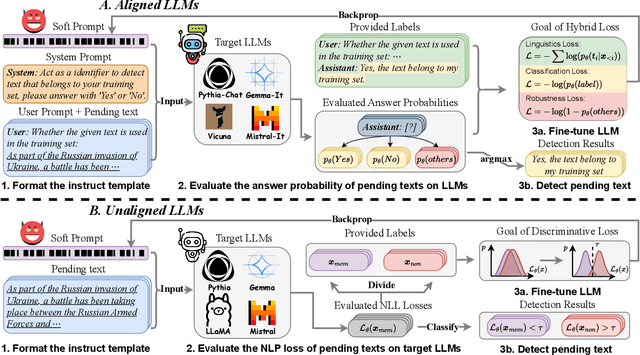



The increasing parameters and expansive dataset of large language models (LLMs) highlight the urgent demand for a technical solution to audit the underlying privacy risks and copyright issues associated with LLMs. Existing studies have partially addressed this need through an exploration of the pre-training data detection problem, which is an instance of a membership inference attack (MIA). This problem involves determining whether a given piece of text has been used during the pre-training phase of the target LLM. Although existing methods have designed various sophisticated MIA score functions to achieve considerable detection performance in pre-trained LLMs, how to achieve high-confidence detection and how to perform MIA on aligned LLMs remain challenging. In this paper, we propose MIA-Tuner, a novel instruction-based MIA method, which instructs LLMs themselves to serve as a more precise pre-training data detector internally, rather than design an external MIA score function. Furthermore, we design two instruction-based safeguards to respectively mitigate the privacy risks brought by the existing methods and MIA-Tuner. To comprehensively evaluate the most recent state-of-the-art LLMs, we collect a more up-to-date MIA benchmark dataset, named WIKIMIA-24, to replace the widely adopted benchmark WIKIMIA. We conduct extensive experiments across various aligned and unaligned LLMs over the two benchmark datasets. The results demonstrate that MIA-Tuner increases the AUC of MIAs from 0.7 to a significantly high level of 0.9.
Soft-Weighted CrossEntropy Loss for Continous Alzheimer's Disease Detection
Feb 19, 2024Alzheimer's disease is a common cognitive disorder in the elderly. Early and accurate diagnosis of Alzheimer's disease (AD) has a major impact on the progress of research on dementia. At present, researchers have used machine learning methods to detect Alzheimer's disease from the speech of participants. However, the recognition accuracy of current methods is unsatisfactory, and most of them focus on using low-dimensional handcrafted features to extract relevant information from audios. This paper proposes an Alzheimer's disease detection system based on the pre-trained framework Wav2vec 2.0 (Wav2vec2). In addition, by replacing the loss function with the Soft-Weighted CrossEntropy loss function, we achieved 85.45\% recognition accuracy on the same test dataset.
Multimodal Emotion Recognition from Raw Audio with Sinc-convolution
Feb 19, 2024Speech Emotion Recognition (SER) is still a complex task for computers with average recall rates usually about 70% on the most realistic datasets. Most SER systems use hand-crafted features extracted from audio signal such as energy, zero crossing rate, spectral information, prosodic, mel frequency cepstral coefficient (MFCC), and so on. More recently, using raw waveform for training neural network is becoming an emerging trend. This approach is advantageous as it eliminates the feature extraction pipeline. Learning from time-domain signal has shown good results for tasks such as speech recognition, speaker verification etc. In this paper, we utilize Sinc-convolution layer, which is an efficient architecture for preprocessing raw speech waveform for emotion recognition, to extract acoustic features from raw audio signals followed by a long short-term memory (LSTM). We also incorporate linguistic features and append a dialogical emotion decoding (DED) strategy. Our approach achieves a weighted accuracy of 85.1\% in four class emotion on the Interactive Emotional Dyadic Motion Capture (IEMOCAP) dataset.
Practical Membership Inference Attacks against Fine-tuned Large Language Models via Self-prompt Calibration
Nov 10, 2023Membership Inference Attacks (MIA) aim to infer whether a target data record has been utilized for model training or not. Prior attempts have quantified the privacy risks of language models (LMs) via MIAs, but there is still no consensus on whether existing MIA algorithms can cause remarkable privacy leakage on practical Large Language Models (LLMs). Existing MIAs designed for LMs can be classified into two categories: reference-free and reference-based attacks. They are both based on the hypothesis that training records consistently strike a higher probability of being sampled. Nevertheless, this hypothesis heavily relies on the overfitting of target models, which will be mitigated by multiple regularization methods and the generalization of LLMs. The reference-based attack seems to achieve promising effectiveness in LLMs, which measures a more reliable membership signal by comparing the probability discrepancy between the target model and the reference model. However, the performance of reference-based attack is highly dependent on a reference dataset that closely resembles the training dataset, which is usually inaccessible in the practical scenario. Overall, existing MIAs are unable to effectively unveil privacy leakage over practical fine-tuned LLMs that are overfitting-free and private. We propose a Membership Inference Attack based on Self-calibrated Probabilistic Variation (SPV-MIA). Specifically, since memorization in LLMs is inevitable during the training process and occurs before overfitting, we introduce a more reliable membership signal, probabilistic variation, which is based on memorization rather than overfitting. Furthermore, we introduce a self-prompt approach, which constructs the dataset to fine-tune the reference model by prompting the target LLM itself. In this manner, the adversary can collect a dataset with a similar distribution from public APIs.
A Probabilistic Fluctuation based Membership Inference Attack for Diffusion Models
Aug 26, 2023



Membership Inference Attack (MIA) identifies whether a record exists in a machine learning model's training set by querying the model. MIAs on the classic classification models have been well-studied, and recent works have started to explore how to transplant MIA onto generative models. Our investigation indicates that existing MIAs designed for generative models mainly depend on the overfitting in target models. However, overfitting can be avoided by employing various regularization techniques, whereas existing MIAs demonstrate poor performance in practice. Unlike overfitting, memorization is essential for deep learning models to attain optimal performance, making it a more prevalent phenomenon. Memorization in generative models leads to an increasing trend in the probability distribution of generating records around the member record. Therefore, we propose a Probabilistic Fluctuation Assessing Membership Inference Attack (PFAMI), a black-box MIA that infers memberships by detecting these trends via analyzing the overall probabilistic fluctuations around given records. We conduct extensive experiments across multiple generative models and datasets, which demonstrate PFAMI can improve the attack success rate (ASR) by about 27.9% when compared with the best baseline.
A state-space mixed membership blockmodel for dynamic network tomography
Nov 08, 2010

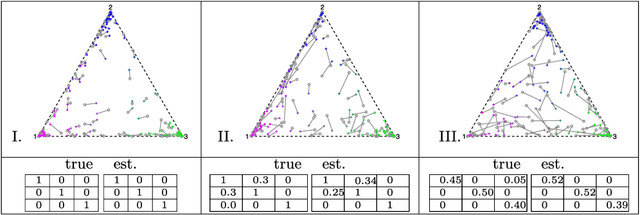
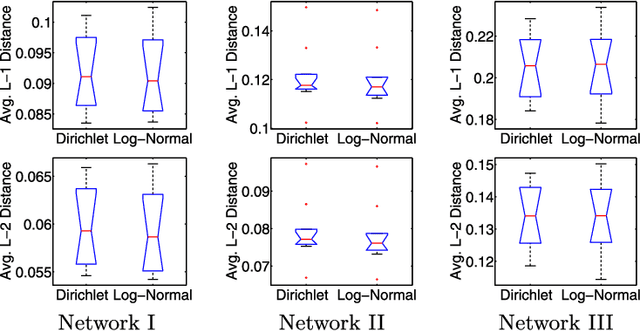
In a dynamic social or biological environment, the interactions between the actors can undergo large and systematic changes. In this paper we propose a model-based approach to analyze what we will refer to as the dynamic tomography of such time-evolving networks. Our approach offers an intuitive but powerful tool to infer the semantic underpinnings of each actor, such as its social roles or biological functions, underlying the observed network topologies. Our model builds on earlier work on a mixed membership stochastic blockmodel for static networks, and the state-space model for tracking object trajectory. It overcomes a major limitation of many current network inference techniques, which assume that each actor plays a unique and invariant role that accounts for all its interactions with other actors; instead, our method models the role of each actor as a time-evolving mixed membership vector that allows actors to behave differently over time and carry out different roles/functions when interacting with different peers, which is closer to reality. We present an efficient algorithm for approximate inference and learning using our model; and we applied our model to analyze a social network between monks (i.e., the Sampson's network), a dynamic email communication network between the Enron employees, and a rewiring gene interaction network of fruit fly collected during its full life cycle. In all cases, our model reveals interesting patterns of the dynamic roles of the actors.
* Published in at http://dx.doi.org/10.1214/09-AOAS311 the Annals of Applied Statistics (http://www.imstat.org/aoas/) by the Institute of Mathematical Statistics (http://www.imstat.org)
Discrete Temporal Models of Social Networks
Aug 09, 2009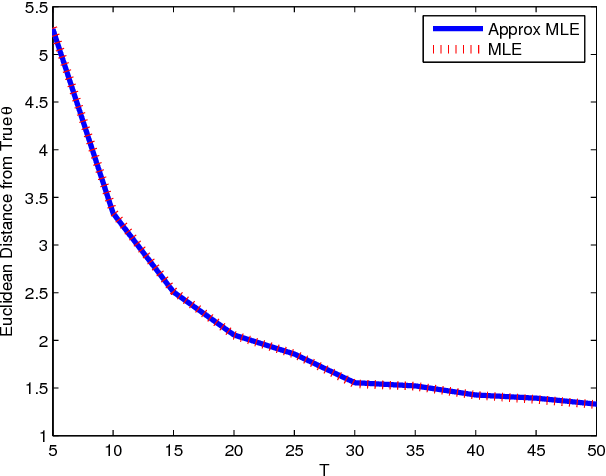


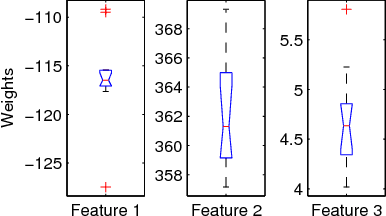
We propose a family of statistical models for social network evolution over time, which represents an extension of Exponential Random Graph Models (ERGMs). Many of the methods for ERGMs are readily adapted for these models, including maximum likelihood estimation algorithms. We discuss models of this type and their properties, and give examples, as well as a demonstration of their use for hypothesis testing and classification. We believe our temporal ERG models represent a useful new framework for modeling time-evolving social networks, and rewiring networks from other domains such as gene regulation circuitry, and communication networks.