 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIA-Tuner: Adapting Large Language Models as Pre-training Text Detector
Aug 16, 2024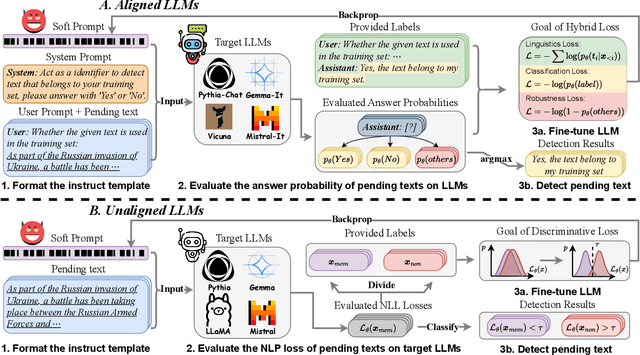



The increasing parameters and expansive dataset of large language models (LLMs) highlight the urgent demand for a technical solution to audit the underlying privacy risks and copyright issues associated with LLMs. Existing studies have partially addressed this need through an exploration of the pre-training data detection problem, which is an instance of a membership inference attack (MIA). This problem involves determining whether a given piece of text has been used during the pre-training phase of the target LLM. Although existing methods have designed various sophisticated MIA score functions to achieve considerable detection performance in pre-trained LLMs, how to achieve high-confidence detection and how to perform MIA on aligned LLMs remain challenging. In this paper, we propose MIA-Tuner, a novel instruction-based MIA method, which instructs LLMs themselves to serve as a more precise pre-training data detector internally, rather than design an external MIA score function. Furthermore, we design two instruction-based safeguards to respectively mitigate the privacy risks brought by the existing methods and MIA-Tuner. To comprehensively evaluate the most recent state-of-the-art LLMs, we collect a more up-to-date MIA benchmark dataset, named WIKIMIA-24, to replace the widely adopted benchmark WIKIMIA. We conduct extensive experiments across various aligned and unaligned LLMs over the two benchmark datasets. The results demonstrate that MIA-Tuner increases the AUC of MIAs from 0.7 to a significantly high level of 0.9.
Practical Membership Inference Attacks against Fine-tuned Large Language Models via Self-prompt Calibration
Nov 10, 2023Membership Inference Attacks (MIA) aim to infer whether a target data record has been utilized for model training or not. Prior attempts have quantified the privacy risks of language models (LMs) via MIAs, but there is still no consensus on whether existing MIA algorithms can cause remarkable privacy leakage on practical Large Language Models (LLMs). Existing MIAs designed for LMs can be classified into two categories: reference-free and reference-based attacks. They are both based on the hypothesis that training records consistently strike a higher probability of being sampled. Nevertheless, this hypothesis heavily relies on the overfitting of target models, which will be mitigated by multiple regularization methods and the generalization of LLMs. The reference-based attack seems to achieve promising effectiveness in LLMs, which measures a more reliable membership signal by comparing the probability discrepancy between the target model and the reference model. However, the performance of reference-based attack is highly dependent on a reference dataset that closely resembles the training dataset, which is usually inaccessible in the practical scenario. Overall, existing MIAs are unable to effectively unveil privacy leakage over practical fine-tuned LLMs that are overfitting-free and private. We propose a Membership Inference Attack based on Self-calibrated Probabilistic Variation (SPV-MIA). Specifically, since memorization in LLMs is inevitable during the training process and occurs before overfitting, we introduce a more reliable membership signal, probabilistic variation, which is based on memorization rather than overfitting. Furthermore, we introduce a self-prompt approach, which constructs the dataset to fine-tune the reference model by prompting the target LLM itself. In this manner, the adversary can collect a dataset with a similar distribution from public APIs.
A Probabilistic Fluctuation based Membership Inference Attack for Diffusion Models
Aug 26, 2023



Membership Inference Attack (MIA) identifies whether a record exists in a machine learning model's training set by querying the model. MIAs on the classic classification models have been well-studied, and recent works have started to explore how to transplant MIA onto generative models. Our investigation indicates that existing MIAs designed for generative models mainly depend on the overfitting in target models. However, overfitting can be avoided by employing various regularization techniques, whereas existing MIAs demonstrate poor performance in practice. Unlike overfitting, memorization is essential for deep learning models to attain optimal performance, making it a more prevalent phenomenon. Memorization in generative models leads to an increasing trend in the probability distribution of generating records around the member record. Therefore, we propose a Probabilistic Fluctuation Assessing Membership Inference Attack (PFAMI), a black-box MIA that infers memberships by detecting these trends via analyzing the overall probabilistic fluctuations around given records. We conduct extensive experiments across multiple generative models and datasets, which demonstrate PFAMI can improve the attack success rate (ASR) by about 27.9% when compared with the best baseline.
An Event Correlation Filtering Method for Fake News Detection
Dec 13, 2020
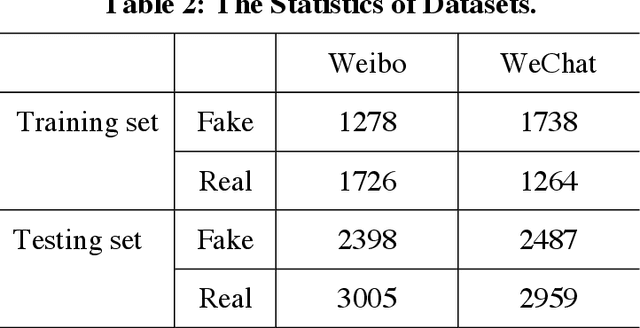
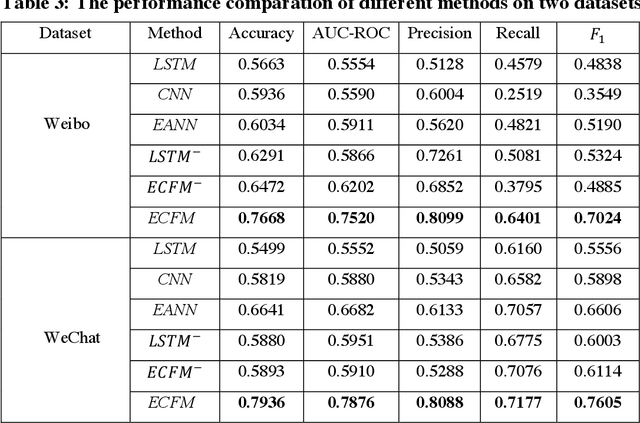
Nowadays, social network platforms have been the prime source for people to experience news and events due to their capacities to spread information rapidly, which inevitably provides a fertile ground for the dissemination of fake news. Thus, it is significant to detect fake news otherwise it could cause public misleading and panic. Existing deep learning models have achieved great progress to tackle the problem of fake news detection. However, training an effective deep learning model usually requires a large amount of labeled news, while it is expensive and time-consuming to provide sufficient labeled news in actual applications. To improve the detection performance of fake news, we take advantage of the event correlations of news and propose an event correlation filtering method (ECFM) for fake news detection, mainly consisting of the news characterizer, the pseudo label annotator, the event credibility updater, and the news entropy selector. The news characterizer is responsible for extracting textual features from news, which cooperates with the pseudo label annotator to assign pseudo labels for unlabeled news by fully exploiting the event correlations of news. In addition, the event credibility updater employs adaptive Kalman filter to weaken the credibility fluctuations of events. To further improve the detection performance, the news entropy selector automatically discovers high-quality samples from pseudo labeled news by quantifying their news entropy. Finally, ECFM is proposed to integrate them to detect fake news in an event correlation filtering manner. Extensive experiments prove that the explainable introduction of the event correlations of news is beneficial to improve the detection performance of fake news.