 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResMAS: Resilience Optimization in LLM-based Multi-agent Systems
Jan 08, 2026Large Language Model-based Multi-Agent Systems (LLM-based MAS), where multiple LLM agents collaborate to solve complex tasks, have shown impressive performance in many areas. However, MAS are typically distributed across different devices or environments, making them vulnerable to perturbations such as agent failures. While existing works have studied the adversarial attacks and corresponding defense strategies, they mainly focus on reactively detecting and mitigating attacks after they occur rather than proactively designing inherently resilient systems. In this work, we study the resilience of LLM-based MAS under perturbations and find that both the communication topology and prompt design significantly influence system resilience. Motivated by these findings, we propose ResMAS: a two-stage framework for enhancing MAS resilience. First, we train a reward model to predict the MAS's resilience, based on which we train a topology generator to automatically design resilient topology for specific tasks through reinforcement learning. Second, we introduce a topology-aware prompt optimization method that refines each agent's prompt based on its connections and interactions with other agents. Extensive experiments across a range of tasks show that our approach substantially improves MAS resilience under various constraints. Moreover, our framework demonstrates strong generalization ability to new tasks and models, highlighting its potential for building resilient MASs.
Controllable LLM Reasoning via Sparse Autoencoder-Based Steering
Jan 07, 2026Large Reasoning Models (LRMs) exhibit human-like cognitive reasoning strategies (e.g. backtracking, cross-verification) during reasoning process, which improves their performance on complex tasks. Currently, reasoning strategies are autonomously selected by LRMs themselves. However, such autonomous selection often produces inefficient or even erroneous reasoning paths. To make reasoning more reliable and flexible, it is important to develop methods for controlling reasoning strategies. Existing methods struggle to control fine-grained reasoning strategies due to conceptual entanglement in LRMs' hidden states. To address this, we leverage Sparse Autoencoders (SAEs) to decompose strategy-entangled hidden states into a disentangled feature space. To identify the few strategy-specific features from the vast pool of SAE features, we propose SAE-Steering, an efficient two-stage feature identification pipeline. SAE-Steering first recalls features that amplify the logits of strategy-specific keywords, filtering out over 99\% of features, and then ranks the remaining features by their control effectiveness. Using the identified strategy-specific features as control vectors, SAE-Steering outperforms existing methods by over 15\% in control effectiveness. Furthermore, controlling reasoning strategies can redirect LRMs from erroneous paths to correct ones, achieving a 7\% absolute accuracy improvement.
AgentExpt: Automating AI Experiment Design with LLM-based Resource Retrieval Agent
Nov 07, 2025

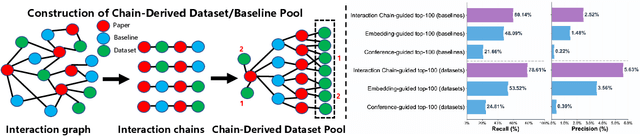
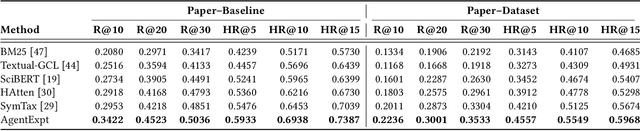
Large language model agents are becoming increasingly capable at web-centric tasks such as information retrieval, complex reasoning. These emerging capabilities have given rise to surge research interests in developing LLM agent for facilitating scientific quest. One key application in AI research is to automate experiment design through agentic dataset and baseline retrieval. However, prior efforts suffer from limited data coverage, as recommendation datasets primarily harvest candidates from public portals and omit many datasets actually used in published papers, and from an overreliance on content similarity that biases model toward superficial similarity and overlooks experimental suitability. Harnessing collective perception embedded in the baseline and dataset citation network, we present a comprehensive framework for baseline and dataset recommendation. First, we design an automated data-collection pipeline that links roughly one hundred thousand accepted papers to the baselines and datasets they actually used. Second, we propose a collective perception enhanced retriever. To represent the position of each dataset or baseline within the scholarly network, it concatenates self-descriptions with aggregated citation contexts. To achieve efficient candidate recall, we finetune an embedding model on these representations. Finally, we develop a reasoning-augmented reranker that exact interaction chains to construct explicit reasoning chains and finetunes a large language model to produce interpretable justifications and refined rankings. The dataset we curated covers 85\% of the datasets and baselines used at top AI conferences over the past five years. On our dataset, the proposed method outperforms the strongest prior baseline with average gains of +5.85\% in Recall@20, +8.30\% in HitRate@5. Taken together, our results advance reliable, interpretable automation of experimental design.
Diffuse Thinking: Exploring Diffusion Language Models as Efficient Thought Proposers for Reasoning
Oct 31, 2025In recent years, large language models (LLMs) have witnessed remarkable advancements, with the test-time scaling law consistently enhancing the reasoning capabilities. Through systematic evaluation and exploration of a diverse spectrum of intermediate thoughts, LLMs demonstrate the potential to generate deliberate reasoning steps, thereby substantially enhancing reasoning accuracy. However, LLMs' autoregressive generation paradigm results in reasoning performance scaling sub-optimally with test-time computation, often requiring excessive computational overhead to propose thoughts while yielding only marginal performance gains. In contrast, diffusion language models (DLMs) can efficiently produce diverse samples through parallel denoising in a single forward pass, inspiring us to leverage them for proposing intermediate thoughts, thereby alleviating the computational burden associated with autoregressive generation while maintaining quality. In this work, we propose an efficient collaborative reasoning framework, leveraging DLMs to generate candidate thoughts and LLMs to evaluate their quality. Experiments across diverse benchmarks demonstrate that our framework achieves strong performance in complex reasoning tasks, offering a promising direction for future research. Our code is open-source at https://anonymous.4open.science/r/Diffuse-Thinking-EC60.
Rationality Check! Benchmarking the Rationality of Large Language Models
Sep 18, 2025Large language models (LLMs), a recent advance in deep learning and machine intelligence, have manifested astonishing capacities, now considered among the most promising for artificial general intelligence. With human-like capabilities, LLMs have been used to simulate humans and serve as AI assistants across many applications. As a result, great concern has arisen about whether and under what circumstances LLMs think and behave like real human agents. Rationality is among the most important concepts in assessing human behavior, both in thinking (i.e., theoretical rationality) and in taking action (i.e., practical rationality). In this work, we propose the first benchmark for evaluating the omnibus rationality of LLMs, covering a wide range of domains and LLMs. The benchmark includes an easy-to-use toolkit, extensive experimental results, and analysis that illuminates where LLMs converge and diverge from idealized human rationality. We believe the benchmark can serve as a foundational tool for both developers and users of LLMs.
CrimeMind: Simulating Urban Crime with Multi-Modal LLM Agents
Jun 06, 2025Modeling urban crime is an important yet challenging task that requires understanding the subtle visual, social, and cultural cues embedded in urban environments. Previous work has predominantly focused on rule-based agent-based modeling (ABM) and deep learning methods. ABMs offer interpretability of internal mechanisms but exhibit limited predictive accuracy.In contrast, deep learning methods are often effective in prediction but are less interpretable and require extensive training data. Moreover, both lines of work lack the cognitive flexibility to adapt to changing environments. Leveraging the capabilities of large language models (LLMs), we propose CrimeMind, a novel LLM-driven ABM framework for simulating urban crime within a multi-modal urban context.A key innovation of our design is the integration of the Routine Activity Theory (RAT) into the agentic workflow of CrimeMind, enabling it to process rich multi-modal urban features and reason about criminal behavior.However, RAT requires LLM agents to infer subtle cues in evaluating environmental safety as part of assessing guardianship, which can be challenging for LLMs. To address this, we collect a small-scale human-annotated dataset and align CrimeMind's perception with human judgment via a training-free textual gradient method.Experiments across four major U.S. cities demonstrate that CrimeMind outperforms both traditional ABMs and deep learning baselines in crime hotspot prediction and spatial distribution accuracy, achieving up to a 24% improvement over the strongest baseline.Furthermore, we conduct counterfactual simulations of external incidents and policy interventions and it successfully captures the expected changes in crime patterns, demonstrating its ability to reflect counterfactual scenarios.Overall, CrimeMind enables fine-grained modeling of individual behaviors and facilitates evaluation of real-world interventions.
Token Signature: Predicting Chain-of-Thought Gains with Token Decoding Feature in Large Language Models
Jun 06, 2025Chain-of-Thought (CoT) technique has proven effective in improving the performance of large language models (LLMs) on complex reasoning tasks. However, the performance gains are inconsistent across different tasks, and the underlying mechanism remains a long-standing research question. In this work, we make a preliminary observation that the monotonicity of token probability distributions may be correlated with the gains achieved through CoT reasoning. Leveraging this insight, we propose two indicators based on the token probability distribution to assess CoT effectiveness across different tasks. By combining instance-level indicators with logistic regression model, we introduce Dynamic CoT, a method that dynamically select between CoT and direct answer. Furthermore, we extend Dynamic CoT to closed-source models by transferring decision strategies learned from open-source models. Our indicators for assessing CoT effectiveness achieve an accuracy of 89.2\%, and Dynamic CoT reduces token consumption by more than 35\% while maintaining high accuracy. Overall, our work offers a novel perspective on the underlying mechanisms of CoT reasoning and provides a framework for its more efficient deployment.
AgentSwift: Efficient LLM Agent Design via Value-guided Hierarchical Search
Jun 06, 2025Large language model (LLM) agents have demonstrated strong capabilities across diverse domains. However, designing high-performing agentic systems remains challenging. Existing agent search methods suffer from three major limitations: (1) an emphasis on optimizing agentic workflows while under-utilizing proven human-designed components such as memory, planning, and tool use; (2) high evaluation costs, as each newly generated agent must be fully evaluated on benchmarks; and (3) inefficient search in large search space. In this work, we introduce a comprehensive framework to address these challenges. First, We propose a hierarchical search space that jointly models agentic workflow and composable functional components, enabling richer agentic system designs. Building on this structured design space, we introduce a predictive value model that estimates agent performance given agentic system and task description, allowing for efficient, low-cost evaluation during the search process. Finally, we present a hierarchical Monte Carlo Tree Search (MCTS) strategy informed by uncertainty to guide the search. Experiments on seven benchmarks, covering embodied, math, web, tool, and game, show that our method achieves an average performance gain of 8.34\% over state-of-the-art baselines and exhibits faster search progress with steeper improvement trajectories. Code repo is available at https://github.com/Ericccc02/AgentSwift.
Route-and-Reason: Scaling Large Language Model Reasoning with Reinforced Model Router
Jun 06, 2025Multi-step reasoning has proven essential for enhancing the problem-solving capabilities of Large Language Models (LLMs) by decomposing complex tasks into intermediate steps, either explicitly or implicitly. Extending the reasoning chain at test time through deeper thought processes or broader exploration, can furthur improve performance, but often incurs substantial costs due to the explosion in token usage. Yet, many reasoning steps are relatively simple and can be handled by more efficient smaller-scale language models (SLMs). This motivates hybrid approaches that allocate subtasks across models of varying capacities. However, realizing such collaboration requires accurate task decomposition and difficulty-aware subtask allocation, which is challenging. To address this, we propose R2-Reasoner, a novel framework that enables collaborative reasoning across heterogeneous LLMs by dynamically routing sub-tasks based on estimated complexity. At the core of our framework is a Reinforced Model Router, composed of a task decomposer and a subtask allocator. The task decomposer segments complex input queries into logically ordered subtasks, while the subtask allocator assigns each subtask to the most appropriate model, ranging from lightweight SLMs to powerful LLMs, balancing accuracy and efficiency. To train this router, we introduce a staged pipeline that combines supervised fine-tuning on task-specific datasets with Group Relative Policy Optimization algorithm, enabling self-supervised refinement through iterative reinforcement learning. Extensive experiments across four challenging benchmarks demonstrate that R2-Reasoner reduces API costs by 86.85% while maintaining or surpassing baseline accuracy. Our framework paves the way for more cost-effective and adaptive LLM reasoning. The code is open-source at https://anonymous.4open.science/r/R2_Reasoner .
Reason-to-Recommend: Using Interaction-of-Thought Reasoning to Enhance LLM Recommendation
Jun 05, 2025Driven by advances in Large Language Models (LLMs), integrating them into recommendation tasks has gained interest due to their strong semantic understanding and prompt flexibility. Prior work encoded user-item interactions or metadata into prompts for recommendations. In parallel, LLM reasoning, boosted by test-time scaling and reinforcement learning, has excelled in fields like mathematics and code, where reasoning traces and correctness signals are clear, enabling high performance and interpretability. However, directly applying these reasoning methods to recommendation is ineffective because user feedback is implicit and lacks reasoning supervision. To address this, we propose $\textbf{R2Rec}$, a reasoning-enhanced recommendation framework that samples interaction chains from the user-item graph and converts them into structured interaction-of-thoughts via a progressive masked prompting strategy, with each thought representing stepwise reasoning grounded in interaction context. This allows LLMs to simulate step-by-step decision-making based on implicit patterns. We design a two-stage training pipeline: supervised fine-tuning teaches basic reasoning from high-quality traces, and reinforcement learning refines reasoning via reward signals, alleviating sparse explicit supervision. Experiments on three real-world datasets show R2Rec outperforms classical and LLM-based baselines with an average $\textbf{10.48%}$ improvement in HitRatio@1 and $\textbf{131.81%}$ gain over the original LLM. Furthermore, the explicit reasoning chains enhance interpretability by revealing the decision process. Our code is available at: https://anonymous.4open.science/r/R2Rec-7C5D.